Simple Flask project that loads pandas dataframe into the database and shows the information on a page. Flask Pandas Dataframe is a one-file project that might help beginners to understand some basic Flask concepts:
- Create a simple Flask app
- Download a public pandas DF
- Create an SQLite DB and a table to save the information
- Load pandas in DB using a new
custom command - Visualize the data in the browser
Links
- 👉 Support - Provided by AppSeed
- 👉 More Open-Source Starters - actively supported and versioned
Pandas Dataframe - Console View
Pandas Dataframe - Browser View

$ # Clone sources
$ git clone https://github.com/app-generator/flask-pandas-dataframe.git
$ cd flask-pandas-dataframe
$
$ # Virtualenv modules installation (Unix based systems)
$ virtualenv env
$ source env/bin/activate
$
$ # Virtualenv modules installation (Windows based systems)
$ # virtualenv env
$ # .\env\Scripts\activate
$
$ # Install dependencies
$ pip3 install -r requirements.txt
$
$ # Create database via Flask CLI
$ flask shell
>>> from app import db # import SqlAlchemy interface
>>> db.create_all() # create SQLite database and Data table
>>> quit() # leave the Flask CLI
$
$ # Load the data into the database
$ flask load-data titanic-min.csv
$
$ # Set the FLASK_APP environment variable
$ (Unix/Mac) export FLASK_APP=run.py
$ (Windows) set FLASK_APP=run.py
$ (Powershell) $env:FLASK_APP = ".\run.py"
$
$ # Set up the DEBUG environment
$ # (Unix/Mac) export FLASK_ENV=development
$ # (Windows) set FLASK_ENV=development
$ # (Powershell) $env:FLASK_ENV = "development"
$
$ flask run
$ # access the app in the browser: http://localhost:5000- Flask - the framework used
- Pandas - an amazing
data analysislibrary - SQLAlchemy - Python SQL Toolkit and ORM
- Flask-SqlAlchemy - extension for Flask that adds support for SQLAlchemy
- Requests - simple HTTP library.
$ # Virtualenv modules installation (Unix based systems)
$ virtualenv env
$ source env/bin/activate
$
$ # Virtualenv modules installation (Windows based systems)
$ # virtualenv env
$ # .\env\Scripts\activate
$
$ # Install modules - SQLite Database
$ pip3 install -r requirements.txt$ # Enable the DEBUG environment
$ # (Unix/Mac) export FLASK_ENV=development
$ # (Windows) set FLASK_ENV=development
$ # (Powershell) $env:FLASK_ENV = "development"
$
$ # Set the FLASK_APP environment variable
$ (Unix/Mac) export FLASK_APP=app.py
$ (Windows) set FLASK_APP=app.py
$ (Powershell) $env:FLASK_APP = ".\app.py"The dataset is downloaded from a remote location and saved locally.
>>> import requests
>>> import pandas as pd
>>>
>>> # Define the remote CSV file
>>> csv_file = 'https://static.appseed.us/data/titanic.txt'
>>>
>>> # Download the file (via request library)
>>> r = requests.get( csv_file )
>>>
>>> # Save the content to a new LOCAL file
>>> f = open('titanic.csv', 'w')
>>> f.write( r.content.decode("utf-8") )
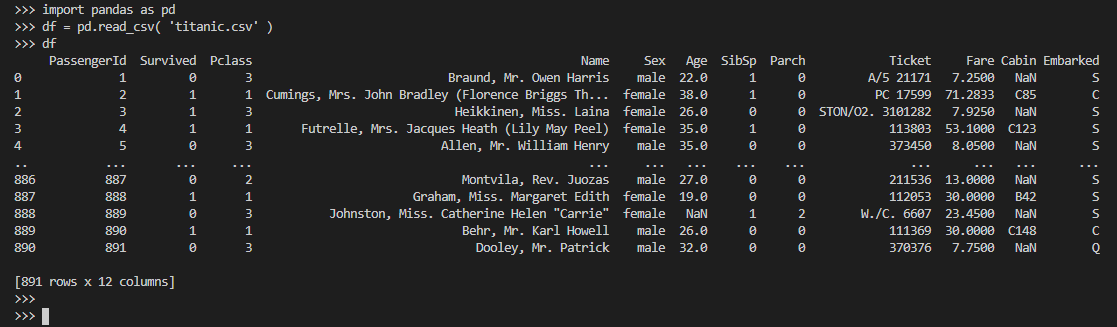
>>> f.close The RAW dataset has ~900 rows and we can inspect it with ease using pandas library
>>> import pandas as pd
>>>
>>> df = pd.read_csv( 'titanic.csv' )
>>> df
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
.. ... ... ... ... ... ... ... ... ... ... ... ...
886 887 0 2 Montvila, Rev. Juozas male 27.0 0 0 211536 13.0000 NaN S
887 888 1 1 Graham, Miss. Margaret Edith female 19.0 0 0 112053 30.0000 B42 S
888 889 0 3 Johnston, Miss. Catherine Helen "Carrie" female NaN 1 2 W./C. 6607 23.4500 NaN S
889 890 1 1 Behr, Mr. Karl Howell male 26.0 0 0 111369 30.0000 C148 C
890 891 0 3 Dooley, Mr. Patrick male 32.0 0 0 370376 7.7500 NaN QReturn columns data types in the DataFrame: df.dtypes. This informationis used to design a table where is information is loaded.
>>> df.dtypes
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked objectIntegrate SQLAlchemy and define a table to load the data.
# Store the Titanic sad stats
class Data(db.Model):
passengerId = db.Column(db.Integer, primary_key=True )
name = db.Column(db.String(250), nullable=False )
survived = db.Column(db.Integer, nullable=False )
sex = db.Column(db.String(10 ), default=None ) # name, female
age = db.Column(db.Integer, default=-1 )
fare = db.Column(db.Float, default=-1 )
# The string representation
def __repr__(self):
return str(self.passengerId) + ' - ' + str(self.name) Create the SQLite database and the new table via Flask CLI:
$ flask shell
App: app [development]
Instance: D:\work\repo-learn\python\how-to\instance
>>> from app import db
>>> db.create_all()At this point, we can inspect the database using SQLiteBrowser, an open-source and free editor for SQLite (the table is empty).
The information will be loaded into the database via a custom command = load-data. The command expects the input file as argument (CSV format).
# New import
import click
...
# Custom command
@app.cli.command("load-data")
@click.argument("fname")
def load_data(fname):
''' Load data from a CSV file '''
print ('*** Load from file: ' + fname)
# The functional part goes here
... To check the command is properly coded we can type flask --help in the terminal:
$ flask --help
Options:
--version Show the flask version
--help Show this message and exit.
Commands:
load-data Load data from a CSV file <-- NEW Command
routes Show the routes for the app.
run Run a development server.
shell Run a shell in the app context.- Flask - the framework used
- Pandas - an amazing
data analysislibrary - AppSeed - for support annd more samples
Flask Pandas Dataframe - Open-source sample provided by AppSeed App Generator.