v0.1.16
v0.1.16 bench
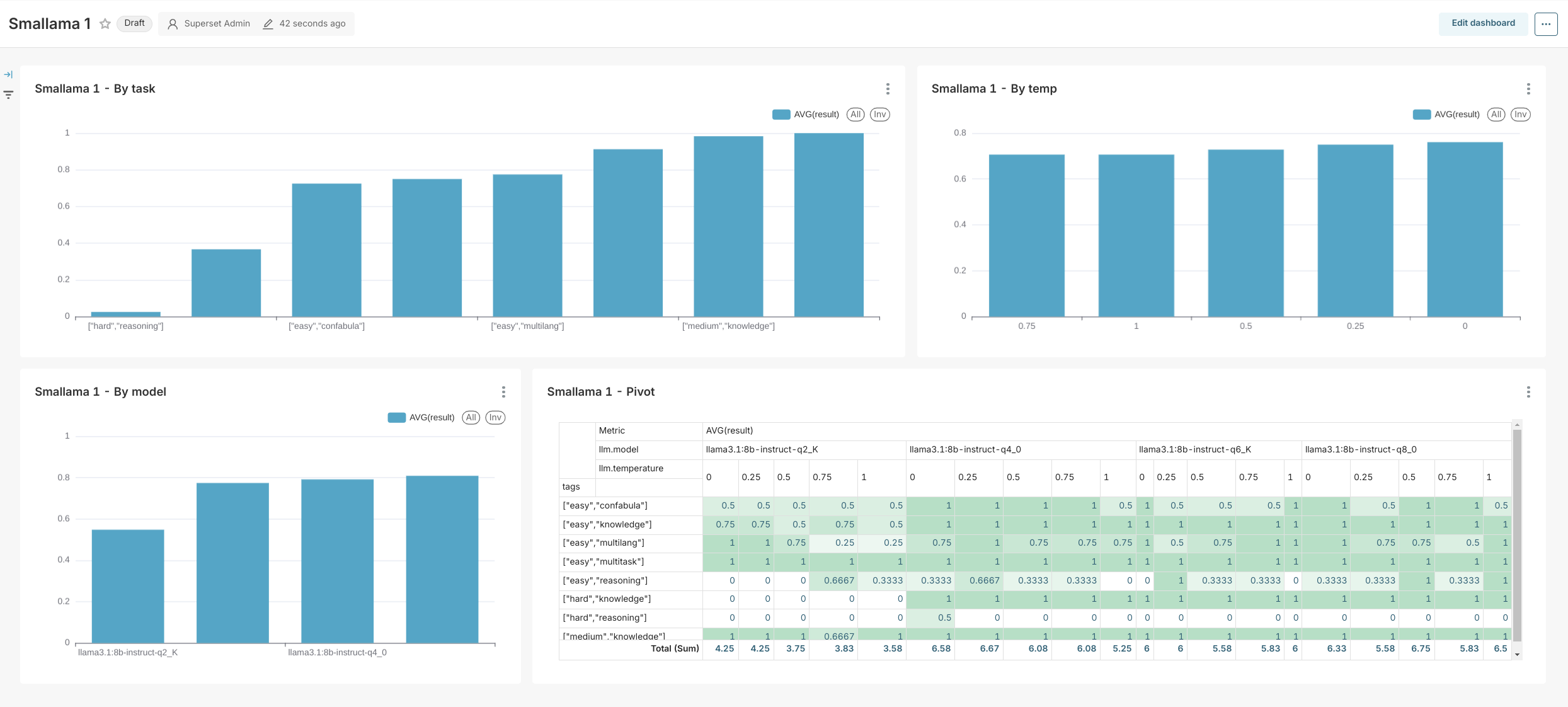
Something new this time - not an integration, but rather a custom-built service for Harbor.
bench is a built-in benchmark service for measuring the quality of LLMs. It has a few specific design goals in mind:
- Work with OpenAI-compatible APIs (not running LLMs on its own)
- Benchmark tasks and success criteria are defined by you
- Focused on chat/instruction tasks
# [Optional] pre-build the image
harbor build bench
# Run the benchmark
# --name is required to give this run a meaningful name
harbor bench --name bench
# Open the results (folder)
harbor bench results- Find a more detailed overview in the service docs
harbor doctor
A very lightweight troubleshooting utility
user@os:~/code/harbor$ ▼ h doctor
00:52:24 [INFO] Running Harbor Doctor...
00:52:24 [INFO] ✔ Docker is installed and running
00:52:24 [INFO] ✔ Docker Compose is installed
00:52:24 [INFO] ✔ .env file exists and is readable
00:52:24 [INFO] ✔ default.env file exists and is readable
00:52:24 [INFO] ✔ Harbor workspace directory exists
00:52:24 [INFO] ✔ CLI is linked
00:52:24 [INFO] Harbor Doctor checks completed successfully.Full Changelog: v0.1.15...v0.1.16