Transforming text into data to extract meaning and make connections. In development.
See also our paper, Heritage connector: A machine learning framework for building linked open data from museum collections, at https://doi.org/10.1002/ail2.23.
A set of tools to:
- load tabular collection data to a knowledge graph
- find links between collection entities and Wikidata
- perform NLP to create more links in the graph (also see hc-nlp)
- explore and analyse a collection graph ways that aren't possible in existing collections systems
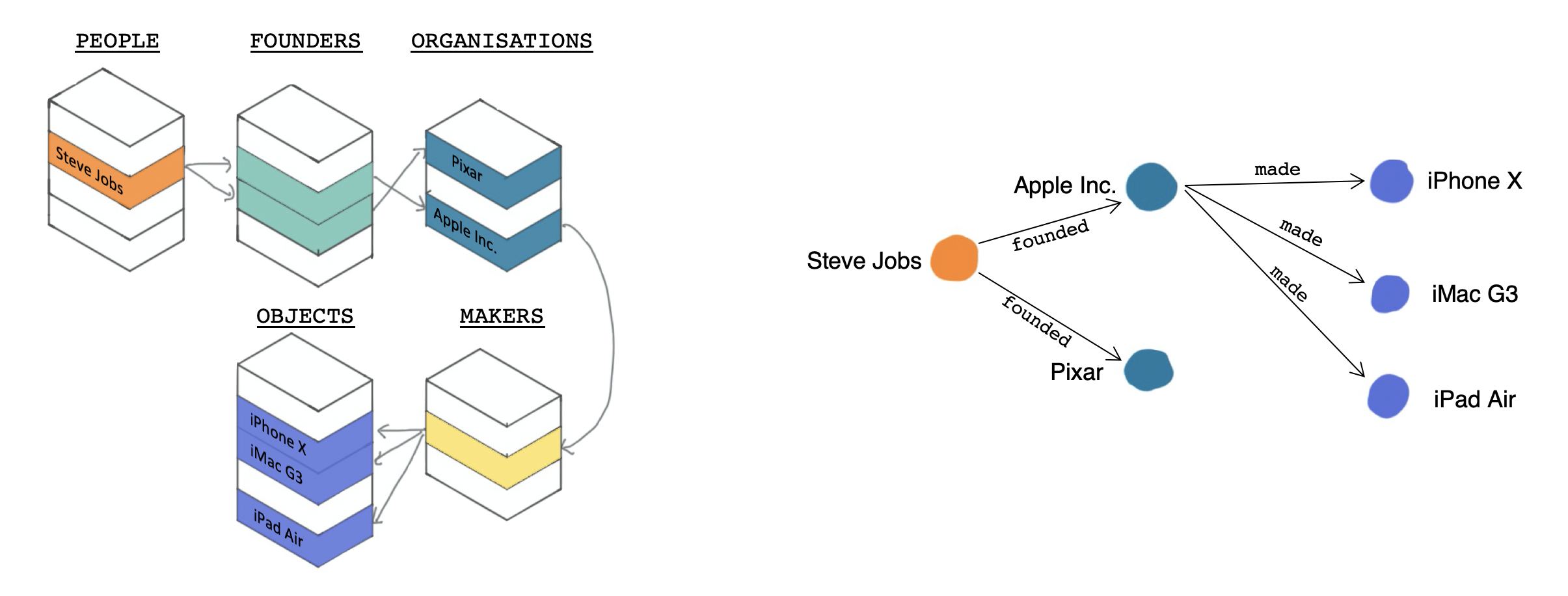
The main project page is here. We're also writing about our research on the project blog as we develop these tools and methods.
Some blog highlights:
- Why are we doing this? Sidestepping The Limitations Of Collection Catalogues With Machine Learning And Wikidata
- How will it work? Knowledge Graphs, Machine Learning And Heritage Collections
- Webinars: Wikidata And Cultural Heritage Collections, Connecting The UK's Cultural Heritage
- Python 3
- Create a new branch / Pull Request for each new feature / unit of functionality
We use pipenv for dependency management. You can also install dependencies from requirements.txt and dev dependencies from requirements_dev.txt.
Optional dependencies (for experimental features):
torch,dgl,dgl-ke: KG embeddingsspacy-nightly: export to spaCy KnowledgeBase for Named Entity Linking
Run python -m pytest with optional --cov=heritageconnector for a coverage report.
We use pytest for tests, and all tests are in ./test.
To run web app (in development): python -m heritageconnector.web.app
Cite as:
Dutia, K, Stack, J. Heritage connector: A machine learning framework for building linked open data from museum collections. Applied AI Letters. 2021;e23. https://doi.org/10.1002/ail2.23