

Time: 50 minutes. Difficulty: Intermediate. Start Building!
Learn to build your own NLP text classifier and expose it as an API: an interactive workshop featuring
- AI-based text analysis with Tensorflow/Keras
- Astra DB, a Database-as-a-Service built on Apache Cassandra™
- FastAPI, the high-performance Python framework for creating APIs
- lots of useful Python libraries and packages (
pandas,pydantic,dotenv,sklearn,uvicorn, ...)

- prepare the labeled dataset for model training;
- train the model to classify any input text;
- export the trained model and test it interactively;
- create your free NoSQL database for data storage;
- set up and start an API exposing the classifier as a reusable class;
- learn how to speed up the API with DB-based caching;
- inspect how a streaming response is handled in the API.
- FAQ
- Credits/Acknowledgements
- Resources & Homework
- Create your Astra DB instance
- Load the project into Gitpod
- Train the model
- Expose as API
- Use the API
- Homework instructions
- Can I run the workshop on my computer?
You don't have to, you can do everything in the cloud from the comfort of your browser! But there is nothing preventing you from running the workshop on your own machine. If you do so, you will need
gitinstalled on your local system;- Python v3.6+ installed on your local system.
In this readme, we try to provide instructions for local development as well - but keep in mind that the main focus is development on Gitpod, hence we can't guarantee live support about local development in order to keep on track with the schedule. However, we will do our best to give you the info you need to succeed.
- What other prerequisites are there?
- You will need a GitHub account;
- You will also need an Astra account: don't worry, we'll work through that in the following.
- Do I need to pay for anything for this workshop?
- No. All tools and services we provide here are FREE.
- Will I get a certificate if I attend this workshop?
Attending the session is not enough. You need to complete the homeworks detailed below and you will get a nice participation certificate a.k.a. badge.

The core of this workshop is an adaptation from the excellent content "AI as an API," created by CodingEntrepreneurs. You are very much encouraged to watch it, as it touches on more topics and includes steps that unavoidably had to be taken out when converting to this shorter format.
However, the opposite is also true: the code you'll see here is almost completely rewritten from scratch, generally using different tools or techniques; the API has a different structure and offers different endpoints, which better fit the particular pedagogical intent we had in mind and highlight some best practices for using databases such as Cassandra for storage.
So, all in all, you'd be better off by watching both contents!
It doesn't matter if you join our workshop live or you prefer to work at your own pace, we have you covered. In this repository, you'll find everything you need for this workshop:
![]()
Don't forget to complete your assignment and get your verified skill badge:
- Do all practice steps described below until you can query your API running in Gitpod.
- Now roll up your sleeves and modify the code as follows: add an endpoint that exposes the neural net configuration of the classifier model. See below for detailed explanations.
- Take a SCREENSHOT of requests/responses showing the new endpoint at work. Note: you will have to restart the API for the changes to take effect.
- Submit your homework here.
That's it, you are done! Expect an email in a few days!
You will now create a database with a keyspace in it (a keyspace can contain tables). The API needs a couple of tables for persistent storage: they will be created programmatically on startup if they don't exist, so there's no need to worry too much about them.
Besides creating the database, you need to retrieve a couple of codes and assets for the API to be able to connect to it in a secure and authenticated way.
ASTRA DB is the simplest way to run Cassandra with zero operations at all - just push the button and get your cluster. No credit card required, $25.00 USD credit every month, roughly 20M read/write operations and 80GB storage monthly - sufficient to run small production workloads.
 Start by Ctrl-clicking on the orange button (to open in a new tab)
and then follow the instructions below:
Start by Ctrl-clicking on the orange button (to open in a new tab)
and then follow the instructions below:

- create an Astra DB instance as explained here, with database name =
workshopsand keyspace =spamclassifier; - generate and download a Secure Connect Bundle as explained here. You will later upload the bundle file to Gitpod;
- generate and retrieve a DB Token as explained here. Important: use the role "DB Administrator" for the token. You will later need the "Client ID" and "Client Secret" for this token.
Moreover, keep the Astra DB dashboard open: it will be useful later. In particular you may find it convenient to have the CQL Console within reach (click on your database on the left sidebar, then locate the "CQL Console" tab in the main panel).
Gitpod is an IDE in the cloud (modeled after VSCode). It comes with a full "virtual machine" (actually a Kubernetes-managed container), which you will use as if it were your own computer (e.g. downloading files, executing programs and scripts, training the model and eventually starting the API from it).
The button below will:
- spawn your own Gitpod container;
- clone this repository in it and open it in the IDE;
- preinstall the required dependencies.
ctrl-click on the Gitpod button to make sure you "Open in new tab"
(Note: you may have to authenticate
through Github in the process):

In a few minutes, a full IDE will be ready in the browser, with a file
explorer on the left, a file editor on the top
(with this very README open for convenience), and a console (bash) below it.
Actually two consoles will be spawned for later convenience, one called api-shell
and the other simply bash.
If you want to work on your laptop, make sure you install all Python dependencies listed in
requirements.txt(doing so in a Python virtual environment is strongly suggested) and add the main repo root to thePYTHONPATH. (You might see "errors" related to mismatching versions between thetensorflowpackage and others, notablynumpy: you should be able to ignore them and just go ahead.) If you are on Python 3.6, you will additionally need to install thedataclassespackage (i.e.pip install dataclasses). Also, please note that the model training phase may take much longer than ten minutes, depending on your processing power.
Show me a map of the Gitpod starting layout

- File explorer
- Editor
- Panel for console(s)
- Console switcher
There are many more other features, probably familiar to those who have experience with VSCode. Feel free to play around a bit!
The goal of this phase is to have your text classifier model ready to be used: that means, not only will you train it on a labeled dataset, but also you will take care of exporting it in a format suitable for later loading by the API.
Open the file training/dataset/spam-dataset.csv and have a look
at the lines there. (Tip: you can open a file in Gitpod by locating
it with the "File Explorer" on your left, but if you like using the keyboard
you may simply issue the command gp open training/dataset/spam-dataset.csv
from the bash Console at the bottom.)
This is a CSV file with three columns (separated by commas):
- whether the line is spam or "ham" (i.e. the opposite of spam),
- a short piece of text (a "message"),
- the tag identifying the source of this datapoint (this will be ignored by the scripts).
The third column betrays the mixed origin of the data: in order to create a labeled dataset of around 7.5K messages marked as spam/ham, two different (publicly available) sets have been merged (namely this one and this one, made available by the UCI Machine Learning Repository).
Luckily, the (not always fun) task of cleaning, validating and normalizing the heterogeneous (and usually imperfect) data has been already done for you -- something that is seldom the case, alas, in a real-world task.
Look at line 352 of this file for example: is that message spam or ham? (Tip: hit Ctrl-G in the Gitpod editor to jump to a specific line number.)
Show me that line in Gitpod's editor

Note: this step can be run either as an interactive Jupyter notebook or as ordinary Python script: the two will achieve the same effect. See instructions below for starting and executing the notebook.
You want to "teach" a machine to distinguish between spam and ham: unfortunately, machines prefer to speak numbers rather than words. You then need to transform the human-readable CSV file above into a format that, albeit less readable by us puny humans, is more suited to the subsequent task of training the classifier. You will express (a cleaned-out version of) the text into a sequence of numbers, each representing a token (one word) forming the message text.
More precisely:
- first you'll initialize a "tokenizer", asking it to build a dictionary (i.e. a token/number mapping) best suited for the texts at hand;
- then, you'll use the tokenizer to reduce all messages into (variable-length) sequences of numbers;
- these sequences will be "padded", i.e. you'll make sure they end up all having the same length: in this way, the whole dataset will be represented by a rectangular matrix of integer numbers, each row possibly having leading zeroes;
- the "spam/ham" column of the input dataset is recast with the "one-hot encoding": that is, it will become two columns, one for "spamminess" and one for "hamminess", both admitting the values zero or one (but with a single "one" per row): this turns out to be a formulation much friendlier to categorical classification tasks in general;
- finally you'll split the labeled dataset into a "training" and a "testing" disjoint parts. This is a very important concept: the effectiveness of a model should always be validated on data points not used during training.
All these steps can be largely automated by using data-science Python packages
such as pandas, numpy, tensorflow/keras.
The above steps can be accomplished by launching the following Python script
(which you should open and dissect line by line to learn more):
python prepareDataset.py -v
(the -v stands for "verbose": you will see some sample values and
various objects being printed as the script progresses, which will
shed more light on what kind of transformations exactly are taking place).
Note: don't worry if you see a message such as
Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory. It just means that this environment lacks the CUDA libraries, hence most Tensorflow tasks will be considerably slower than on a GPU. If you work on your laptop, you may want to switch to using a GPU for the training task, if you have the option to do so.
The dataset preparation starts with the CSV file you saw earlier
and ends up exporting the new data format in the training/prepared_dataset
directory. Two observations are in order:
- the "big matrix of numbers" encoding the messages and the (narrower) one containing their spam/ham status are useless without the tokenizer: after all, to process a new message you would need to make it into a sequence of numbers using the same mapping. For this reason, it is important to export the tokenizer as well, in order to later use the classifier.
- the
pickleprotocol used in writing the reformulated data is strictly Python-specific and should not be treated as a long-term (or interoperable!) format. Please see next step (below) for a sensible way to store model, tokenizer and metadata on disk.
Try to have a look at the pickle file created by the prepareDataset.py script. Well,
it's a binary file indeed, and there is not much to be seen there. Let's move along.
If you want a more interactive experience, the dataset preparation
is also available as a notebook: this gives you the possibility to run
the steps one at a time and explore the contents of the variables you create,
to better understand the transformations that occur. The notebook, once executed,
will result in the very same pickle file being created as the ordinary Python
script.
Show me the steps (alternative to invoking the script)
There are a couple of differences if you work locally (L) or on Gitpod (G):
- Install jupyter in the virtual environment (
pip install jupyter==1.0.0); - go to the
notebookdirectory (cd notebook) in your console; - (G) start Jupyter with
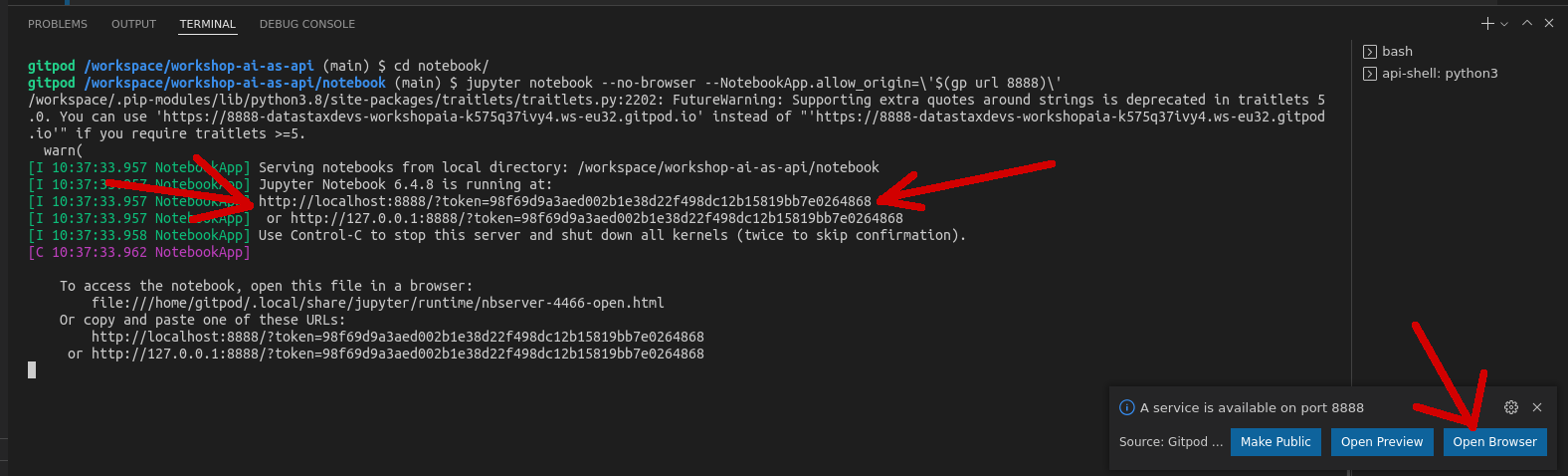
jupyter notebook --no-browser --NotebookApp.allow_origin=\'$(gp url 8888)\': you'll see some output on console; - (G) There should be a small popup in Gitpod saying "a service is available on port 8888". Click "Open browser", then check your popup blocker to have the Jupyter UI open in a new tab. Alternatively:
- (G) look for
"Jupyter Notebook 6.4.8 is running at: http://localhost:8888/?token=<something>"at the beginning of the output, and take note of the URL given there; - (G) in the
bashconsole, typegp preview http://localhost:8888/?token=<something>(replacing the URL with the one found above); - (G) the mini-browser will not display the page correctly, so hit the "Open site in new window" button: the Jupyter UI should open in a new tab;
- (L) start Jupyter with
jupyter notebook: a browser window should open; - click on
prepareDataset.ipynbto open it; - (G) do not worry about the "Not trusted" notice next to the title bar: the cells would run nevertheless;
- you can now Shift-Enter to execute all cells. There are cells with the sole purpose of inspecting the contents of some variables: take your time, use them to better understand what's going on;
- when you are finished, choose "Close and Halt" from the notebook "File" menu;
- now close main Jupyter the browser tab and stop the notebook backend that was running in the console (
Ctrl-C+yfor confirmation); - finally go back to the repo root with
cd ..in the console.
It is time to train the model, i.e. fit a neural network to the task of associating a spam/ham label to a text message. Well, actually the task is now more like "associating probabilities for 0/1 to a sequence of integer numbers (padded to fixed length with leading zeroes)".
The code for creating and training the model is very short (a handful of lines of code,
excluding loading from disk and writing to it), but running it will take several minutes:
launch the script
python trainModel.py
and wait for it to finish (it will take probably twelve minutes or so on Gitpod, possibly more on your own computer, depending on the specs).
The training script works as follows:
- all variables created and stored in the previous steps are loaded back to memory;
- a specific architecture of a neural network is created, still a "blank slate" in terms of what it "knows". Its core structure is that of a LSTM (long-short-term-memory), a specific kind of recurrent neural network with some clever modifications aimed at enhancing its ability to "remember" things between non-adjacent locations in a sequence, such as two displaced positions in a string of text;
- the network (your classifier) is trained: that means it will progressively adapt its internal (many thousands of) parameters in order to best reproduce the input training set. Each individual neuron in the network is a relatively simple component - the "intelligence" coming from their sheer quantity and the particular choice of parameters determining which neurons affect which other and by how much;
- Once the training process has finished, the script carefully saves everything (model, tokenizer and associated metadata) in a format that can be later loaded by the API in a stand-alone way.
Show me Gitpod during training
Training progresses in "epochs", each epoch representing a complete sweep through the input dataset. Several metrics are printed during training:
accuracy: this is the fraction of predictions that match the labeled input (higher is better);loss: the value of the "loss function", which measures how close are the predictions to the input data (lower is better). The precise definition of the loss function is derived from information theory: the idea is to quantify "departure from ideal predictions" fairly in all directions and in a way that favors gradual improvement of the parameters. In our case, we employ the "categorical cross-entropy" loss function, particularly suitable for models that choose between two or more output labels;val_accuracy,val_loss: the same quantities as above, but calculated at end of epoch on the validation dataset (i.e. theX_testandy_testportion of the input labeled data).

Perhaps by now the training process is completed and everything has been
saved in the training/trained_model_v1 directory (Note: it's advisable to keep a version
number in the model to be able to seamlessly switch to a newer classifier, or even
hypothetically to expose several of them at once in a single API).
Take a look in the output directory: there should be
- a (small) JSON file with some metadata describing some features of the model;
- a (larger) JSON file containing the full definition of the tokenizer. This has been created, and will be loaded, using helper functions provided with the tokenizer itself for our convenience;
- a (rather large) binary file containing "the model". That means, among other things, the shape and topology of the neural network and all "weights", i.e. the parameters dictating which neurons will affect which others, and by how much. Saving and loading this file, which is in the HDF5 format, is best left to routines kindly offered by Keras.
Note: if it is not possible to train the model (it takes too long, or the hardware resources are not enough, whatever), no fear! You will still be able to complete the practice and play with the API using a lightweight mock model class. Just remember, when starting the API, to edit the
.envfile so that it readsMOCK_MODEL_CLASS="0".
Before moving on to the API section, make sure that the saved
trained model is self-contained: that is, check that by loading
the contents of training/trained_model_v1, and nothing else, you are able
to perform meaningful estimates of the spam/ham status for a new arbitrary
piece of text.
The script loadTestModel.py does exactly that: it loads the saved model
and uses that to "predict" the ham/spam labels for new texts. Try it with
python loadTestModel.py
or even, if you feel creative, something like
python loadTestModel.py This is my example sentence and let us see if this is ham
Note that the output is given in terms of "probabilities", or "confidence":
one can interpret a result like {'ham': 0.92, 'spam': 0.08} as meaning
the input is ham with 92% confidence. Indeed, generally speaking,
ML-based classifiers are very sophisticated and specialized machines
for statistical inference.
If you look at the (very simple) code of this function, you will see how the
model, once loaded, is used to make predictions (it all boils down to the model's
predict method, but first the input text must be recast as sequence of numbers
with the aid of the tokenizer,
and likewise the result must be made readable by humans again).
Note: the model lends itself very well to processing several input texts in parallel (which generally is a big advantage in terms of performance); this fact will be exploited in the API as well. Can you see where this is apparent in this test code?
Tell me the answer
Answer: The function predictSpamStatus always receives a single text as input,
but this text is made into a one-element list before encoding as numbers
(pTokenizer.texts_to_sequences([text])). Much in the same way,
once the model has emitted its prediction, the code gets the first (and only)
element of a list of results (yOutput[0]).
Just by looking at these manipulations one can guess that multiple texts can be processed in parallel with negligible changes to the code, which indeed turns out to be the case.
Now your model is trained and saved to disk, ready to be used. It is time to expose it with FastAPI in the form of easy-to-use HTTP requests.
You'll first look at a minimal version of the API, just to get a taste of how FastAPI works, and then turn to a full-fledged version, with more endpoints and a database-backed caching layer.
Remember the "Secure Connect Bundle" you downloaded earlier from the Astra DB UI? It's time to upload it to Gitpod.
If you work locally, skip the upload and just be aware of the path to it for what comes next in the
.envfile.
Locate the file on your computer using the "finder/explorer".
Drag and drop the bundle into the Gitpod explorer window: make sure you drop it on the
file explorer window in Gitpod.
Show me how to drag-and-drop the bundle to Gitpod

As a check, you may want to verify the file is available in the right location with:
ls -lh secure-connect-*.zip
The output should tell you the exact file name (you can also make sure the file size is around 12KB while you are at it).
Now you must prepare a dot-env file containing the configuration required by the API (directory names, paths and, most important, the parameters to access the Astra DB persistence layer).
Make a copy of the example environment file and open it in the editor with
cp .env.sample .env
gp open .env
Most of the settings in this file are already filled for you (they will be picked up by the API as you start it).
Important: Make sure you paste your App ID and App Secret obtained earlier with the
Astra DB Token in the ASTRA_DB_CLIENT_ID and ASTRA_DB_CLIENT_SECRET variables
(keep the quotes and don't leave spaces around the equal sign).
As for the ASTRA_DB_KEYSPACE and ASTRA_DB_BUNDLE_PATH settings, you probably
don't need to worry (they must match the keyspace you created earlier in the
database and the location and file name of the Secure Connect Bundle you just
uploaded to Gitpod, respectively.)
Show me what the dot-env file might look like

If you don't have (or don't want to use) the actual trained model at hand, you can switch to a lightweight mock by setting
MOCK_MODEL_CLASS="0"in this dot-env file. The API part of the practice would "not even notice the change".
Now that the trained model is there, the .env file is ready and the
secure bundle is in place, you can start a minimal form of the API with:
uvicorn api.minimain:miniapp --reload
In this command, you are telling
uvicorn(an ASGI server capable of running asynchronous Python APIs) to launch theminiappAPI found in theminimainmodule; you also ask it to keep a watch on all involved files and auto-reload on any file change.
After some (rather verbose) output from Tensorflow, you should see the
INFO: Application startup complete. notice: the API has loaded the classifier
and is ready to accept
requests (on localhost and port 8000, as per defaults).
You will first fire some requests and then have a quick look at how
the code is structured.
Note that this code is purposefully kept very simple: besides not implementing all the features, it also refrains from using some of the facilities provided by FastAPI to better focus on the basics. Look at the full API below for a more comprehensive usage of the framework.
You'll use the command-line tool curl to issue simple HTTP requests at your
running API (but, of course, any tool capable of doing GETs and POSTs would do).
While the API is running, switch to the other bash console in Gitpod (using
the console switcher at the bottom right of your IDE) and try the following command:
curl -s http://localhost:8000 | python -mjson.tool
This issues a GET request to the "/" API endpoint. The result is a small
summary, in JSON form, of some of the API parameters inherited through the
.env file.
The logic to retrieve these settings and make them available to the API
is in the config.py module and relies on the pydantic package,
that excels at data validation while allowing for surprisingly short and clean
code. pydantic pairs very well with FastAPI (documentation).
If you are feeling adventurous, try stopping the API (Ctrl-C in the API shell) and re-starting as
API_NAME="Fire Dragon!" uvicorn api.minimain:miniapp --reload. Try again the abovecurlcommand to see the redefined environment variableAPI_NAMEtaking precedence over the dot-env file.
This minimal API already accomplishes the basic task for today: namely,
it makes the spam classifier available as an API. Let's try with some POST requests:
# single-text endpoint
curl -s -XPOST \
localhost:8000/prediction \
-d '{"text": "Click TO WIN a FREE CAR"}' \
-H 'Content-Type: application/json' | python -mjson.tool
# multiple-texts endpoint
curl -s -XPOST \
localhost:8000/predictions \
-d '{"texts": ["Click TO WIN a FREE CAR", "I like this endpoint"]}' \
-H 'Content-Type: application/json' | python -mjson.tool
That's it: the API correctly receives requests, uses the model to get predictions (i.e. spam/ham scores for each message), and returns them back to the caller.
Show me what the output could look like
Note: since training is a randomized process, the actual numbers you will obtain will not necessarily match what you see here. But you can expect a broad agreement, with the first text being seen as "spam" with at least 80% confidence and the second one being labeled "ham" at least as clearly.

What is running now is a basic API architecture, which makes use of just the fundamental features of FastAPI: you will shortly launch a more sophisticated one. But first we want to make some observations on the code structure:
The main object is the FastAPI instance called miniapp: this exposes a
decorator that can be used to attach a Python function
to an API endpoint
(see e.g. the @miniapp.get('/') preceding the function definition).
FastAPI will try to match the function arguments with the request parameters.
To make this matching more effective, and gain input validation "for free" with
that, the code defines "models" in the pydantic sense and specifies them as the types
for the endpoint functions. Try to invoke the API as follows and see what happens
(note the empty body):
curl -v -s -XPOST \
localhost:8000/prediction -d '{}' \
-H 'Content-Type: application/json' | python -mjson.tool
The core of the API, the classifier model, is conveniently wrapped into a separate
class, AIModel, that takes care of loading from files and predicting; it also
performs the necessary conversions to offer a friendlier interface to the caller.
The model is instantiated within a special @miniapp.on_event("startup")
utility decorator offered by FastAPI which
is used to "register" some operations, effectively scheduling them for execution
as soon as the rest of the API is loaded. Then, the model will live as a global
variable accessible from the various endpoint functions.
Note: have a look at the class in AIModel.py: there is nothing specific
to spam classification there. Indeed, this is a widely reusable class, that can
load and expose any text classifier based on a similar tokenizer-then-predict
structure as it is.
You can now stop the minimal API (Ctrl-C in its console) and get ready to start the full API. This is your "production-ready" result and, as such, has many more nice features that we will now list (just giving pointers for those interested in knowing more):
Tell me about the nice features of this API
In general, running a classifier on some input can be expensive in terms of CPU and time. Since, once the model is trained, predictions are deterministic, it would make sense to introduce a caching mechanism, whereby texts that were already processed and cached are not computed again.
You happen to have a database, our Astra DB instance, and you'll use it to store all predictions for later querying and retrieval. To do so, you need: a table, containing processed text data; a connection to the database, that will be kept alive throughout the life of the API; and methods to write, and read, entries in that table.
Technically, you will use the Cassandra Python drivers, and in particular
the Object Mapper facility
they offer. Look into api/database/*.py:
there is a module that sets up the connection, using the secrets found in the .env,
and another where the models are defined - in particular the SpamCacheItem model, representing an entry in the cache.
The database initialization will go together with the spam-model loading into
the API "startup" hook.
Note that there is no need to explicitly create the table: creation,
when needed, is handled
automatically by the sync_table calls in the onStartup() method.
This table is a Cassandra table: we have modeled it according to the query it needs to support. In this case that means that "model version" and "input text" form the primary key (also partition key), and the prediction outputs are additional data columns. (Note: using the object mapper, the structure of the table is implied in the attributes given to the fields in the corresponding model).
At this point, the endpoint functions can use the cachePrediction and
readCachedPrediction functions to look for entries in the cache and store them.
Note that caching introduces a nontrivial possibility in the multi-input endpoint:
namely, only some of the input texts may be cached: as a demonstration, and assuming
the cost of computation is way higher than the cost of development/maintenance
(which in many cases is true, especially with ML!), the code goes to great lengths
to ensure this is handled sparingly and transparently to the caller. See the logic
in multiple_text_predictions for the details.
We all love well-documented APIs. And FastAPI makes it pretty easy to do so:
- when instantiating the main
FastAPIobject, all sorts of properties (version number, grouping of endpoints, API title and so on) can be passed to it; - docstrings in the endpoint functions, and even the function names themselves, are known to FastAPI;
- additional annotations can be passed to the endpoint decorators, such as the expected structure of the response JSON (for this reason, we took the extra care of defining
pydanticmodels for the responses as well, for instancePredictionResult).
This is all used by FastAPI to automatically expose a Swagger UI that makes it easy to experiment with the running API and test it (you'll later see how this makes developers' lives easier). Also a machine-readable description of the API conforming to the OpenAPI specifications is produced and made available.
Caching is not the only use you'll make of a database: also all text classification requests are logged to a table, keeping track of the time, the text that was requested and the identity of the caller.
This may be useful, for instance, to implement rate limiting; in this API you simply expose the datum back to the caller, who is able to issue a request such as
curl -s http://localhost:8000/recent_log | python -mjson.tooland examine their own recent calls.
The problem is, in principle this may be a huge list, and you do not want to have it all in memory on the API side before sending out a giant response to the caller. Especially considering the data from the database will be paginated (in a way that is handled automatically for us by the Cassandra drivers' object models).
So what do you do here? It would be nice to start streaming out the API response
as the first chunk of data arrives from the database ... and that is exactly what we do,
with the StreamingResponse construct provided by FastAPI.
The idea is very simple: you wrap something like a generator with StreamingResponse and FastAPI handles the rest.
In this case, however, you want the full response to also be a valid JSON, so you do some tricks to ensure that
(taking care of the opening/closing square brackets, to avoid a trailing comma at end of list, etc).
In practice the full JSON response is crafted semi-manually (see function formatCallerLogJSON for the gory details).
For a look at the structure and contents of the database table with the call log data, and a short account on the reason for that choice, see below (section "Inspect the database").
For illustrative purposes, the API also has a GET endpoint for requesting
(single-)text classification. A useful feature is that the pydantic models
declared as endpoint dependencies will be filled also using query
parameters, if they are available and the names match. In this way, the
GET endpoint will work, and will internally be able to use a SingleTextQuery,
even when invoked as follows (try it!)
curl -s \
"localhost:8000/prediction?text=This+is+a+nice+day&skip_cache=true&echo_input=1" \
| python -mjson.tool
(The way to have this mechanism working goes through the topic of dependency injection in FastAPI and in particular the "classes as dependencies" part. See here for more details on this).
Without further ado, it is time to start the full-fledged API.
Hit Ctrl-C in the API console (if you didn't already stop the "minimal API")
and launch the following command this time (you're now closer to "production",
so you do not want the --reload flag any more):
uvicorn api.main:app
The full API is starting (and again, after a somewhat lengthy output you will
see something like Uvicorn running on http://127.0.0.1:8000 being printed).
If the API cannot start and you see an error such as
urllib.error.HTTPError: HTTP Error 503: Service Unavailablewhile connecting to the DB, most likely your Astra DB instance is currently hibernated. In that case, just open the CQL Console on the Astra UI to bring your DB back to operation.
Quickly launch a couple of requests with curl on the bash console
(the same requests already sent to the minimal API earlier) and check the
output:
# get basic info
curl -s http://localhost:8000 | python -mjson.tool
This output has been enriched with the "ID of the caller" (actually the IP
the call comes from). To access this piece of information from within the route,
you make use of the very flexible dependency system offered by FastAPI, simply
declaring the endpoint function as having a parameter of type Request:
you will be then able to read its client member to access the caller IP address.
Note: when running behind a reverse-proxy one would have to configure the latter so that it makes use of the
X-Forwarded-Forheader, and it is that header instead that has to be read within the Python code. See this for more information.
Now for an actual request to process some text:
# single-text endpoint
curl -s -XPOST \
localhost:8000/prediction \
-d '{"text": "Click TO WIN a FREE CAR"}' \
-H 'Content-Type: application/json' | python -mjson.tool
Also this output is somewhat richer: there is an "input" field (not filled
by default) and, most important, a "from_cache" field - presumably false.
But, if you re-launch the very same curl command (try it!), the response
will have "from_cache" set to true: this is the caching mechanism at work.
You could play a bit more with the API, but to do so, let us move to a friendlier interface, offered for free by FastAPI: the Swagger UI.
In principle, you could access the Swagger UI by visiting http://127.0.0.1:8000/docs.
If you are running locally that's the URL you should open, end of story.
If you are working in Gitpod, however, the notion of "localhost" makes sense only within Gitpod itself. Luckily for you, Gitpod maps local ports to actual domain names (that can optionally be made publicly accessible as well).
To find out the URL for your docs, then, run this command in the bash shell:
echo `gp url 8000`/docs
and open the output URL in a new tab (it would look more or less
like https://8000-<something-something>.gitpod.io/docs).
You will see the Swagger UI: you can now browse the API documentation and even
try the endpoints out.
Show me the Swagger UI main page

Take a moment to look around: look at the details for an endpoint and notice that schema description are provided for both the payload and the responses.
Let's have some fun with the caching mechanism and the multiple-text endpoint. For this experiment you will borrow a few lines from a famous poem by T. S. Eliot.
First locate the /predictions endpoint, expand it and click "Try it out"
to access the interactive form. Edit the "Request Body" field pasting the
following:
{
"texts": [
"I have seen them riding seaward on the waves",
"When the wind blows the water white and black."
]
}
Click the big "Execute" blue button and look for the "Response body" below.
You will see that both lines are new to the classifier, indeed their from_cache
returns false.
Now add a third line and re-issue the request, with body
{
"texts": [
"I have seen them riding seaward on the waves",
"When the wind blows the water white and black.",
"By sea-girls wreathed with seaweed red and brown"
]
}
and check the response this time: the from_cache will have a true-true-false
pattern this time. (You can also try adding "skip_cache": true to the body
and see what happens to the response).
Finally, reinstate all lines of the stanza (so far only the odd ones were passed!):
{
"texts": [
"I have seen them riding seaward on the waves",
"Combing the white hair of the waves blown back",
"When the wind blows the water white and black.",
"We have lingered in the chambers of the sea",
"By sea-girls wreathed with seaweed red and brown",
"Till human voices wake us, and we drown."
]
}
How do the values of from_cache look like now? (well, no surprises here).
Take a look at the cache-reading logic in the multiple_text_predictions
function code in main.py. Sometimes it pays off to carefully avoid wasting CPU
cycles.
You can also try the recent_log endpoint in Swagger to have a (time-ordered)
listing of all the classification requests you issued recently.
As you saw earlier, behind the scenes this is a StreamingResponse and,
instead of relying on FastAPI to package your response as JSON, you manually
construct its pieces as the data arrives from the database.
Try the /recent_log
endpoint in Swagger and check the output matches your previous experiments.
Go back, for this endpoint, to the bash consoleas well,
and check the result of:
curl -s localhost:8000/recent_log | python -mjson.tool
Surprise! Most likely you are not seeing your Eliot lines being listed,
at least not on Gitpod (but you may see the calls you issued earlier with curl).
The reason is that requests coming from the Swagger UI pass through Gitpod's
port and domain mappings and appear to come from a different IP than those
from "the local localhost".
You may want to verify this by comparing the caller_id returned by the
Swagger invocation of the / endpoint and the result of
curl -s localhost:8000 | python -mjson.tool.
You can also directly look at the contents of the tables on Astra DB. To do so, an option is to use the "CQL Console" that is available in the browser within the Astra UI.
Choose your database in the Astra main dashboard and click on it;
next, go to the "CQL Console" tab in the main panel. In a few seconds the
console will open in your browser, already connected to your database and
waiting for your input.
Show me how to get to the CQL Console in Astra

Commands entered in the CQL Console are terminated with a semicolon (
;) and can span multiple lines. Run them with theEnterkey. If you want to interrupt the command you are entering, hitCtrl-Cto be brought back to the prompt. See here for more references to the CQL language commands.
Start by telling the console that you will be using the spamclassifier keyspace:
USE spamclassifier;
Which tables are there?
DESC TABLES;
List some sample records from the cache table:
SELECT * FROM spam_cache_items LIMIT 10;
And, similarly, look at the recent call log for the "localhost" caller:
SELECT * FROM spam_calls_per_caller
WHERE caller_id = '127.0.0.1'
AND called_hour='2022-02-23 17:00:00.000Z';
For the above to show results, you have to take care of adapting the date and (whole) hour to current time, and possibly the
caller_idcould be edited to reflect what you see from the Swagger/response.
The reason why the call log is partitioned in hourly chunks (and not only
by caller_id) has to do with the way the Cassandra database, on which Astra DB
is built, works: in short we do not want our partitions to grow indefinitely.
Unfortunately a thorough discussion of this topic would lead us too far away.
If you are curious, we strongly recommend you start from the exercises Data modeling by example
and What is Cassandra?.
You will embark on a long and exciting journey!
You are asked to add a new GET endpoint in the API that takes no arguments and returns a description of how the neural net of the spam classifier model is structured.
Luckily for you, the tensorflow/keras model (that gets loaded from disk within
the AIModel class at startup) already has a to_json() method that returns
a long JSON string similar to:
{
"class_name": "Sequential",
"config": {
"name": "sequential",
"layers": [
{
"class_name": "InputLayer",
"config": {
"batch_input_shape": [
null,
300
],
"dtype": "float32",
...
...
Your task is to expose this JSON object to the user, who might legitimately be interested in what choice of network topology is the classifier based on.
Show me how that could look like

So far, you've been running the API with uvicorn from the command line.
For a final deploy to production (on a Linux box), some last steps are missing.
These are not covered in the practice of this interactive workshops, however
we outline them here, assuming you are using nginx as reverse proxy,
and you do have a domain name (but no HTTPS configured):
First ensure your Python virtualenv, say spamclassifier, is available
on the server.
Second you will create a service file, /etc/systemd/system/spamclassifier.service,
tasked with keeping the uvicorn instance running. Here we assume the service manager is systemd.
[Unit]
Description= ...
After=network.target
[Service]
User=...
Group=...
WorkingDirectory=/path/to/repo_dir
# these may be here and override the .env
Environment="API_NAME=Deployed Spam Classifier"
ExecStart=/path/to/virtual/environments/spamclassifier/bin/uvicorn api.main:app --host 127.0.0.1 --port 9999 --workers 4
[Install]
WantedBy=multi-user.target
(9999 is an internal port you may choose at will, but it must match the file below;
4 is the number of workers uvicorn will spawn
and should be tuned to your predicted workload and the server capacity.
Note that you will have a set of resources, model and DB connection, per each worker).
Third, after starting the service (sudo systemctl daemon-reload && sudo systemctl start spamclassifier),
make your API known to nginx by creating a file /etc/nginx/sites-available/spamclassifier_api:
server {
listen 80;
server_name api.myspamclassifier.com;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_redirect off;
proxy_buffering off;
proxy_pass http://uvicorn_spamclassifier;
}
}
upstream uvicorn_spamclassifier {
server 127.0.0.1:9999;
keepalive 64;
}
Fourth, create a symlink to the above file in /etc/nginx/sites-available/ and restart nginx
(sudo systemctl restart nginx).
This should get the API running and accessible from outside. As mentioned earlier, to properly identify
the caller_id at API level, your code should be modified to inspect the X-Forwarded-For header
instead of the actual caller IP address. Access to request headers in FastAPI
is described here.