{kind=link}
{kind=link}
This repository is an improved pytorch implementation of the paper:
Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes
Link to the paper: https://arxiv.org/abs/2101.06085
Which is originally designed and proposed for real-time inference of road scene segmentation. However, we have extended the application of the DDRNet to medical applications by making two major contributions resulting in significant performance gain in the AUC score.
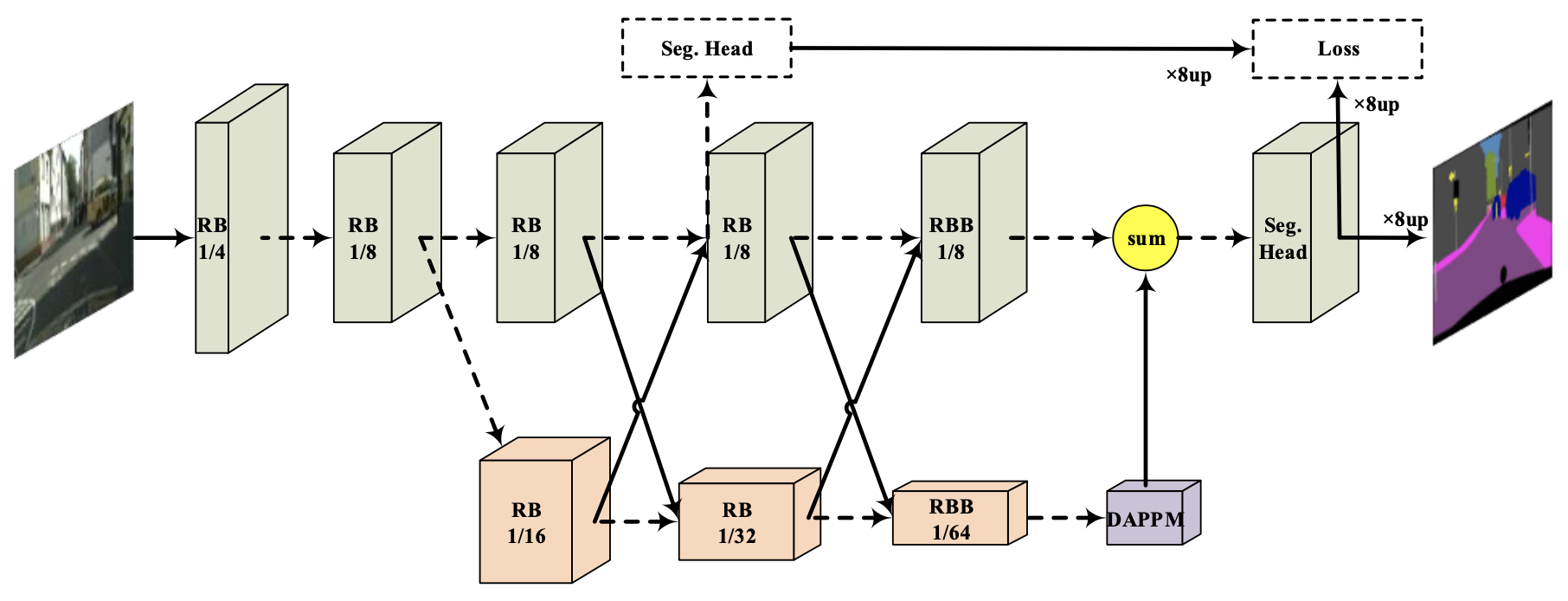
- We exploited the core model of the DDRNet as a classification network and trained it on the ImageNet dataset beforehand and used pretrained weights to boost the training of the network which also came with improvements on the performance of the model.(Reduces the number of epochs from 580 to only 135 epochs for the model to converge)
We have included the pretrinaed ImageNet weights in the weights directory named DDRNet23s_imagenet.pth
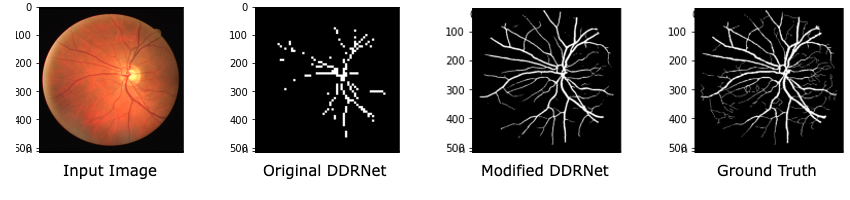
- The original DDRNet model predicts the output masks 1/8 of the input image size which is then bilinearly upsampled to the input image size. However, this would result in substantial spatial data loss and significantly decreases the model performance. We alleviate this issue by modifying the downsampling layers of the model to generate high resolution feature maps which leads to a huge gain in the performance of the model. (Results in significant gain in AUC score as much as %25)
The improvement in model performance is evident in the following predictions of the both networks:
The code is structured such that you can run experiments in different model and training configurations. You can modify these settings from the ddrnet_DRIVE.yaml file located in configs folder.
Note: The dataset contains 40 RGB images in total (20 images for training, 20 images for test).
In our setting, 10 images from the test set are used as an evaluation for early stopping and saving the best model and 10 remaining images were utilized as the test set.
In order to train the netwrok run the following commands.
git clone https://github.com/AghdamAmir/DDRNet_SemanticSegmentation.git
cd DDRNet_SemanticSegmentation
python train.py --cfg path/to/config/fileBefore running the training script, make sure that you have set your desired configurations in the config YAML file.
Running the script will save all train and validation losses in each training epoch in the log directory using which you can plot the loss curve by trainvalLossPlot.py in utils folder. In order to plot the curve, use the following command:
python utils/trainvalLossPlot.py --log path/to/log/fileAfter training the model, you will have the best model saved in the path specified in the configurations. Using these weights you can test the model
performance on train, test, val and testval datasets.
Running the following command will report the model performance metrics:
python test_ddrnet.py --cfg path/to/config/file --weight path/to/trained/weightsUsing the pretrained weights you can also visualize the model predictions for train, test, val and testval datasets. Running the following command will visualize the model predictions:
python visualize.py --cfg path/to/config/file --weight path/to/trained/weights --mode dataset_split_namemode specifies the type of dataset and could be one of train, test, val and testval.