[TOC]
本节为您提供最常用的MySQL函数,包括聚合函数,字符串函数,日期时间函数,控制流函数等。
- AVG - 计算一组值或表达式的平均值。
- COUNT - 计算表中的行数。
- INSTR - 返回字符串中第一次出现的子字符串的位置。
- SUM - 计算一组值或表达式的总和。
- MIN - 在一组值中找到最小值
- MAX - 在一组值中找到最大值
- GROUP_CONCAT()函数 - 将字符串从分组中连接成具有各种选项(如
DISTINCT,ORDER BY和SEPARATOR)的字符串。 - MySQL标准偏差函数 - 显示如何计算人口标准偏差和样本标准偏差。
- CONCAT - 将两个或多个字符串组合成一个字符串。
- LENGTH&CHAR_LENGTH - 获取字符串的长度,以字节和字符为单位。
- LEFT - 获取具有指定长度的字符串的左侧部分。
- REPLACE - 搜索并替换字符串中的子字符串。
- SUBSTRING - 从具有特定长度的位置开始提取子字符串。
- TRIM - 从字符串中删除不需要的字符。
- FIND_IN_SET - 在以逗号分隔的字符串列表中查找字符串。
- FORMAT - 格式化具有特定区域设置的数字,四舍五入到小数位数
- CASE -
THEN如果WHEN满足分支中的条件,则返回分支中的相应结果,否则返回ELSE分支中的结果。 - IF - 根据给定条件返回值。
- IFNULL - 如果它不是NULL则返回第一个参数,否则返回第二个参数。
- NULLIF - 如果第一个参数等于第二个参数,则返回NULL,否则返回第一个参数。
- CURDATE - 返回当前日期。
- DATEDIFF - 计算两个
DATE值之间的天数 。 - DAY - 获取指定日期的月份日期。
- DATE_ADD - 将日期值添加到日期值。
- DATE_SUB - 从日期值中减去时间值。
- DATE_FORMAT - 根据指定的日期格式格式化日期值。
- DAYNAME - 获取指定日期的工作日名称。
- DAYOFWEEK - 返回日期的工作日索引。
- EXTRACT - 提取日期的一部分。
- NOW - 返回执行语句的当前日期和时间。
- MONTH - 返回表示指定日期月份的整数。
- STR_TO_DATE - 根据指定的格式将字符串转换为日期和时间值。
- SYSDATE - 返回当前日期。
- TIMEDIFF - 计算两个
TIME或DATETIME值之间的差异。 - TIMESTAMPDIFF - 计算两个
DATE或DATETIME值之间的差异。 - WEEK - 返回一个星期的日期。
- WEEKDAY - 返回日期的工作日索引。
- YEAR -返回日期值的年份部分。
- COALESCE - 返回第一个非null参数,这对于替换null非常方便。
- GREATEST&LEAST - 取n个参数并分别返回n个参数的最大值和最小值。
- ISNULL - 如果参数为null,则返回1,否则返回零。
- ABS - 返回数字的绝对值。
- CEIL - 返回大于或等于输入数字的最小整数值。
- FLOOR - 返回不大于参数的最大整数值。
- MOD - 返回数字的余数除以另一个。
- ROUND - 将数字四舍五入到指定的小数位数。
- TRUNCATE - 将数字截断为指定的小数位数。
- LAST_INSERT_ID - 获取最后生成的最后一个插入记录的序列号。
- CAST - 将任何类型的值转换为具有指定类型的值。
窗口函数也称为 OLAP 函数。
OLAP 是 OnLine Analytical Processing 的简称,意思是对数据库数据进行实时分析处理。
为了便于理解,称之为窗口函数。
常规的 SELECT 语句都是对整张表进行查询,而窗口函数可以让我们有选择的去某一部分数据进行汇总、计算和排序。
窗口函数和普通聚合函数也很容易混淆,二者区别如下:
-
聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,有几条记录执行完还是几条。
-
部分聚合函数也可以用于窗口函数。
窗口函数(也称为 OLAP 函数)是一种可以在查询中对数据进行分组并排序的特殊函数。
它的作用是对结果集中的一部分数据进行计算,而不需要像传统的聚合函数那样将数据压缩成一个单一的值。
可以将窗口函数理解为在“窗口”内对数据进行分析,而这个窗口内的数据通常是通过分组、排序或者其他方式指定的。
它允许在每一行中计算某种统计值,但每一行的数据仍然会被保留,而不是被合并成一个结果。
举个例子
假设你有一个关于学生成绩的表格,包含以下字段:
- student_id(学生 ID)
- exam_score(考试成绩)
- exam_date(考试日期)
表格如下:
student_id exam_score exam_date
1 90 2024-11-01
2 85 2024-11-01
3 92 2024-11-01
1 88 2024-11-02
2 78 2024-11-02
3 85 2024-11-02
如果你想要计算每个学生考试成绩的累计平均分,并且希望查看所有学生每一场考试的成绩以及累计平均分,你可以使用窗口函数来实现:
SELECT
student_id,
exam_score,
exam_date,
AVG(exam_score) OVER (PARTITION BY student_id ORDER BY exam_date) AS running_avg
FROM
exam_scores;在这个查询中,AVG(exam_score) OVER (PARTITION BY student_id ORDER BY exam_date) 就是一个窗口函数:
- PARTITION BY:按 student_id 分组,即每个学生的数据被单独处理。
- ORDER BY:按 exam_date 排序,即成绩会按日期顺序进行计算。
- 窗口函数:在每个学生的所有记录中,计算该学生到当前考试为止的累计平均分。
结果:
student_id exam_score exam_date running_avg
1 90 2024-11-01 90.0
2 85 2024-11-01 85.0
3 92 2024-11-01 92.0
1 88 2024-11-02 89.0
2 78 2024-11-02 81.5
3 85 2024-11-02 88.5
解释:
- 对于 student_id = 1:
- 第一行是 90,没有其他成绩,平均分就是 90。
- 第二行是 88,所以平均分是 (90 + 88) / 2 = 89。
- 对于 student_id = 2:
- 第一行是 85,没有其他成绩,平均分就是 85。
- 第二行是 78,所以平均分是 (85 + 78) / 2 = 81.5。
- 对于 student_id = 3:
- 第一行是 92,没有其他成绩,平均分就是 92。
- 第二行是 85,所以平均分是 (92 + 85) / 2 = 88.5。
关键点:
- 窗口函数保留每一行数据:不像聚合函数(如 SUM() 或 COUNT()),窗口函数不会合并行数据,它为每行计算一个值,并且每行依然保留在结果集中。
- 可以进行复杂的分析:你可以使用窗口函数计算累计和、排名、移动平均等,而不需要手动对数据进行多次查询。
- 灵活性:可以通过 PARTITION BY 来指定分组,通过 ORDER BY 来指定排序,使得在分析时非常灵活。
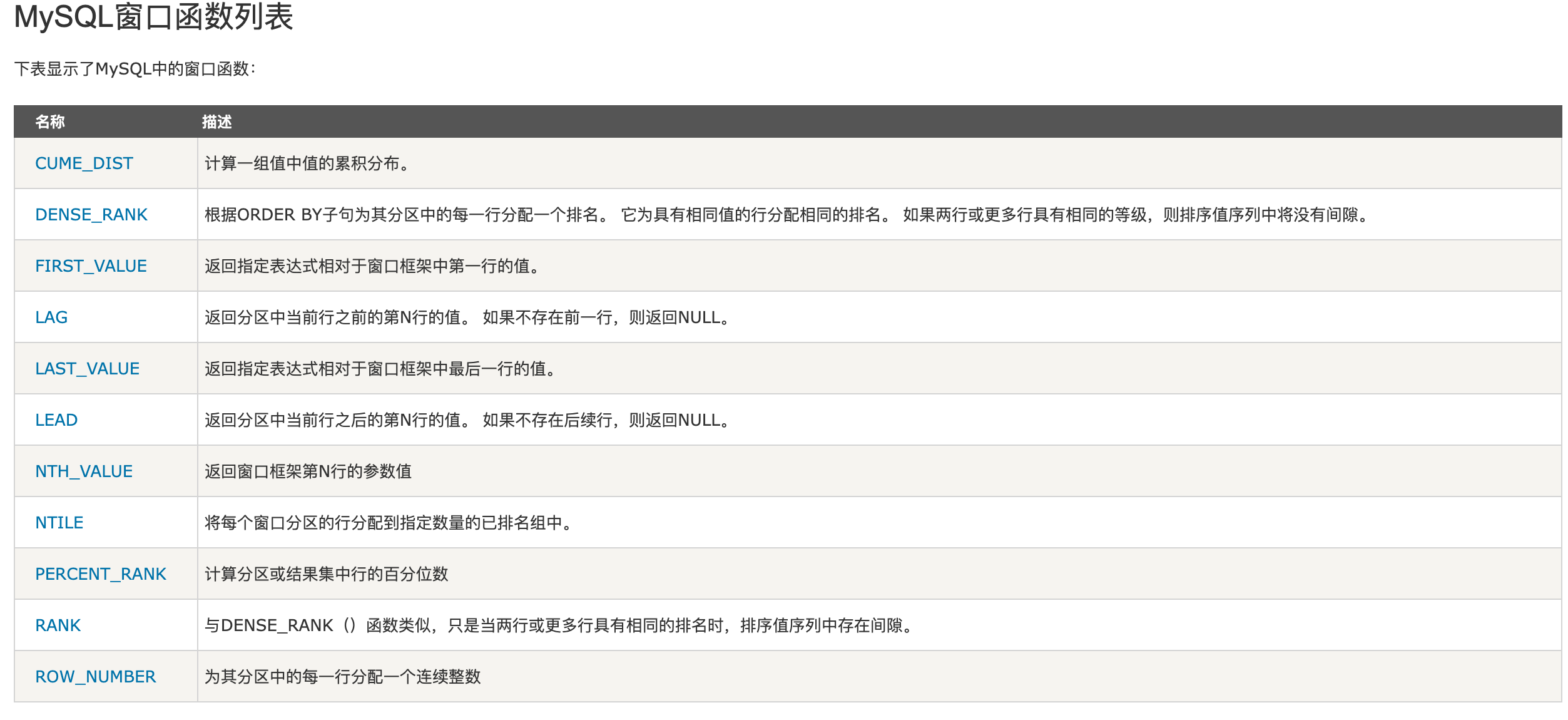
常见的窗口函数:
- ROW_NUMBER():为每一行分配唯一的数字。
- RANK():为每一行分配一个排名,若有并列名次,则跳过排名。
- DENSE_RANK():与 RANK() 类似,但排名不跳过。
- NTILE(n):将数据划分为 n 个部分,并为每行分配一个组号。
- SUM(), AVG(), MIN(), MAX():这些聚合函数可以作为窗口函数使用,按特定规则对分组的数据进行计算。
总结:
窗口函数就像是对数据表的一扇“窗口”,它允许你在不改变数据结构的情况下,对某些数据进行详细的统计和分析,非常适合处理类似排名、累计和移动平均等问题。
按照功能划分,可以把MySQL支持的窗口函数分为如下几类:
-
序号函数:ROW_NUMBER() / RANK() / DENSE_RANK()
-
分布函数:PERCENT_RANK() / CUME_DIST()
-
前后函数:LAG() / LEAD()
-
头尾函数:FIRST_VALUE() / LAST_VALUE()
-
其他函数:NTH_VALUE() / NTILE()
窗口函数的通用形式:
<窗口函数> OVER ([PARTITION BY <列名>] ORDER BY <排序用列名>)[] 中的内容可以省略。
窗口函数最关键的是搞明白关键字 PARTITON BY 和 ORDER BY 的作用。
-
PARTITON BY 是用来分组,即选择要看哪个窗口,类似于 GROUP BY 子句的分组功能,但是 PARTITION BY 子句并不具备 GROUP BY 子句的汇总功能,并不会改变原始表中记录的行数。
-
ORDER BY 是用来排序,即决定窗口内,是按那种规则 (字段) 来排序的。
举个🌰:
SELECT
product_name,
product_type,
sale_price,
RANK() OVER (
PARTITION BY product_type
ORDER BY sale_price) AS ranking
FROM product得到的结果是:
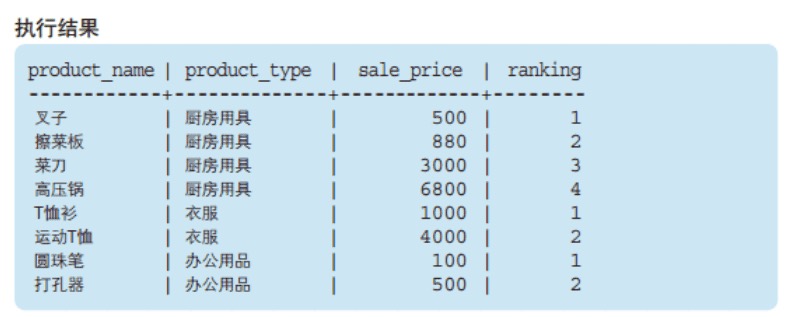
我们先忽略生成的新列 - [ranking],看下原始数据在 PARTITION BY 和 ORDER BY 关键字的作用下发生了什么变化。
- PARTITION BY 能够设定窗口对象范围。
本例中,为了按照商品种类进行排序,我们指定了 product_type。即一个商品种类就是一个小的 "窗口"。
- ORDER BY 能够指定按照哪一列、何种顺序进行排序。
为了按照销售单价的升序进行排列,我们指定了 sale_price。此外,窗口函数中的 ORDER BY 与 SELECT 语句末尾的 ORDER BY 一样,可以通过关键字 ASC/DESC 来指定升序 / 降序。省略该关键字时会默认按照 ASC,也就是
升序进行排序。本例中就省略了上述关键字 。
其中,OVER 是关键字,用来指定函数执行的窗口范围,如果后面括号中什么都不写,则意味着窗口包含满足 WHERE 条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下四种语法来设置窗口。
window_name:给窗口指定一个别名,如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读。
看下面的例子,如果指定一个别名 w,则编写程序如下:
SELECT * FROM(
SELECT
ROW_NUMBER() OVER w as row_num,
order_id,
user_no,
amount,
create_date
FROM order_tab
WINDOW w AS (PARTITION BY user_no ORDER BY amount desc)
) t ;partition 子句:窗口按照那些字段进行分组,窗口函数在不同的分组上分别执行。
上面的例子就按照用户 id 进行了分组。在每个用户 id 上,按照 order by 的顺序分别生成从 1 开始的顺序编号。
order by 子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号。
可以和 partition 子句配合使用,也可以单独使用。
上例中二者同时使用,如果没有 partition 子句,则会按照所有用户的订单金额排序来生成序号。
frame 子句:frame 是当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用。
比如要根据每个订单动态计算包括本订单和按时间顺序前后两个订单的平均订单金额,则可以设置如下 frame 子句来创建滑动窗口:
select * from
(
select
order_id,user_no, amount,
avg(amount)over w as avg_num,
create_date
from order_tab
WINDOW w AS (partition by user_no order by create_date desc ROWS BETWEEN I PRECEDING AND I FOLLOWING)
)t
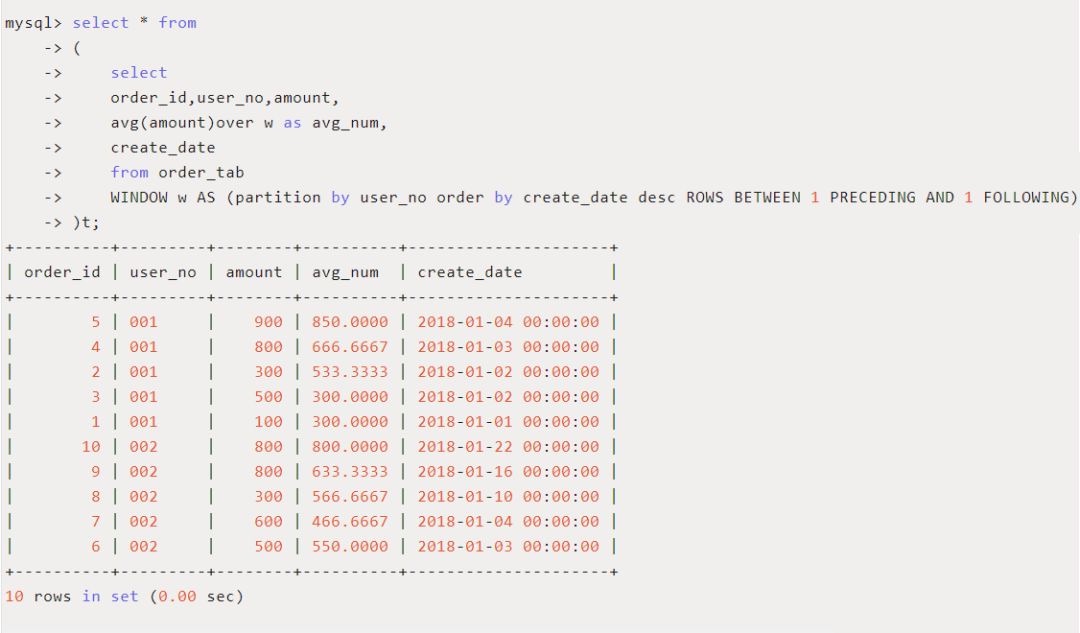
从结果可以看出,
- order_id 为 5 订单属于边界值,没有前一行,因此平均订单金额为 (900+800)/2 = 850;
- order_id 为 4 的订单前后都有订单,所以平均订单金额为(900+800+300)/3 =6 66.6667,
- 以此类推就可以得到一个基于滑动窗口的动态平均订单值。
- 此例中,窗口函数用到了传统的聚合函数avg(),用来计算动态的平均值。
大致来说,窗口函数可以分为两类。
-
一是将 SUM、MAX、MIN 等聚合函数用在窗口函数中
-
二是 RANK、DENSE_RANK 等排序用的专用窗口函数
-
RANK 函数 (英式排序) 序号函数
- 计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
- 例如有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位……
-
DENSE_RANK 函数 (中式排序) 序号函数
- 同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
- 例如有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……
-
ROW_NUMBER 函数 序号函数
- 赋予唯一的连续位次。
- 例如有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位
运行以下代码:
SELECT
product_name,
product_type,
sale_price,
RANK() OVER (ORDER BY sale_price) AS ranking,
DENSE_RANK() OVER (ORDER BY sale_price) AS dense_ranking ,
ROW_NUMBER() OVER (ORDER BY sale_price) AS row_num
FROM product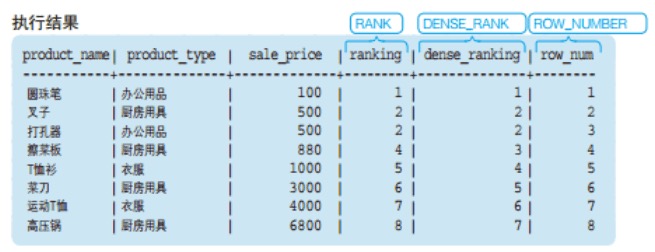
聚合函数在开窗函数中的使用方法和之前的专用窗口函数一样,只是出来的结果是一个 累计 的聚合函数值。
运行以下代码:
SELECT
product_id,
product_name,
sale_price,
SUM(sale_price) OVER (ORDER BY product_id) AS current_sum,
AVG(sale_price) OVER (ORDER BY product_id) AS current_avg
FROM product;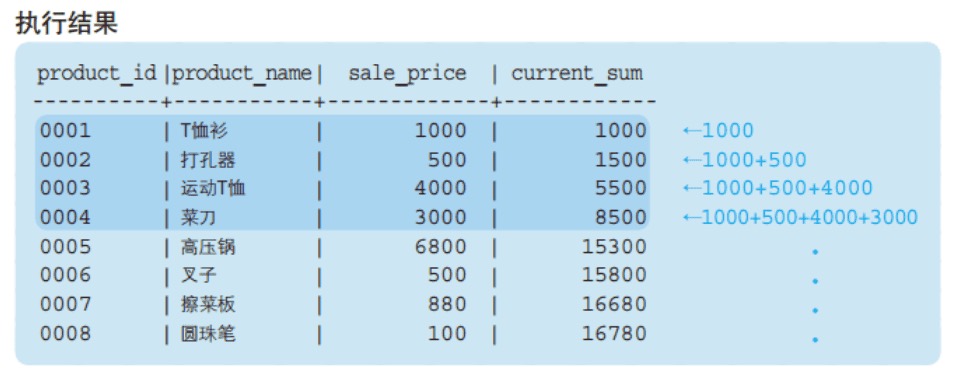
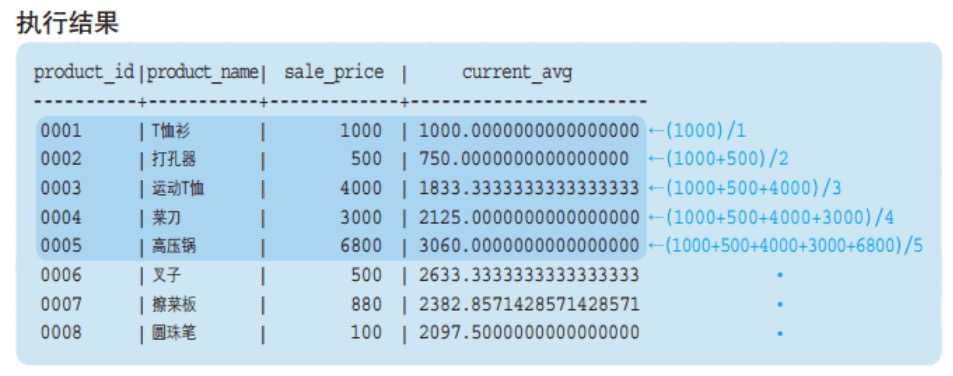
可以看出,聚合函数结果是,按我们指定的排序,这里是 product_id,当前所在行及之前所有的行 的合计或均值。
即累计到当前行的聚合。
对于滑动窗口的范围指定,有两种方式,基于行和基于范围,具体区别如下:
-
基于行:
通常使用 BETWEEN frame_start AND frame_end 语法来表示行范围,frame_start 和 frame_end 可以支持如下关键字,来确定不同的动态行记录:
- CURRENT ROW 边界是当前行,一般和其他范围关键字一起使用
- UNBOUNDED PRECEDING 边界是分区中的第一行
- UNBOUNDED FOLLOWING 边界是分区中的最后一行
- expr PRECEDING 边界是当前行减去expr的值
- expr FOLLOWING 边界是当前行加上expr的值
比如,下面都是合法的范围:
- rows BETWEEN 1 PRECEDING AND 1 FOLLOWING 窗口范围是当前行、前一行、后一行一共三行记录。
- rows UNBOUNDED FOLLOWING 窗口范围是当前行到分区中的最后一行。
- rows BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 窗口范围是当前分区中所有行,等同于不写。
-
基于范围:
和基于行类似,但有些范围不是直接可以用行数来表示的。 比如希望窗口范围是一周前的订单开始,截止到当前行,则无法使用 rows 来直接表示, 此时就可以使用范围来表示窗口:INTERVAL 7 DAY PRECEDING。Linux 中常见的最近 1 分钟、5 分钟负载是一个典型的应用场景。
有的函数不管有没有 frame 子句,它的窗口都是固定的,也就是前面介绍的静态窗口,这些函数包括如下:
- CUME_DIST() 分布函数
- DENSE_RANK()
- LAG() 前后函数
- LEAD() 前后函数
- NTILE()
- PERCENT_RANK() 分布函数
- RANK()
- ROW_NUMBER()
接下来我们以上例的订单表为例,来介绍每个函数的使用方法。表中各字段含义按顺序分别为订单号、用户id、订单金额、订单创建日期。
在上面提到,聚合函数在窗口函数使用时,计算的是累积到当前行的所有的数据的聚合。
实际上,还可以指定更加详细的 汇总范围。
该汇总范围成为 框架(frame)。
语法:
<窗口函数> OVER (ORDER BY <排序用列名> ROWS n PRECEDING )
<窗口函数> OVER (ORDER BY <排序用列名> ROWS BETWEEN n PRECEDING AND n FOLLOWING)PRECEDING(“之前”),将框架指定为 “截止到之前 n 行”,加上自身行;
FOLLOWING(“之后”),将框架指定为 “截止到之后 n 行”,加上自身行;
BETWEEN 1 PRECEDING AND 1 FOLLOWING,将框架指定为 “之前 1 行” + “之后 1 行” + “自身”
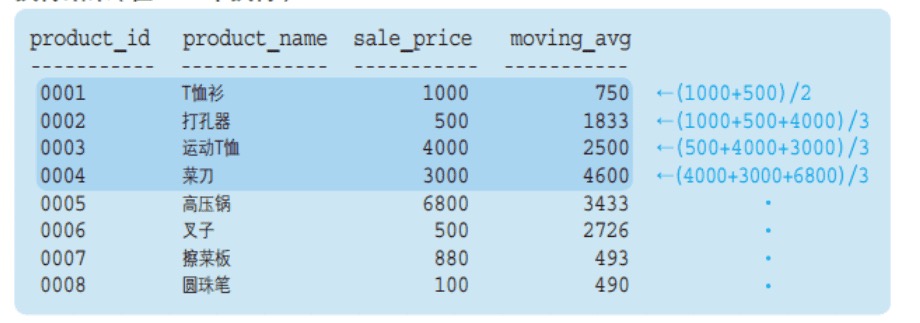
执行以下代码:
SELECT
product_id,
product_name,
sale_price,
AVG(sale_price) OVER (
ORDER BY product_id
ROWS 2 PRECEDING) AS moving_avg,
AVG(sale_price) OVER (
ORDER BY product_id
ROWS BETWEEN 1 PRECEDING
AND 1 FOLLOWING) AS moving_avg
FROM product执行结果:
注意观察框架的范围。
ROWS 2 PRECEDING:
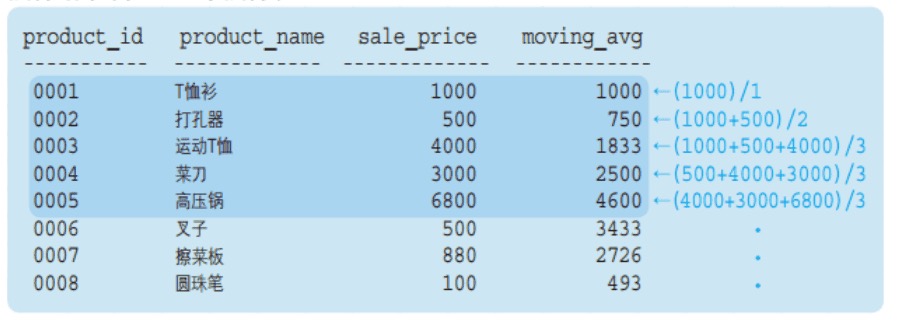
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING:
窗口函数适用范围和注意事项
- 原则上,窗口函数只能在 SELECT 子句中使用。
- 窗口函数 OVER 中的 ORDER BY 子句并不会影响最终结果的排序。其只是用来决定窗口函数按何种顺序计算。
常规的 GROUP BY 只能得到每个分类的小计,有时候还需要计算分类的合计,可以用 ROLLUP 关键字。
SELECT
product_type,
regist_date,
SUM(sale_price) AS sum_price
FROM product
GROUP BY product_type, regist_date
WITH ROLLUP;得到的结果为:
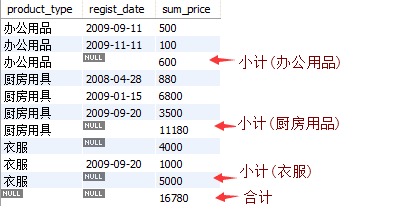
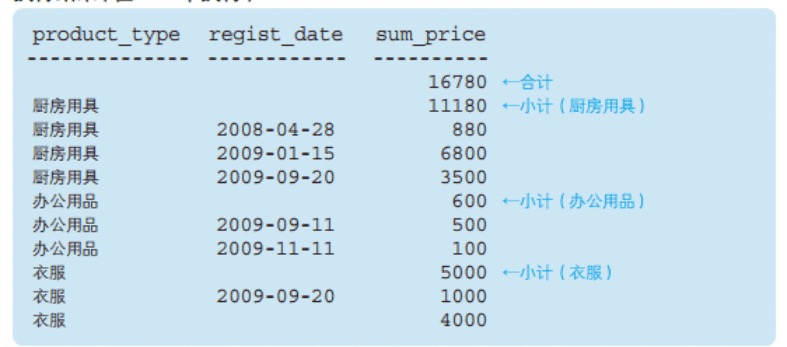
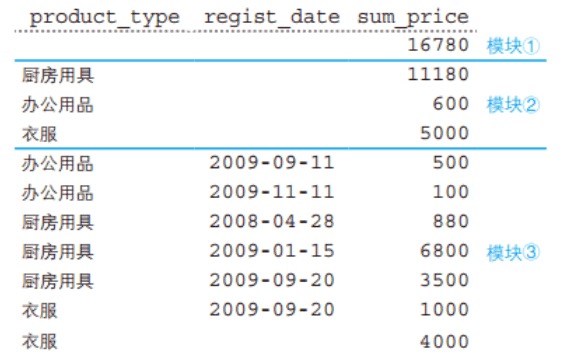
这里 ROLLUP 对 product_type, regist_date 两列进行合计汇总。
结果实际上有三层聚合,如下图模块 3 是常规的 GROUP BY 的结果,需要注意的是衣服有个注册日期为空的,这是本来数据就存在日期为空的,不是对衣服类别的合计;
模块 2 和 1 是 ROLLUP 带来的合计,模块 2 是对产品种类的合计,模块 1 是对全部数据的总计。
ROLLUP 可以对多列进行汇总求小计和合计。
用途:显示分区中的当前行号
使用场景:希望查询每个用户订单金额最高的前三个订单
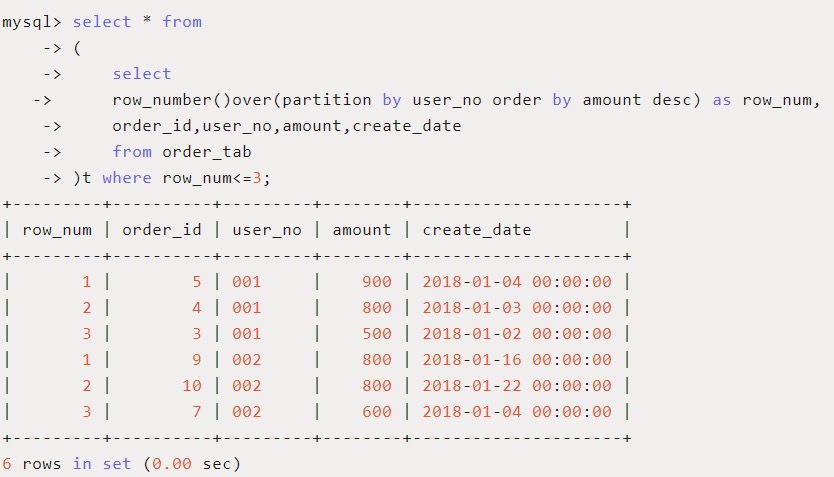
此时可以使用 ROW_NUMBER() 函数按照用户进行分组并按照订单日期进行由大到小排序,最后查找每组中序号 <=3 的记录。
对于用户‘002’的订单,大家发现订单金额为800的有两条,序号随机排了 1 和 2,但很多情况下二者应该是并列第一,而订单为600的序号则可能是第二名,也可能为第三名,这时候,row_number就不能满足需求,需要rank和dense_rank出场。
这两个函数和row_number()非常类似,只是在出现重复值时处理逻辑有所不同。
上面例子我们稍微改一下,需要查询不同用户的订单中,按照订单金额进行排序,显示出相应的排名序号,SQL中用row_number() / rank() / dense_rank()分别显示序号,我们看一下有什么差别:
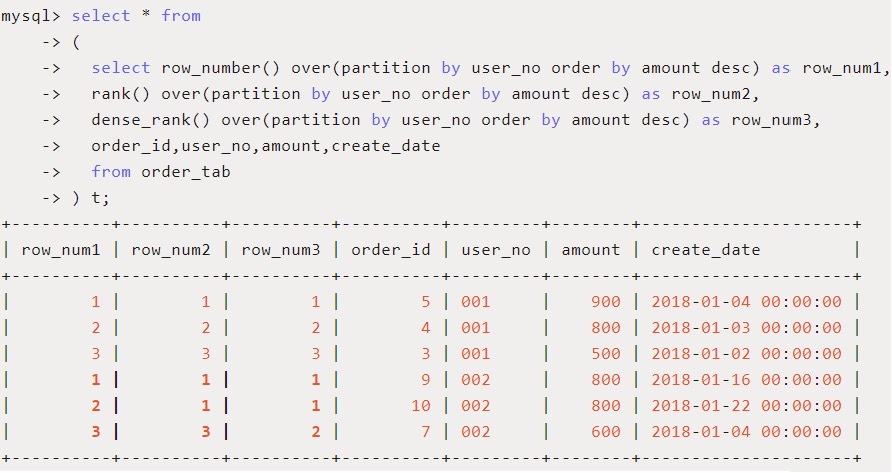
上面红色粗体显示了三个函数的区别,row_number()在amount都是800的两条记录上随机排序,但序号按照1、2递增,后面amount为600的的序号继续递增为3,中间不会产生序号间隙;rank()/dense_rank()则把amount为800的两条记录序号都设置为1,但后续amount为600的需要则分别设置为3(rank)和2(dense_rank)。即rank()会产生序号相同的记录,同时可能产生序号间隙;而dense_rank()也会产生序号相同的记录,但不会产生序号间隙。
用途:和之前的RANK()函数相关,每行按照如下公式进行计算:
其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数。
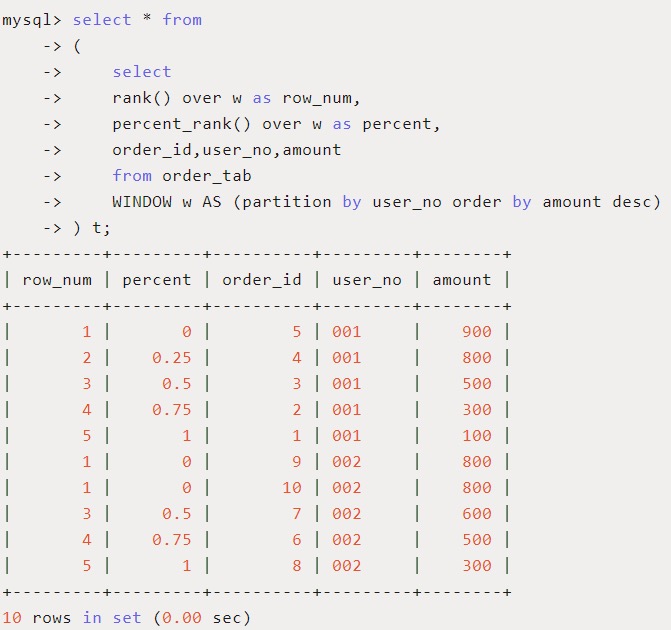
从结果看出,percent列按照公式(rank - 1) / (rows - 1)带入rank值(row_num列)和rows值(user_no为‘001’和‘002’的值均为5)。
用途:分组内小于等于当前rank值的行数/分组内总行数,这个函数比percen_rank使用场景更多。
应用场景:大于等于当前订单金额的订单比例有多少。
SQL如下:
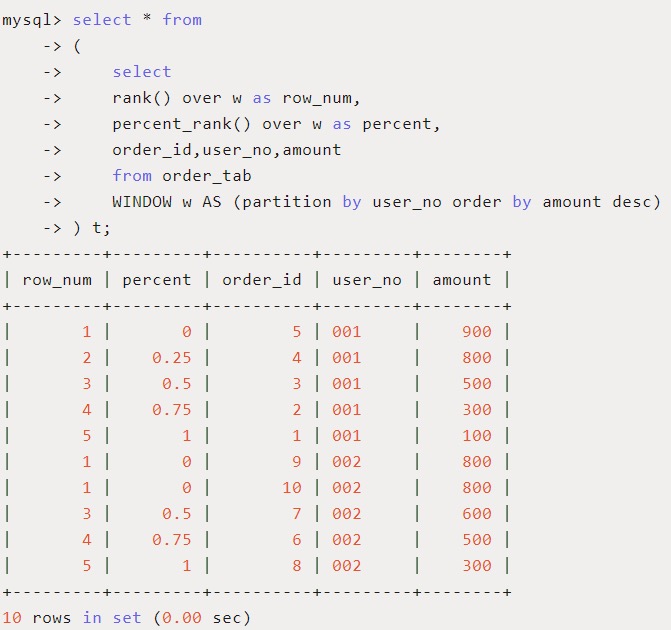
列 cume 显示了预期的数据分布结果。
用途:分区中位于当前行前n行(lead)/后n行(lag)的记录值。
使用场景:查询上一个订单距离当前订单的时间间隔。
SQL如下:
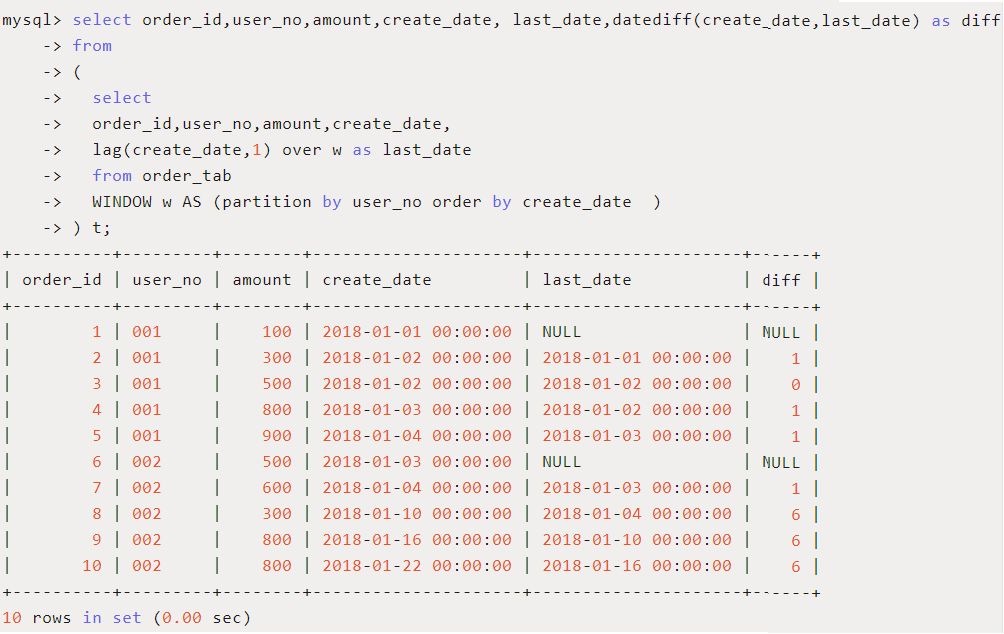
内层SQL先通过 lag 函数得到上一次订单的日期,外层SQL再将本次订单和上次订单日期做差得到时间间隔 diff。
用途:得到分区中的第一个/最后一个指定参数的值。
使用场景:查询截止到当前订单,按照日期排序第一个订单和最后一个订单的订单金额。
SQL如下:
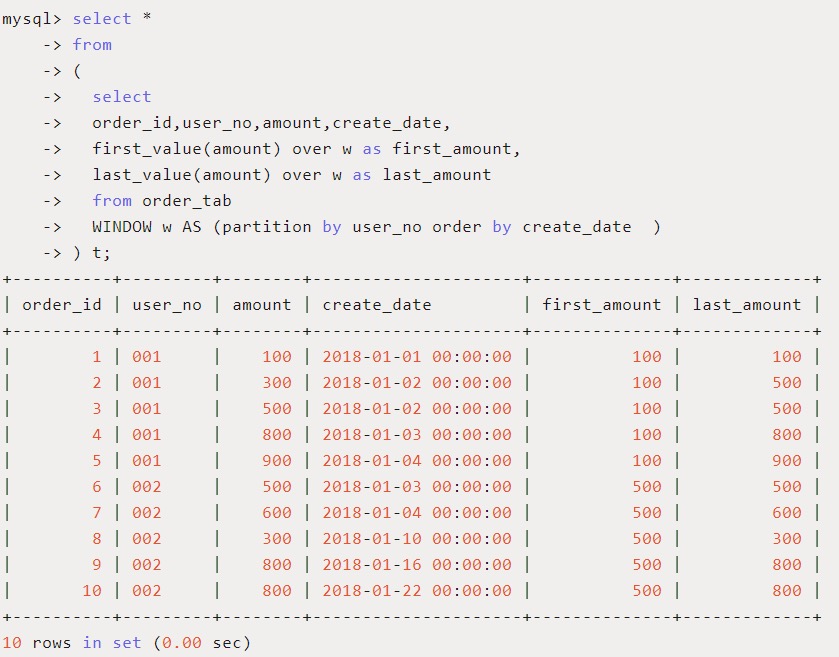
结果和预期一致,比如 order_id 为 4 的记录,first_amount 和 last_amount 分别记录了用户‘001’截止到时间2018-01-03 00:00:00为止,第一条订单金额100和最后一条订单金额800,注意这里是按时间排序的最早订单和最晚订单,并不是最小金额和最大金额订单。
用途:返回窗口中第N个expr的值,expr可以是表达式,也可以是列名。
应用场景:每个用户订单中显示本用户金额排名第二和第三的订单金额。
SQL如下:
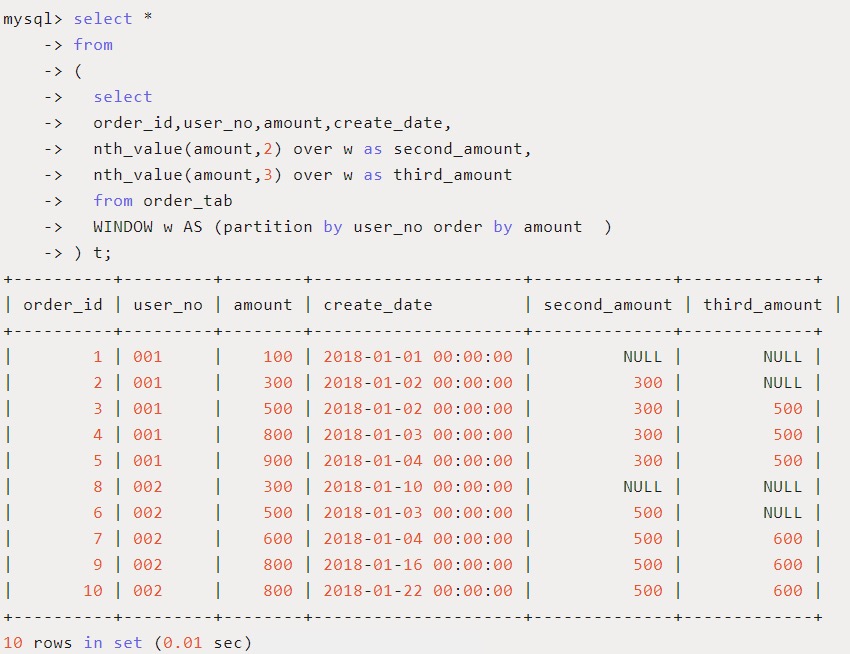
用途:将分区中的有序数据分为 n 个桶,记录桶号。
应用场景:将每个用户的订单按照订单金额分成 3 组。
SQL如下:
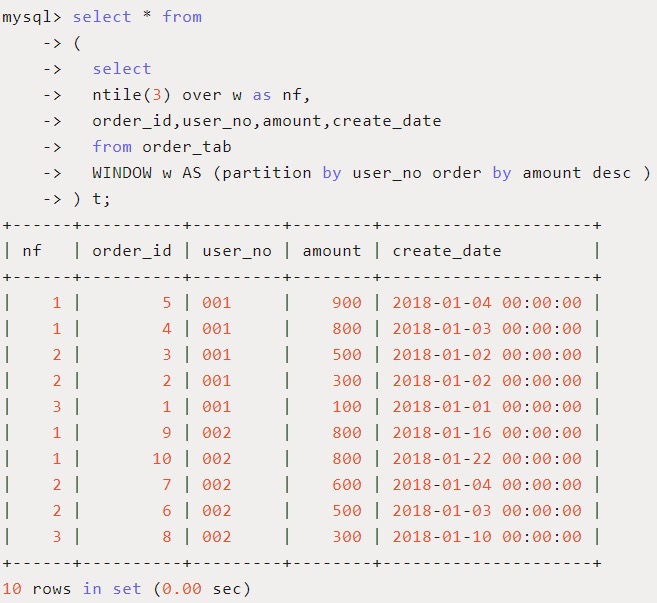
此函数在数据分析中应用较多,比如由于数据量大,需要将数据平均分配到N个并行的进程分别计算,此时就可以用NTILE(N)对数据进行分组,由于记录数不一定被N整除,所以数据不一定完全平均,然后将不同桶号的数据再分配。
请说出针对本章中使用的 product(商品)表执行如下 SELECT 语句所能得到的结果。
SELECT
product_id,
product_name,
sale_price,
MAX(sale_price) OVER (ORDER BY product_id) AS Current_max_price
FROM product按照 product_id 升序排列,计算出截⾄当前⾏的最⾼ sale_price 。
继续使用 product 表,计算出按照登记日期(regist_date)升序进行排列的各日期的销售单价(sale_price)的总额。排序是需要将登记日期为 NULL 的“运动 T 恤”记录排在第 1 位(也就是将其看作比其他日期都早)
如下两种⽅法都可以实现:
-- ①regist_date为NULL时,显示“1年1⽉1⽇”。
SELECT
regist_date,
product_name,
sale_price,
SUM(sale_price) OVER (
ORDER BY COALESCE(regist_date, CAST('0001-01-01' AS DATE))) AS current_sum_price
FROM Product;
-- ②regist_date为NULL时,将该记录放在最前显示。
SELECT
regist_date,
product_name,
sale_price,
SUM(sale_price) OVER (
ORDER BY regist_date NULLS FIRST) AS current_sum_price
FROM Product;思考题
① 窗口函数不指定 PARTITION BY 的效果是什么?
窗⼝函数不指定 PARTITION BY 就是针对排序列进⾏全局排序。
② 为什么说窗口函数只能在 SELECT 子句中使用?实际上,在 ORDER BY 子句使用系统并不会报错
本质上是因为 SQL 语句的执⾏顺序。
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
如果在 WHERE, GROUP BY, HAVING 使⽤了窗⼝函数,就是说提前进⾏了⼀次排序,排序之后再去除记录、汇总、汇总过滤,第⼀次排序结果就是错误的,没有实际意义。⽽ ORDER BY 语句执⾏顺序在 SELECT 语句之后,⾃然是可以使⽤的。