![]()
Python package for analyzing Telegram chats and finding correlations between people

![]()
BibaAndBoba is a tool for analyzing files containing Telegram chat history.
It will allow you to identify the so-called parasite words for each person you are talking to, and will also allow you to find the correlation coefficient between your two interlocutors. Such a coefficient represents the probability that these two people communicate with each other.
This approach is based on the fact that people tend to adopt the words used by the interlocutor.
First you have to install the BibaAndBoba package using pip
$ pip install BibaAndBobaYou can also install BibaAndBoba from source, though this is usually not necessary
$ git clone https://github.com/andylvua/BibaAndBoba.git
$ cd bibaandboba
$ python setup.py install
$ pip3 install -e requirements.txtBiba and Boba uses JSON-serialized Telegram chat history files. This paragraph will help you select the chats for analysis and prepare all the necessary files.
Analysis requires at least 2 chats to find parasite words. One chat will be used as the base and the other will be used as an auxiliary to identify words that are unique to your interlocutor.
Note
For a correct analysis, the auxiliary chat should be selected in such a way that this person communicates as little as possible with the one you want to analyze. This is due to the fact that BibaAndBoba singles out the parasite words by taking away words that are quite common among all people. Auxiliary chat is needed just to find such. This task is quite tricky as the common words are different for each language, each age group of people, etc.
It takes at least 3 chats, preferably 4, to find the correlation coefficient between two people. 2 of them are with people, the correlation between which you want to find, and 2 auxiliary chats, chosen according to the principle described above.
If you know a person who does not communicate with any of the ones you want to analyze, you can use the chat with them as an auxiliary one for both base chats. However, remember that such approach will still reduce the accuracy of the analysis, so choose a different support chat for each individual if possible.
- Navigate to the chat you want to analyze.
Find the three dots menu, and select the Export chat history option:
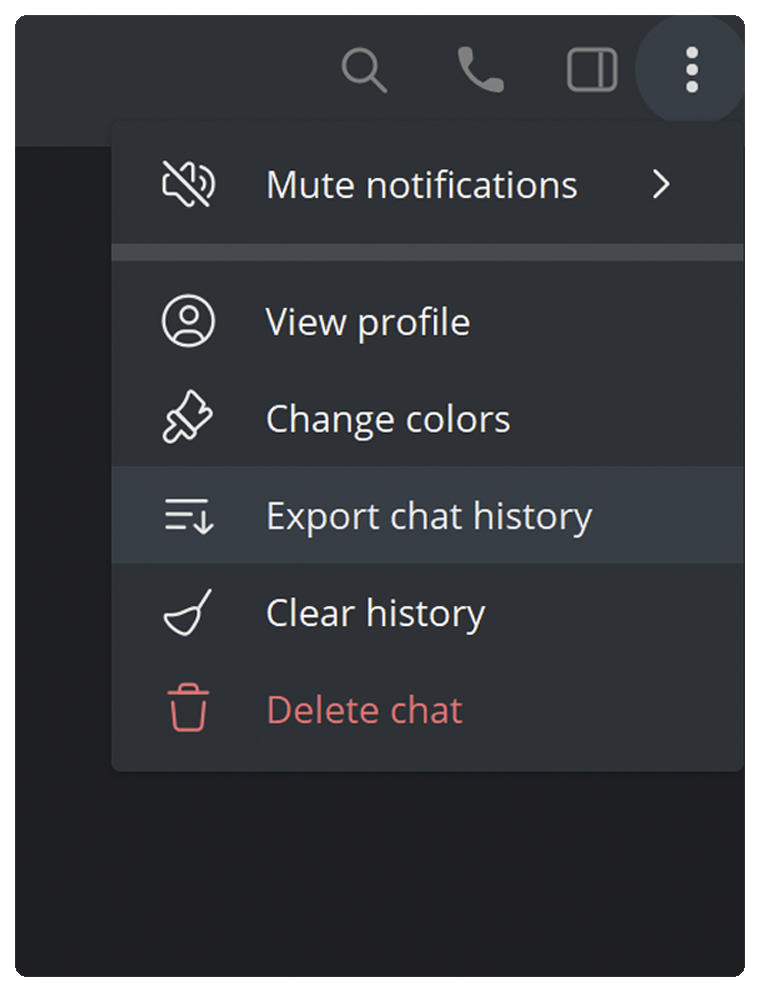
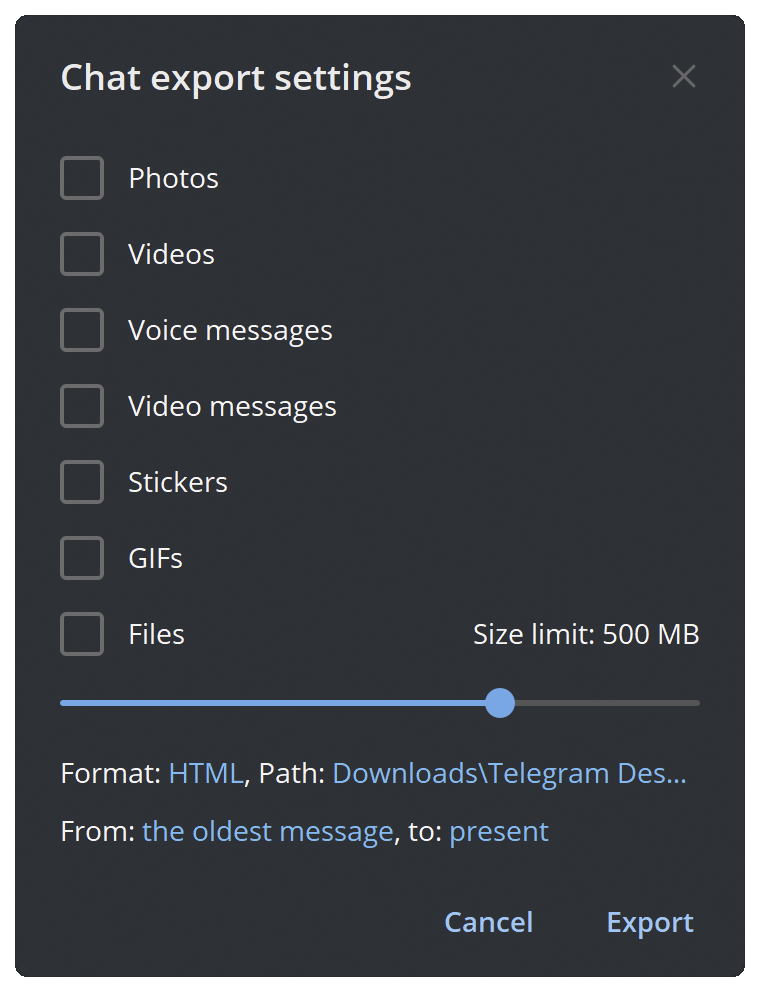
- Configure chat export settings as shown below.
- Disable the
Photosoption. - Set
Size limitto 500 MB.
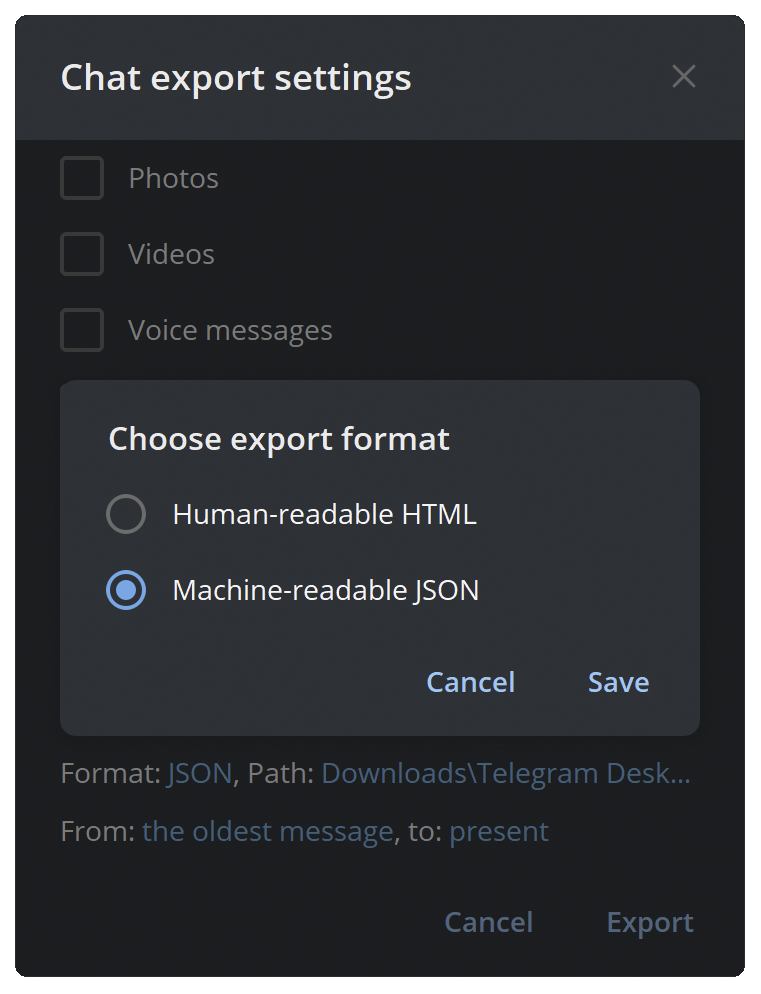
- Set
FormattoMachine-readable JSON. - Set
Pathto your desired export directory.
Click Export and wait for the export to finish.
The file that will be used for analysis will be located in the path
you selected under the name result.json
I recommend to immediately rename the source files to the name of your interlocutor for your convenience. For example, if you export a chat with Pavlo, rename the file
result.jsontopavlo.json.
Now we are ready to go.
Assuming you have the following project structure:
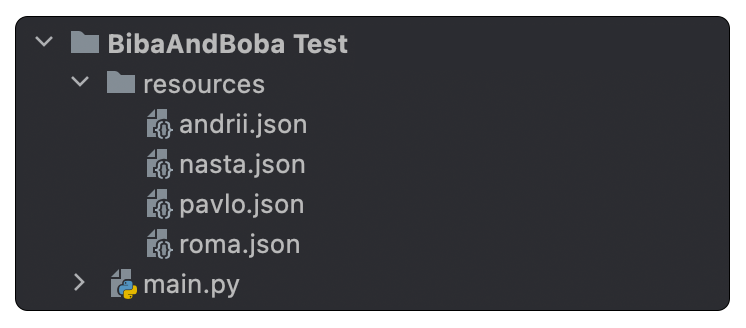
For example, you want to find words that Pavlo uses often. At the same
time, you know that the Roma hardly or not at all communicate with him - see How to choose chats.
BibaAndBoba uses the BibaAndBoba
class to analyze chat history files.
from BibaAndBoba import BibaAndBoba
def main():
pavlo = BibaAndBoba("resources/pavlo.json", "resources/roma.json")
print(pavlo.parasite_words())
if __name__ == "__main__":
main()It's pretty easy to do.
Create 2 objects for the people you want to find the correlation between
and pass them to the
Comparator class using the get_correlation() method.
from BibaAndBoba import BibaAndBoba, Comparator
def main():
pavlo = BibaAndBoba("resources/pavlo.json", "resources/roma.json")
andrii = BibaAndBoba("resources/andrii.json", "resources/nasta.json")
correlation = Comparator(pavlo, andrii).get_correlation()
print(correlation)
if __name__ == "__main__":
main()ReadTheDocs - Here you can find the complete documentation of the classes and methods used by BibaAndBoba
The MIT License (MIT)
Copyright © 2022, Andrew Yaroshevych