
Deep learning speech recognition model for Amharic, and potentially other Ethiopian languages too.
The best documentation so far is Deep Learning for Amharic speech recognition. Here is an overview.
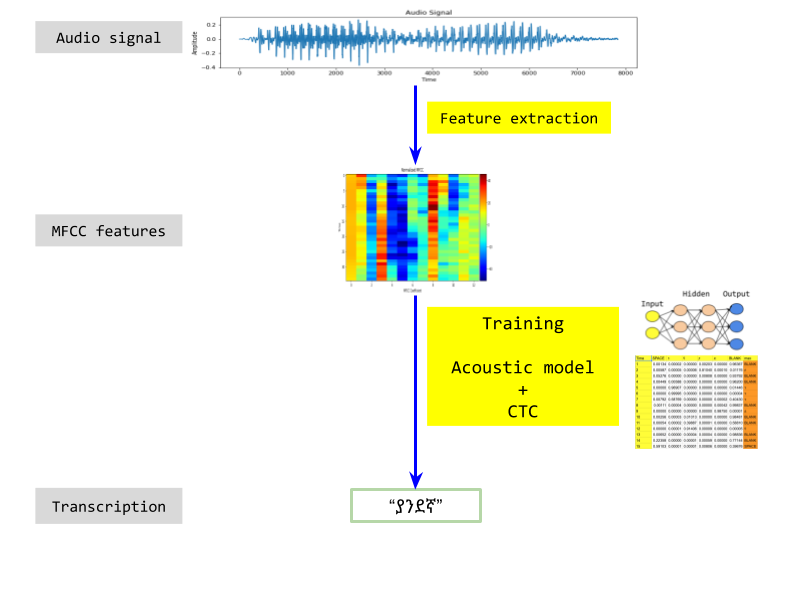
To get an idea of how models are setup and investigated, take a look at the notebooks for Model 1 and Model 2.
If you are interested in running or updating any of the source code, you need a host with Python, Tensorflow, Keras and librosa, Jupyter. A docker image is available with all pre-requisites installed. Here is how you use it
git clone git@github.com:tilayealemu/MelaNet
cd MelaNet/docker
docker-compose up
This should start Jupyter server on port 8888. Go to http://localhost:8888 to connect to it. I strongly recommend you use the docker approach as you can waste quite a lot of time installing packages on your own computer.
You need data if you want to train your own models. It's 1.2 GB when compressed, and 2.3 GB uncompressed. Download it from MelaNetData and copy it to your clone of this repo like so:
git clone git@github.com:tilayealemu/MelaNetData
cd MelaNetData/data
cat data.tar.gz.* > data.tar.gz
tar xzf data.tar.gz
mv -r data/* <path-to-MelaNet>/data
You should now have all .wav files and transcriptions.
├── docker docker files
├── models pre-trained models
├── src python source files
├── *.ipynb Jupyter notebooks for visualization and experimentation
If you face any issues please raise a ticket.