This repository provides a minimalist implementation of a Multi-Layer Perceptron (MLP) written in C. It is designed to demonstrate the core mechanics of neural networks, including forward propagation and backpropagation, without the overhead of external libraries.
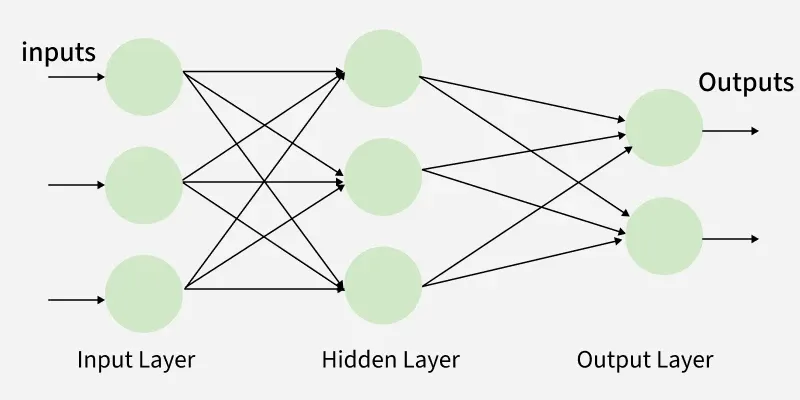
"Multi-Layer Perceptron (MLP) consists of fully connected dense layers that transform input data from one dimension to another. It is called multi-layer because it contains an input layer, one or more hidden layers and an output layer. The purpose of an MLP is to model complex relationships between inputs and outputs." geeksforgeeks
The goal of this project is to provide a transparent look at how neural networks function at a low level. By using only the C standard library, the code highlights the mathematical operations required for training and inference.
- Customizable Architecture: Support for multiple hidden layers with varying numbers of neurons.
- Activation Functions:
- Sigmoid
- LeakyRelu
- Linear
- Softmax
- Loss Functions:
- Categorical cross entropy
- Mean Squared Error (MSE)
- Stochastic Training: Implementation of basic gradient descent.
- Checkpointing: Automatically save best model during training (the one with the lowest validation loss)
- Save & Load Weights: Save trained weights of any model and load them afterwards to start inference right away
- Minimal Dependencies: Requires only stdio.h, stdlib.h, time.h, math.h, arpa/inet.h (for endian swapping only).
The network uses the LeakyRelu function as the activation for all hidden layers, defined as:
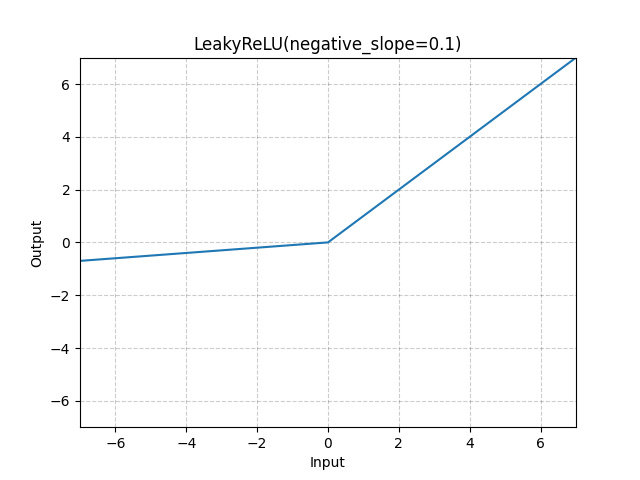
With its derivative being:
With
To facilitate learning through backpropagation, the derivative of the function is utilized during the weight update phase.
As we are doing classification in the example provided in main.c, the activation function of the output layer is the Softmax function, defined as:
where
- https://www.geeksforgeeks.org/deep-learning/multi-layer-perceptron-learning-in-tensorflow/
- For data structures, formulas etc
- Materials from previous courses
- Theory, perceptron+mlp pseudocode
- https://www.geeksforgeeks.org/machine-learning/backpropagation-in-neural-network/
- Backprop
The provided main.c contains a model trained to classify written digits from 0 to 9 to their correct label.

Data Normalization: To prevent neuron saturation and ensure efficient learning, the value of each pixel from the input image is normalized to a range in
One Hot Encoding: Since we want to predict the class we won't output the label directly. We instead output a probability distribution (with the softmax function) of the input belonging to a label. So each label is converted in a probability vector like so:
| Label | One Hot Encoded |
|---|---|
| 0 | [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] |
| 1 | [0, 1, 0, 0, 0, 0, 0, 0, 0, 0] |
| 2 | [0, 0, 1, 0, 0, 0, 0, 0, 0, 0] |
| 3 | [0, 0, 0, 1, 0, 0, 0, 0, 0, 0] |
| 4 | [0, 0, 0, 0, 1, 0, 0, 0, 0, 0] |
| 5 | [0, 0, 0, 0, 0, 1, 0, 0, 0, 0] |
| ... | ... |
Model Configuration:
- Input layer: 256 neurons -> relu
- First hidden layer: 128 neurons -> relu
- Second hidden layer: 64 neurons -> relu
- Output Layer: 10 neurons (= 10 classes) -> softmax.
env $(grep -v '^#' .env | xargs) ./main 12 0.01
Layer 0: Neurons: 256 | Parameters: 784
Layer 1: Neurons: 128 | Parameters: 256
Layer 2: Neurons: 64 | Parameters: 128
Layer 3: Neurons: 10 | Parameters: 64
Total number of parameters: 242762
--- Training model ---
Epoch: 1 - Loss: 0.5377525649 - Validation loss: 0.2354593432
Average loss is lower than last best, saving new best model...
Model saved to: /Users/remi/Documents/dev/c-mlp/model.weights
Epoch: 2 - Loss: 0.1875707645 - Validation loss: 0.1613157459
Average loss is lower than last best, saving new best model...
Model saved to: /Users/remi/Documents/dev/c-mlp/model.weights
Epoch: 3 - Loss: 0.1295952292 - Validation loss: 0.1250332068
Average loss is lower than last best, saving new best model...
Model saved to: /Users/remi/Documents/dev/c-mlp/model.weights
Epoch: 4 - Loss: 0.0970815318 - Validation loss: 0.1064396590
Average loss is lower than last best, saving new best model...
Model saved to: /Users/remi/Documents/dev/c-mlp/model.weights
Epoch: 5 - Loss: 0.0759000559 - Validation loss: 0.0978767503
Average loss is lower than last best, saving new best model...
Model saved to: /Users/remi/Documents/dev/c-mlp/model.weights
Epoch: 6 - Loss: 0.0609901835 - Validation loss: 0.0925132303
Average loss is lower than last best, saving new best model...
Model saved to: /Users/remi/Documents/dev/c-mlp/model.weights
Epoch: 7 - Loss: 0.0496431870 - Validation loss: 0.0886218753
Average loss is lower than last best, saving new best model...
Model saved to: /Users/remi/Documents/dev/c-mlp/model.weights
Epoch: 8 - Loss: 0.0405638559 - Validation loss: 0.0867092326
Average loss is lower than last best, saving new best model...
Model saved to: /Users/remi/Documents/dev/c-mlp/model.weights
Epoch: 9 - Loss: 0.0331091426 - Validation loss: 0.0864263095
Average loss is lower than last best, saving new best model...
Model saved to: /Users/remi/Documents/dev/c-mlp/model.weights
Epoch: 10 - Loss: 0.0265073151 - Validation loss: 0.0889713755
Epoch: 11 - Loss: 0.0210336257 - Validation loss: 0.0882901016
Epoch: 12 - Loss: 0.0166078442 - Validation loss: 0.0881564415
Epoch: 13 - Loss: 0.0129371717 - Validation loss: 0.0875779472
[...]
Epoch: 27 - Loss: 0.0008680156 - Validation loss: 0.0938749218
Epoch: 28 - Loss: 0.0007863892 - Validation loss: 0.0943036234
Epoch: 29 - Loss: 0.0007179017 - Validation loss: 0.0948248200
Epoch: 30 - Loss: 0.0006590907 - Validation loss: 0.0952363930
Epoch: 31 - Loss: 0.0006094295 - Validation loss: 0.0958026959
Epoch: 32 - Loss: 0.0005653673 - Validation loss: 0.0961912048
--- End ---
Successfully loaded model !
Layer 0: Neurons: 256 | Parameters: 784
Layer 1: Neurons: 128 | Parameters: 256
Layer 2: Neurons: 64 | Parameters: 128
Layer 3: Neurons: 10 | Parameters: 64
Total number of parameters: 242762
--- Results ---
Output: 7 | Actual: 7
Output: 6 | Actual: 6
Output: 3 | Actual: 3
Output: 4 | Actual: 4
Output: 2 | Actual: 2
Output: 3 | Actual: 3
Output: 6 | Actual: 6
Output: 1 | Actual: 1
Output: 8 | Actual: 8
Output: 1 | Actual: 1
Output: 9 | Actual: 9
[...]
Output: 3 | Actual: 3
Output: 1 | Actual: 1
Output: 7 | Actual: 7
Output: 5 | Actual: 5
Output: 2 | Actual: 2
Output: 5 | Actual: 5
Output: 2 | Actual: 2
Output: 0 | Actual: 0
Output: 8 | Actual: 8
Average loss: 0.0864263095