


![]()

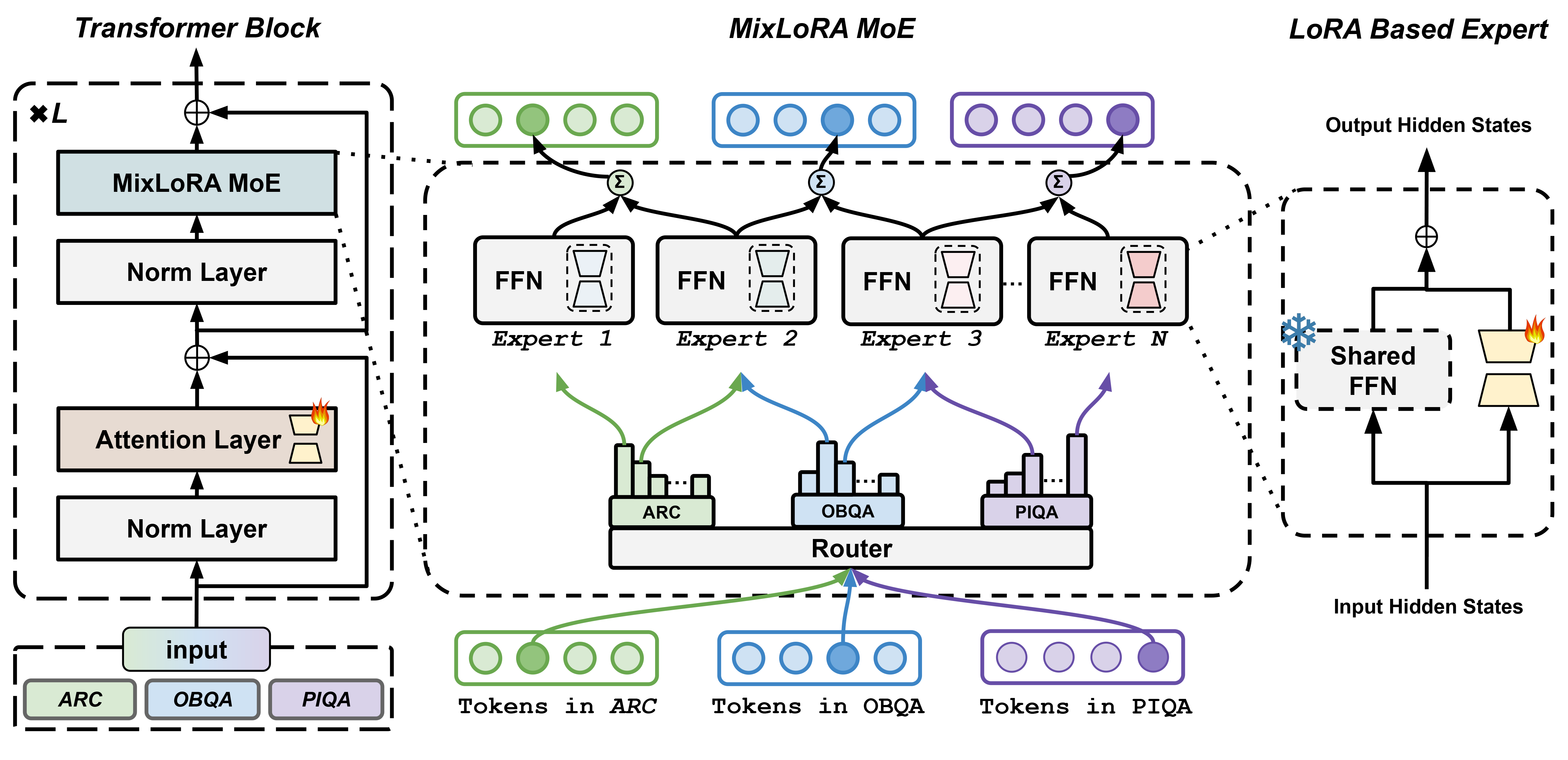
Fine-tuning Large Language Models (LLMs) is a common practice to adapt pre-trained models for specific applications. While methods like LoRA have effectively addressed GPU memory constraints during fine-tuning, their performance often falls short, especially in multi-task scenarios. In contrast, Mixture-of-Expert (MoE) models, such as Mixtral 8x7B, demonstrate remarkable performance in multi-task learning scenarios while maintaining a reduced parameter count. However, the resource requirements of these MoEs remain challenging, particularly for consumer-grade GPUs with less than 24GB memory. To tackle these challenges, we propose MixLoRA, an approach to construct a resource-efficient sparse MoE model based on LoRA. The figure above shows the architecture of the MixLoRA transformer block. MixLoRA inserts multiple LoRA-based experts within the feed-forward network block of a frozen pre-trained dense model and employs a commonly used top-k router. Unlike other LoRA-based MoE methods, MixLoRA enhances model performance by utilizing independent attention-layer LoRA adapters. Additionally, an auxiliary load balance loss is employed to address the imbalance problem of the router. Our evaluations show that MixLoRA improves about 9% accuracy compared to state-of-the-art PEFT methods in multi-task learning scenarios.
| PEFT Method | # Params (%) | ARC-e | ARC-c | BoolQ | OBQA | PIQA | SIQA | HellaS | WinoG | AVG. |
|---|---|---|---|---|---|---|---|---|---|---|
| LoRA | 2.9% | 73.8 | 50.9 | 62.2 | 80.4 | 82.1 | 69.9 | 88.4 | 66.8 | 71.8 |
| DoRA | 2.9% | 76.5 | 59.8 | 71.7 | 80.6 | 82.7 | 74.1 | 89.6 | 67.3 | 75.3 |
| MixLoRA | 2.9% | 77.7 | 58.1 | 72.7 | 81.6 | 83.2 | 78.0 | 93.1 | 76.8 | 77.6 |
| MixDoRA | 2.9% | 77.5 | 58.2 | 72.6 | 80.9 | 82.2 | 80.4 | 90.6 | 83.4 | 78.2 |
The table above presents the performance of MixLoRA and compares these results with outcomes obtained by employing LoRA and DoRA for fine-tuning. The results demonstrate that the language model with MixLoRA achieves commendable performance across all evaluation methods. All methods are fine-tuned and evaluated with meta-llama/Llama-2-7b-hf on MoE-PEFT, with all metrics reported as accuracy.
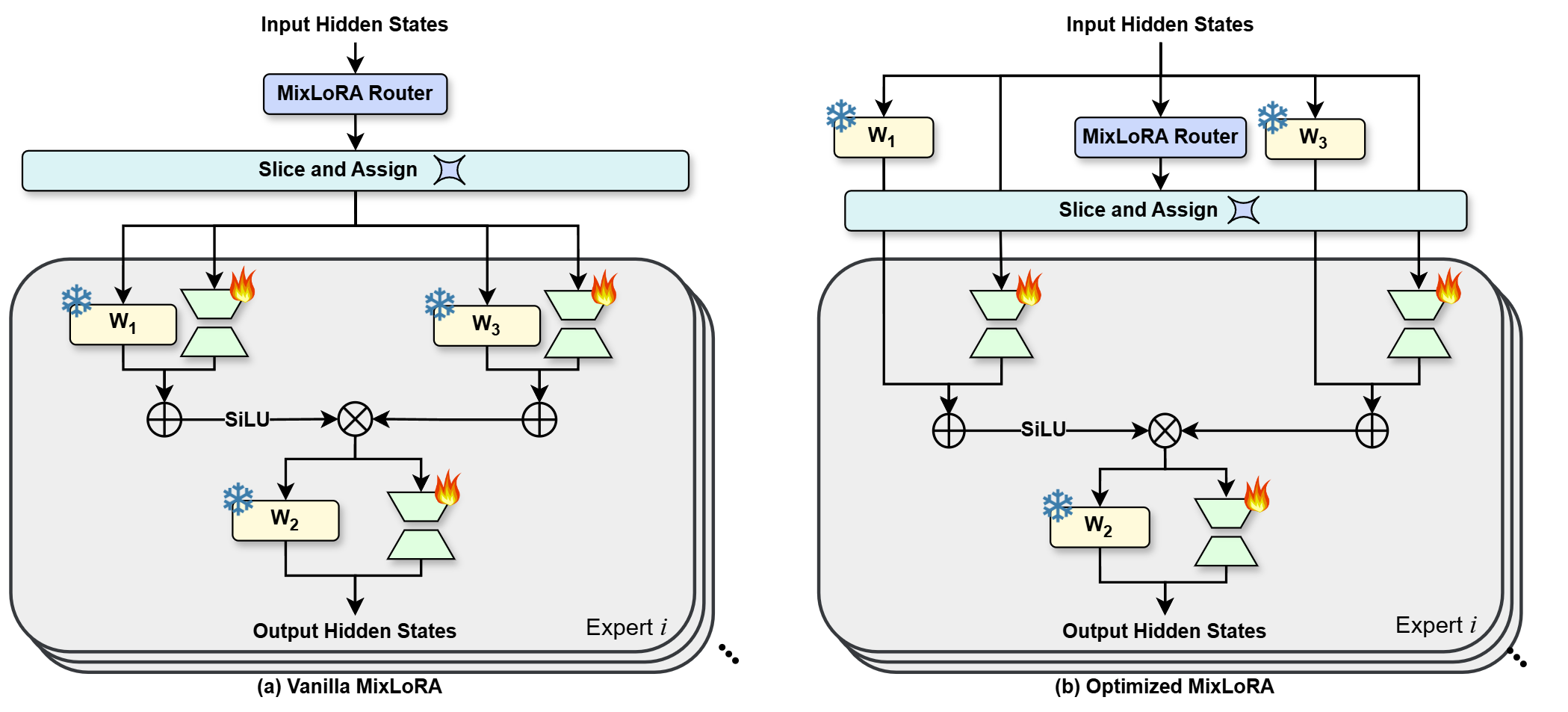
We also propose a new high-throughput framework to alleviate the computation and memory bottlenecks during the training and inference of MoE models. The figure above shows the comparison of the forward propagation processes: (a) the process in a vanilla MixLoRA MoE block; (b) the optimized process that shares computation results of
You can check the full experimental results, including other pre-trained models such as Gemma 2B, LLaMA3 8B, and LLaMA2 13B, and detailed performance metrics in our preprint paper: Li D, Ma Y, Wang N, et al. MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA based Mixture of Experts[J]. arXiv preprint arXiv:2404.15159, 2024.
You can download the weights of MixLoRA fine-tuned with meta-llama/Llama-2-7b-hf and the AlpacaCleaned dataset on Hugging Face: TUDB-Labs/alpaca-mixlora-7b.
MixLoRA is built upon the MoE-PEFT framework. It is recommended to use MixLoRA with MoE-PEFT.
We also provides the integrations of MixLoRA with HuggingFace Transformers for inference. To use it, you can install mixlora with following command:
pip3 install mixloraThen you can load MixLoRA adapter into a pre-trained model with following codes:
from mixlora import MixLoraModelForCausalLM
from transformers import AutoTokenizer
model, config = MixLoraModelForCausalLM.from_pretrained(name_or_path_to_the_adapter, ...)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)You can reproduce our evaluation results with MoE-PEFT v1.0.1 using the following scripts. You can also use the latest release of MoE-PEFT for more features such as new pre-trained model support and bugfix.
Please note that, Single-Task setup refers to training and evaluating PEFT modules for each task, while Multi-Task setup refers to training on mixed tasks, followed by separate evaluation.
We conducted our experiments with the following environment:
- Systems with x86-64 CPUs
- NVIDIA GPUs: RTX 3090@24GB, RTX A5000@24GB, RTX 4090D@24GB, RTX 4090@24GB, RTX A6000@48GB (for 8B and 13B models)
git clone https://github.com/TUDB-Labs/MoE-PEFT
# Optional, just for consistency
git checkout 1.0.1python ./launch.py gen --template mixlora --tasks <arc-c/arc-e/boolq/obqa/piqa/siqa/hellaswag/winogrande>
python ./launch.py run --base_model <Path to Your Base Model>The program will automatically perform training and evaluation. The results will be printed upon completion.
python ./launch.py gen --template mixlora --tasks "arc-c;arc-e;boolq;obqa;piqa" --multi_task True --adapter_name mixlora
python ./launch.py run --base_model <Path to Your Base Model>The program will automatically perform training and evaluation. The results will be printed upon completion.
We referenced this post from the PyTorch Discussion Website to measure the time of training and inference.
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
z = x + y
end.record()
# Waits for everything to finish running
torch.cuda.synchronize()
print(start.elapsed_time(end))For MoE-PEFT, we injected these codes into the train function in moe_peft/trainer.py to measure the time elapsed, and we computed the token computation latency by dividing these times by the number of tokens in one batch. The peak GPU memory usage was collected using torch.cuda.max_memory_allocated API. Every metric was collected by running the experiment 10 times separately and calculating the average value.
Compared with LoRA, MixLoRA have some additional configurations.
{
"name": "lora_0",
"optim": "adamw",
"lr": 1e-5,
"batch_size": 16,
"micro_batch_size": 2,
"num_epochs": 3,
"r": 8,
"lora_alpha": 16,
"lora_dropout": 0.05,
"target_modules": {
"q_proj": true,
"k_proj": false,
"v_proj": true,
"o_proj": false,
"gate_proj": true,
"down_proj": true,
"up_proj": true
},
"data": "yahma/alpaca-cleaned",
"prompt": "alpaca",
"group_by_length": false
}This is an example of LoRA training configuration.
MixLoRA have three routing strategies: top-k routing (like Mixtral), top-p routing (like Dynamic MoE) and top-1 switch routing (like Switch Transformers), can be configured with "routing_strategy": "mixlora", "routing_strategy": "mixlora-dynamic" or "routing_strategy": "mixlora-switch".
Top-k Routing
{
...
"routing_strategy": "mixlora",
"router_init_range": 0.02,
"jitter_noise": 0.0,
"num_experts": 8,
"top_k": 2,
"router_loss": true,
"router_aux_loss_coef": 0.01,
...
}Top-p Routing
{
...
"routing_strategy": "mixlora-dynamic",
"router_init_range": 0.02,
"jitter_noise": 0.0,
"num_experts": 8,
"top_p": 0.8,
"temperature": 0.0,
"router_loss": true,
"router_aux_loss_coef": 0.01,
...
}Top-1 Switch Routing
{
...
"routing_strategy": "mixlora-switch",
"router_init_range": 1.0,
"jitter_noise": 0.01,
"num_experts": 8,
"expert_capacity": 32,
"ffn_dropout": 0.0,
"router_loss": true,
"router_aux_loss_coef": 0.01,
"router_z_loss_coef": 0.01,
...
}expert_capacity = (max_sequence_length / num_experts) * capacity_factor
common values of capacity_factor: 1.0, 1.25, 2.0
You can add these items into training configurations to enable the MixLoRA architecture.
If you want to control the lora settings of experts separately, just add "expert_lora" block to the config:
{
...
"expert_lora": {
"r": 8,
"lora_alpha": 16,
"lora_dropout": 0.05
},
...
}Basic command for creating a baseline model on the Alpaca Cleaned dataset:
python launch.py gen --template mixlora --tasks yahma/alpaca-cleaned
python launch.py run --base_model meta-llama/Llama-2-7b-hfPlease note that once the MixLoRA model is created, the number of experts in the model cannot be changed.
# Run WebUI of Inference
python inference.py \
--base_model meta-llama/Llama-2-7b-hf \
--lora_weights TUDB-Labs/alpaca-mixlora-7b \
--template template/alpaca.json
# Simply Generate
python generate.py \
--base_model meta-llama/Llama-2-7b-hf \
--lora_weights TUDB-Labs/alpaca-mixlora-7b \
--template template/alpaca.json \
--instruction "What is MoE-PEFT?"If MixLoRA has been useful for your work, please consider citing it using the appropriate citation format for your publication.
@misc{li2024mixlora,
title={MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA-based Mixture of Experts},
author={Dengchun Li and Yingzi Ma and Naizheng Wang and Zhengmao Ye and Zhiyuan Cheng and Yinghao Tang and Yan Zhang and Lei Duan and Jie Zuo and Cal Yang and Mingjie Tang},
year={2024},
eprint={2404.15159},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{alpaca-mixlora-7b,
author = {Dengchun Li and Yingzi Ma and Naizheng Wang and Zhengmao Ye and Zhiyuan Cheng and Yinghao Tang and Yan Zhang and Lei Duan and Jie Zuo and Cal Yang and Mingjie Tang},
title = {MixLoRA LoRA MoE adapter based on AlpacaCleaned dataset and LLaMA-2-7B base model},
year = {2024},
publisher = {HuggingFace Hub},
howpublished = {\url{https://huggingface.co/TUDB-Labs/alpaca-mixlora-7b}},
}Copyright © 2023-2024 All Rights Reserved.
MixLoRA, MoE-PEFT and the weights of alpaca-mixlora-7b are licensed under the Apache 2.0 License.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.