PokerHandPrediction is a simple TensorFlow ML Agent that takes 5 playing cards, the two cards dealt and the three community cards on flop, that would be present while playing poker. Then it must predict the final hand you will have after the turn and river, which is a 5-card hand from 7 available cards. I originally created this machine learning agent for my Machine Learning course at Southern New Hampshire University.
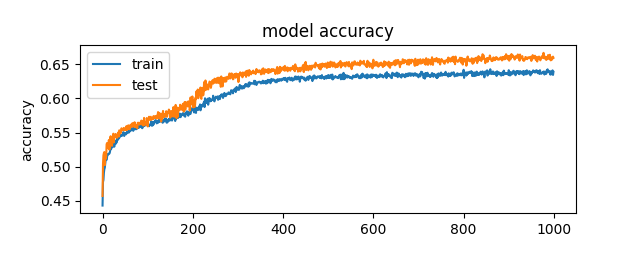
And as you can see in the figure below, I was able to improve the accuracy to about 65%.
When I originally created this machine learning agent, I was using a 980 Ti as my graphics card and had setup TensorFlow with that gpu configured, in the first week of this course I was waiting on the delivery of a 3070 gpu to replace my fried 980. And as it turns out, the CUDA Toolkit seems to have some problems setting up for the 3070. Thankfully, I do have a strong cpu with plenty of cores to throw at the computing.
The first thing I did was get a benchmark of the original neural network so I could ensure I had something to compare against to find a higher success rate.
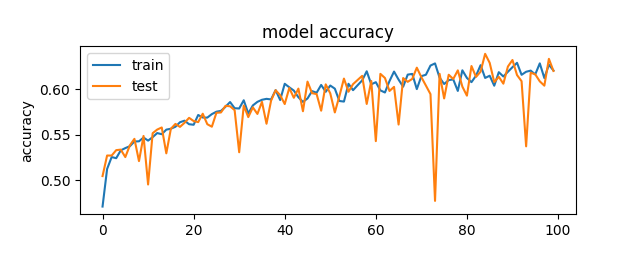
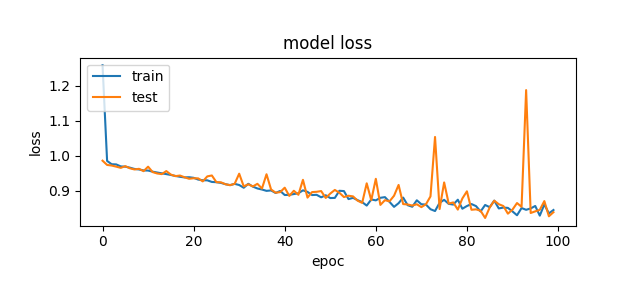
Now what is important to note here is that even though this is 60% accuracy, I realized that I wasn’t actually setting up the model and score correctly.
history = model.fit(drop_train, hand_train, epochs=100, batch_size=256, verbose=1,
validation_data=(drop_test, hand_test), shuffle=True)Should have been
history = model.fit(drop_train, train, epochs=1000, batch_size=256, verbose=1,
validation_data=(drop_test, test), shuffle=True)And the same mistake was made on my model evaluation score. The actual success rate of that original agent was only around 43%. I did not notice that mistake until I was already well into refactoring and adjusting the code.
I believed that I was probably using the wrong type of loss function with Sparse Categorical Crossentroy and wanted to try using a more standard Binary Crossentropy, as it was either pass or fail trailing. This had some success, but ultimately not enough. I then started to look to my optimizer; I was using an SGD optimizer with default learning rate and a bit of applied momentum. I did some research on different keras optimizers and it seemed an almost always good bet would be the Adam optimizer. So I decided to put that in there and see what would happen. I tried with a few different neural network setups until I got this.
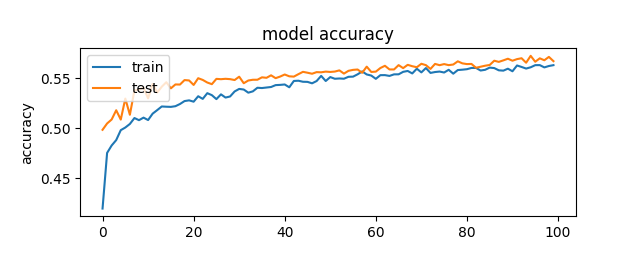
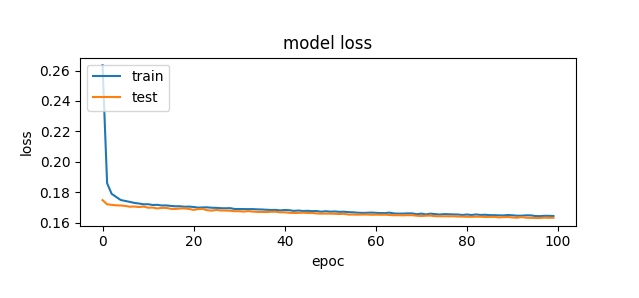
Now what I want to note here is that even though that accuracy was only somewhat above 55%, the model loss was consistent and was not dropping to zero after 100 epochs but was still slowly gaining more accuracy. I decided to try a higher number of epochs, 1000 to be exact.

1000 epochs worked! My model had got a tad over 65% on the testing data. I wondered if it could continue to improve if it had an even higher epoch. Now I am aware of overtuning and expected it would, but I set it to 3000 epochs and would scroll through later to see where in the training did overtuning occur. However, this was weird, it never achieved higher than 61%, with more epochs it never even reaches the same level of accuracy as the 1000 epoch of the exact same neural network. I will need to do more research into why this occurs, but now I have hit my peak.