
📘 PageIndex is a vectorless, reasoning-based RAG system that represents documents as hierarchical tree structures. It enables LLMs to navigate and retrieve information through structure and reasoning, not vector similarity — much like a human would retrieve information using a book's index.
🔌 PageIndex MCP exposes this LLM-native, in-context tree index directly to LLMs via MCP, allowing platforms like Claude, Cursor, and other MCP-compatible agents or LLMs to reason over document structure and retrieve the right information — without vector databases.
Want to chat with long PDFs but hit context limit reached errors? Add your file to PageIndex to seamlessly chat with long PDFs on any agent/LLM platforms.
✨ Chat to long PDFs the human-like, reasoning-based way ✨
- Support local and online PDFs
- Free 1000 pages
- Unlimited conversations
For more information, visit the PageIndex MCP page.
💡 Looking for a fully hosted experience? Try PageIndex Chat 🤖: a human-like document analyst that lets you chat with long PDFs using the same agentic, reasoning-based workflow as PageIndex MCP.

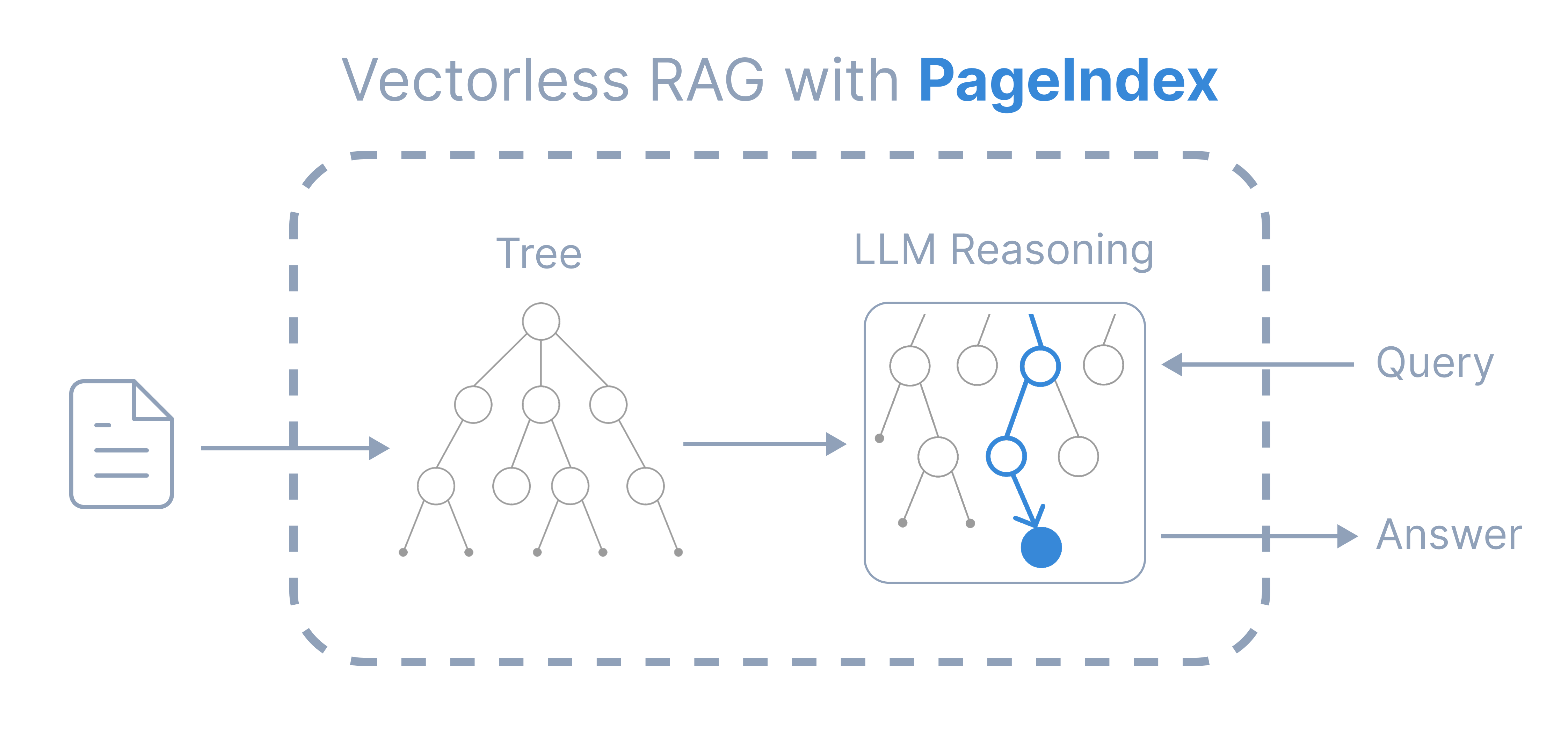
PageIndex is a vectorless, reasoning-based RAG system that generates hierarchical tree structures of documents and uses multi-step reasoning and tree search to retrieve information like a human expert would. It has the following key properties:
- Higher Accuracy: Relevance beyond similarity
- Better Transparency: Clear reasoning trajectory with traceable search paths
- Like A Human: Retrieve information like a human expert navigates documents
- No Vector DB: No extra infrastructure overhead
- No Chunking: Preserve full document context and structure
- No Top-K: Retrieve all relevant passages automatically
See PageIndex MCP for full video guidances.
One-Click Installation with Desktop Extension (MCPB):
- Download the latest
.mcpbfile from Releases - Double-click the
.mcpbfile to install automatically in Claude Desktop - The OAuth authentication will be handled automatically when you first use the extension
Note: Claude Desktop Extensions now use the
.mcpb(MCP Bundle) file extension. Existing.dxtextensions will continue to work, but we recommend using.mcpbfor new installations.
This is the easiest way to get started with PageIndex's reasoning-based RAG capabilities.
Requirements: Node.js ≥18.0.0
Add to your MCP configuration:
{
"mcpServers": {
"pageindex": {
"command": "npx",
"args": ["-y", "pageindex-mcp"]
}
}
}Note: This local server provides full PDF upload capabilities and handles all authentication automatically.
Connect directly to the PageIndex OAuth-enabled MCP server:
{
"mcpServers": {
"pageindex": {
"type": "http",
"url": "https://chat.pageindex.ai/mcp"
}
}
}For clients that don't support HTTP MCP servers:
If your MCP client doesn't support HTTP servers directly, you can use mcp-remote as a bridge:
{
"mcpServers": {
"pageindex": {
"command": "npx",
"args": ["-y", "mcp-remote", "https://chat.pageindex.ai/mcp"]
}
}
}Note: Option 1 provides local PDF upload capabilities, while Option 2 only supports PDF processing via URLs (no local file uploads).
This project is licensed under the terms of the MIT open source license. Please refer to MIT for the full terms.