此项目是模仿的是七天用Go从零实现系列
这个系列让我学习到了很多!!感谢博主
语雀文档:https://www.yuque.com/docs/share/a3b7cc1a-12aa-4b42-bd6f-5e98ae8c080b?# 《🐹Gee框架》
这个教程将使用 Go 语言实现一个简单的 Web 框架,起名叫做Gee,geektutu.com的前三个字母。我第一次接触的 Go 语言的 Web 框架是Gin,Gin的代码总共是14K,其中测试代码9K,也就是说实际代码量只有5K。Gin也是我非常喜欢的一个框架,与Python中的Flask很像,小而美。
7天实现Gee框架这个教程的很多设计,包括源码,参考了Gin,大家可以看到很多Gin的影子。
时间关系,同时为了尽可能地简洁明了,这个框架中的很多部分实现的功能都很简单,但是尽可能地体现一个框架核心的设计原则。例如Router的设计,虽然支持的动态路由规则有限,但为了性能考虑匹配算法是用Trie树实现的,Router最重要的指标之一便是性能。
go中是内置了 http 库的。最原生的写web应用其实就是用的是 http 库
package main
import (
"fmt"
"log"
"net/http"
)
func main() {
http.HandleFunc("/", indexHandler)
http.HandleFunc("/hello", helloHandler)
log.Fatal(http.ListenAndServe(":9999", nil))
}
// handler echoes r.URL.Path
func indexHandler(w http.ResponseWriter, req *http.Request) {
fmt.Fprintf(w, "URL.Path = %q\n", req.URL.Path)
}
// handler echoes r.URL.Header
func helloHandler(w http.ResponseWriter, req *http.Request) {
for k, v := range req.Header {
fmt.Fprintf(w, "Header[%q] = %q\n", k, v)
}
}上面是最原生的写web应用的写法
http.HandleFunc("/", indexHandler) 这句话第一个参数是路由地址,第二个参数是绑定的逻辑函数。
http.ListenAndServe(":9999", nil) 是用来启动 Web 服务的,第一个参数是地址,:9999表示在 9999 端口监听。而第二个参数则代表处理所有的HTTP请求的实例,nil 代表使用标准库中的实例处理。第二个参数,则是我们基于net/http标准库实现Web框架的入口。
我们可以看看源码
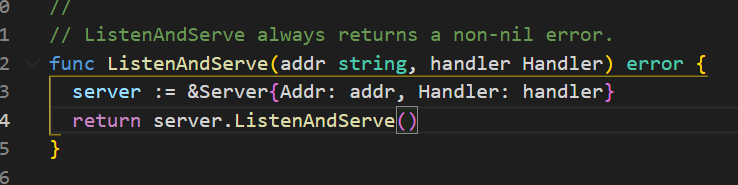
第二个参数就是 Handler 类型
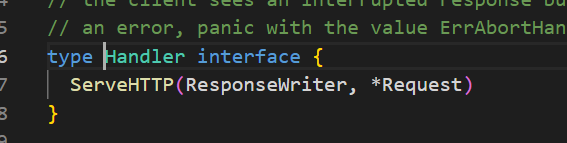
实现这样一个 ServeHTTP 接口
其实你也会发现你写的路由绑定的函数也是在变相的写 ServeHTTP 接口,因为参数都是一致的。
那么 http库根据web应用的原理可能是http.ListenAndServe(":9999", nil) 起的是web应用的入口,当你进行请求的时候,他会匹配路由,做对应对应的逻辑函数直到应用关闭,这一系列的工作都是在一个 Handler 实例完成,虽然此时传入的是 nil 但是你写的路由都挂载到了
根据上面的原理,我们就可以自己简单封装 http 库
package main
import (
"fmt"
"log"
"net/http"
)
// Engine is the uni handler for all requests
type Engine struct{}
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
switch req.URL.Path {
case "/":
fmt.Fprintf(w, "URL.Path = %q\n", req.URL.Path)
case "/hello":
for k, v := range req.Header {
fmt.Fprintf(w, "Header[%q] = %q\n", k, v)
}
default:
fmt.Fprintf(w, "404 NOT FOUND: %s\n", req.URL)
}
}
func main() {
engine := new(Engine)
log.Fatal(http.ListenAndServe(":9999", engine))
}- 我们定义了一个结构体
Engine,实现ServeHTTP的接口了,里面的逻辑就是在匹配路由,实现不同的逻辑工作。 http.ListenAndServe(":9999", nil)的第二个参数传入创建的Engine的实例。- 当你利用
curl工具进行测试时,你会发现,结果符合上诉猜测过程。
我们开始模仿gin框架,进行封装 http 库
地址:https://www.liwenzhou.com/posts/Go/import_local_package_in_go_module/
- 创建一个gee的文件夹,然后
go mod init gee生成go.mod - 在
demo的go.mod中写入
module one
go 1.16
require gee v0.0.0
replace gee => ../gee
- 在主文件中直接引入
gee - 在gee文件内创建文件
gee.go写入package gee就不会有报错了
package main
import (
"fmt"
"gee"
"net/http"
)
// type Engine struct{}
// func (engine *Engine) ServeHTTP(w http.ResponseWriter, r *http.Request) {
// switch r.URL.Path {
// case "/":
// fmt.Printf("Path%q", r.URL.Path)
// case "/hello":
// for k, v := range r.Header {
// fmt.Printf("Header[%q] = %q\n", k, v)
// }
// default:
// fmt.Fprintf(w, "404 NOT FOUND: %s\n", r.URL)
// }
// }
func main() {
// http.HandleFunc("/", indexHandler)
// http.HandleFunc("/hello", helloHandler)
// log.Fatal(http.ListenAndServe(":9999", nil))
//创建实例
r := gee.Default()
//下面就是路由 参照gin框架
r.GET("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Printf("Path=%q\n", r.URL.Path)
})
r.GET("/hello", func(w http.ResponseWriter, r *http.Request) {
for k, v := range r.Header {
fmt.Printf("Header[%q]=%q\n", k, v)
}
})
//跑项目
r.Run(":9999")
}
// // handler echoes r.URL.Path
// func indexHandler(w http.ResponseWriter, req *http.Request) {
// fmt.Fprintf(w, "URL.Path = %q\n", req.URL.Path)
// }
// // handler echoes r.URL.Header
// func helloHandler(w http.ResponseWriter, req *http.Request) {
// for k, v := range req.Header {
// fmt.Fprintf(w, "Header[%q] = %q\n", k, v)
// }
// }package gee
import (
"fmt"
"net/http"
)
//包具体实现
type HandlerFunc func(http.ResponseWriter, *http.Request)
type Engine struct {
router map[string]HandlerFunc
}
//初始化,创建Engine实例
func Default() *Engine {
return &Engine{router: make(map[string]HandlerFunc)}
}
//增加路由
//将请求方式,路径,函数都添加到Engine结构体
func (engine *Engine) addRoute(method string, pattern string, handler HandlerFunc) {
key := method + "-" + pattern
engine.router[key] = handler
}
//请求的方法
//GET
func (engine *Engine) GET(pattern string, handler HandlerFunc) {
engine.addRoute("GET", pattern, handler)
}
//POST
func (engine *Engine) POST(pattern string, handler HandlerFunc) {
engine.addRoute("POST", pattern, handler)
}
//启动
func (engine *Engine) Run(addr string) (err error) {
return http.ListenAndServe(addr, engine)
}
func (engine *Engine) ServeHTTP(w http.ResponseWriter, r *http.Request) {
key := r.Method + "-" + r.URL.Path
handler, ok := engine.router[key]
if ok {
handler(w, r)
} else {
fmt.Printf("404 NOT FOUND: %s\n", r.URL)
}
}整个Gee框架的原型已经出来了。实现了路由映射表,提供了用户注册静态路由的方法,包装了启动服务的函数。
以上就是Gee框架的雏形
完成时间:2021/7/18
我们第一天完成的是一个静态路由的雏形,但是返回消息和请求的方式都比较简单,不能达到一个处理业务的能力,并且都不够完整,如果我们要构造一个完整的响应和请求,那么我们就得去设置请求头和主体,但是有些部分我们要不断地去设置例如状态码,消息类型等,这些重复工作我们可以进行封装,达到一个能快速,完整的构造HTTP响应的能力。
用返回 JSON 数据作比较,感受下封装前后的差距。
封装前
obj = map[string]interface{}{
"name": "geektutu",
"password": "1234",
}
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusOK)
encoder := json.NewEncoder(w)
if err := encoder.Encode(obj); err != nil {
http.Error(w, err.Error(), 500)
}封装后
c.JSON(http.StatusOK, gee.H{
"username": c.PostForm("username"),
"password": c.PostForm("password"),
})当你利用gin框架写项目时候,你要处理不同的返回体,就会利用不同的接口,而且都比较简单,也需要去处理动态路由,以及一些中间件,这么多的工作下,函数的参数都没有发生改变都是 *gin.Context ,可以判断出上诉那些工作和信息都由Context去承载了。设计 Context 结构,扩展性和复杂性留在了内部,而对外简化了接口。路由的处理函数,以及将要实现的中间件,参数都统一使用 Context 实例, Context 就像一次会话的百宝箱,可以找到任何东西。
所以我们要对Context进行设计,封装。
-
返回体
-
- 请求头
- 主体
- 。。。。
-
请求体
-
- 动态路由
- 。。。
package gee
import (
"encoding/json"
"fmt"
"net/http"
)
type H map[string]interface{}
type Context struct {
//起始结构
Writer http.ResponseWriter
Req *http.Request
//请求信息
Path string
Method string
//返回信息
StatusCode int
}
func newContext(w http.ResponseWriter, req *http.Request) *Context {
return &Context{
Writer: w,
Req: req,
Path: req.URL.Path,
Method: req.Method,
}
}
//获取post信息
func (c *Context) PostForm(key string) string {
return c.Req.FormValue(key)
}
func (c *Context) Query(key string) string {
return c.Req.URL.Query().Get(key)
}
//设置状态码
func (c *Context) Status(code int) {
c.StatusCode = code
c.Writer.WriteHeader(code)
}
//设置头部信息
func (c *Context) SetHeader(key string, value string) {
c.Writer.Header().Set(key, value)
}
//处理返回类型
//TEXT
func (c *Context) String(code int, format string, values ...interface{}) {
c.SetHeader("Content-Type", "text/plain")
c.Status(code)
c.Writer.Write([]byte(fmt.Sprintf(format, values...)))
}
//JSON
func (c *Context) JSON(code int, obj interface{}) {
c.SetHeader("Content-Type", "application/json")
c.Status(code)
encoder := json.NewEncoder(c.Writer)
if err := encoder.Encode(obj); err != nil {
http.Error(c.Writer, err.Error(), 500)
}
}
//Data
func (c *Context) Data(code int, data []byte) {
c.Status(code)
c.Writer.Write(data)
}
//HTML
func (c *Context) HTML(code int, html string) {
c.SetHeader("Content-Type", "text/html")
c.Status(code)
c.Writer.Write([]byte(html))
}- 代码最开头,给
map[string]interface{}起了一个别名gee.H,构建JSON数据时,显得更简洁。 Context目前只包含了http.ResponseWriter和*http.Request,另外提供了对 Method 和 Path 这两个常用属性的直接访问。- 提供了访问Query和PostForm参数的方法。
- 提供了快速构造String/Data/JSON/HTML响应的方法。
第一天的代码,路由仅仅完成了查找和绑定函数的在作用,还有其他的功能并未写上,所以为了解耦以及增强路由功能,简化代码,我们将路由方法和结构提取出来。方便后面对路由进行加强
type router struct {
handlers map[string]HandlerFunc
}
func newRouter() *router {
return &router{handlers: make(map[string]HandlerFunc)}
}
func (r *router) addRoute(method string, pattern string, handler HandlerFunc) {
log.Printf("Route %4s - %s", method, pattern)
key := method + "-" + pattern
r.handlers[key] = handler
}
func (r *router) handle(c *Context) {
key := c.Method + "-" + c.Path
if handler, ok := r.handlers[key]; ok {
handler(c)
} else {
c.String(http.StatusNotFound, "404 NOT FOUND: %s\n", c.Path)
}
}我们增加了上下文Context以及提取了路由,那么主文件我们也需要进行改变。
// HandlerFunc defines the request handler used by gee
type HandlerFunc func(*Context)
// Engine implement the interface of ServeHTTP
type Engine struct {
router *router
}
// New is the constructor of gee.Engine
func New() *Engine {
return &Engine{router: newRouter()}
}
func (engine *Engine) addRoute(method string, pattern string, handler HandlerFunc) {
engine.router.addRoute(method, pattern, handler)
}
// GET defines the method to add GET request
func (engine *Engine) GET(pattern string, handler HandlerFunc) {
engine.addRoute("GET", pattern, handler)
}
// POST defines the method to add POST request
func (engine *Engine) POST(pattern string, handler HandlerFunc) {
engine.addRoute("POST", pattern, handler)
}
// Run defines the method to start a http server
func (engine *Engine) Run(addr string) (err error) {
return http.ListenAndServe(addr, engine)
}
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
c := newContext(w, req)
engine.router.handle(c)
}将router相关的代码独立后,gee.go简单了不少。最重要的还是通过实现了 ServeHTTP 接口,接管了所有的 HTTP 请求。相比第一天的代码,这个方法也有细微的调整,在调用 router.handle 之前,构造了一个 Context 对象。这个对象目前还非常简单,仅仅是包装了原来的两个参数,之后我们会慢慢地给Context插上翅膀。
时间:2021/7/19
我们用了一个非常简单的map结构存储了路由表,使用map存储键值对,索引非常高效,但是有一个弊端,键值对的存储的方式,只能用来索引静态路由。
其实我们到现在都没有去处理动态路由的功能,前面写的全是静态路由无法应对 /hello/:name 这样子的路由。
动态路由有很多种实现方式,支持的规则、性能等有很大的差异。例如开源的路由实现gorouter支持在路由规则中嵌入正则表达式,例如/p/[0-9A-Za-z]+,即路径中的参数仅匹配数字和字母;另一个开源实现httprouter就不支持正则表达式。著名的Web开源框架gin 在早期的版本,并没有实现自己的路由,而是直接使用了httprouter,后来不知道什么原因,放弃了httprouter,自己实现了一个版本。
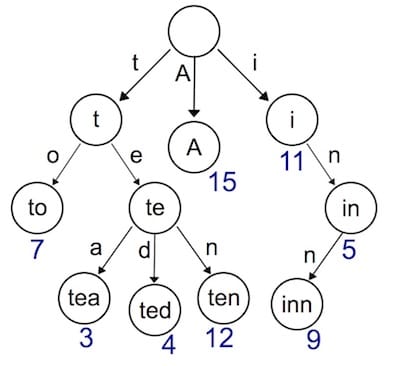
实现动态路由最常用的数据结构,被称为前缀树(Trie树)。看到名字你大概也能知道前缀树长啥样了:每一个节点的所有的子节点都拥有相同的前缀。这种结构非常适用于路由匹配,比如我们定义了如下路由规则:
- /:lang/doc
- /:lang/tutorial
- /:lang/intro
- /about
- /p/blog
- /p/related
我们用前缀树来表示,是这样的。
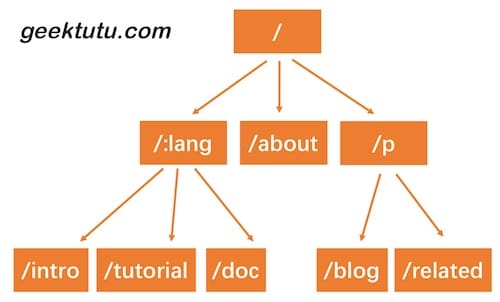
HTTP请求的路径恰好是由/分隔的多段构成的,因此,每一段可以作为前缀树的一个节点。我们通过树结构查询,如果中间某一层的节点都不满足条件,那么就说明没有匹配到的路由,查询结束。
接下来我们实现的动态路由具备以下两个功能。
- 参数匹配
:。例如/p/:lang/doc,可以匹配/p/c/doc和/p/go/doc。 - 通配
*。例如/static/*filepath,可以匹配/static/fav.ico,也可以匹配/static/js/jQuery.js,这种模式常用于静态服务器,能够递归地匹配子路径。
package gee
import "strings"
//实现动态路由最常用的数据结构,被称为前缀树(Trie树)。
//前缀树路由,每个节点的信息
type node struct {
pattern string //待匹配的路由 例如 /p/:lang
part string // 路由中的一部分,例如 :lang
children []*node //子节点,例如 [doc, tutorial, intro]
isWild bool // 是否精确匹配,part 含有 : 或 * 时为true
}
// 单个匹配成功的节点,用于插入
func (n *node) matchChild(part string) *node {
for _, child := range n.children {
if child.part == part || child.isWild {
return child
}
}
return nil
}
// 所有匹配成功的节点,用于查找
func (n *node) matchChildren(part string) []*node {
nodes := make([]*node, 0)
for _, child := range n.children {
if child.part == part || child.isWild {
nodes = append(nodes, child)
}
}
return nodes
}
//路由插入(注册)
//不断查询每个路由的部分(以/分割的部分)如果有跳过,没有就添加子节点,直到全部完成
func (n *node) insert(pattern string, parts []string, height int) {
if len(parts) == height {
n.pattern = pattern
return
}
part := parts[height]
child := n.matchChild(part)
if child == nil {
child = &node{part: part, isWild: part[0] == ':' || part[0] == '*'}
n.children = append(n.children, child)
}
child.insert(pattern, parts, height+1)
}
//路由查询(匹配)
//递归法进行匹配 从根节点获取子节点 子节点查询直到都匹配成功
//退出要求 1.匹配到了* 2.pattern==“” (没有结束)3.匹配到最后一个节点
func (n *node) search(parts []string, height int) *node {
if len(parts) == height || strings.HasPrefix(n.part, "*") { //strings.HasPrefix()函数用来检测字符串是否以指定的前缀开头。
if n.pattern == "" {
return nil
}
return n
}
part := parts[height]
children := n.matchChildren(part)
for _, child := range children {
result := child.search(parts, height+1)
if result != nil {
return result
}
}
return nil
}前面两个只是一个辅助函数,重要的是后面两个函数。
路由最重要的是注册和匹配,那么对于Tire树而言,那就是插入和查询。
插入:对于路由路径每个部分进行单个匹配,如果没有就创建和加入子节点。如果有那就往下继续匹配,直到完成,获取路由路径
查询:每一层进行递归查询,直到找到路由地址
我们既然创建了Tire树,那么路由那边肯定也需要一点变化。
type router struct {
roots map[string]*node //建立一个前缀树路由 去映射handler
handlers map[string]HandlerFunc
}
func newRouter() *router {
return &router{
roots: make(map[string]*node),
handlers: make(map[string]HandlerFunc)}
}先更新路由,建立前缀树路由
//作用主要是分割路由地址(以/分割成各个部分)
func parsePattern(pattern string) []string {
vs := strings.Split(pattern, "/")
parts := make([]string, 0)
for _, item := range vs {
if item != "" {
parts = append(parts, item)
if item[0] == '*' {
break
}
}
}
return parts
}
func (r *router) addRoute(method string, pattern string, handler HandlerFunc) {
parts := parsePattern(pattern)
log.Printf("Route %4s - %s", method, pattern)
key := method + "-" + pattern
_, ok := r.roots[method] //可以添加自定义的请求方式
if !ok {
r.roots[method] = &node{}
}
r.roots[method].insert(pattern, parts, 0) //注册路由
r.handlers[key] = handler
}
//获取路由以及匹配字段(param)值
func (r *router) getRoute(method string, path string) (*node, map[string]string) {
searchParts := parsePattern(path) //拿到请求地址每个部分
params := make(map[string]string)
root, ok := r.roots[method] //从请求方式作为根节点找
if !ok {
return nil, nil
}
n := root.search(searchParts, 0) //匹配 如果匹配成功就会返回子节点(最小的)
if n != nil {
parts := parsePattern(n.pattern) //拿到子节点路由的每个部分
for index, part := range parts { //请求地址和路由地址进行匹配(:和*)
if part[0] == ':' {
params[part[1:]] = searchParts[index] //将请求地址的值与路由地址的params进行映射
}
if part[0] == '*' && len(part) > 1 {
params[part[1:]] = strings.Join(searchParts[index:], "/")
break
}
}
return n, params
}
return nil, nil
}
func (r *router) handle(c *Context) {
n, params := r.getRoute(c.Method, c.Path) //获取请求地址和params值
if n != nil {
c.Params = params
key := c.Method + "-" + n.pattern
r.handlers[key](c) //映射对应的handler
} else {
c.String(http.StatusNotFound, "404 NOT FOUND: %s\n", c.Path)
}
}上面每个部分都写了注释的。
Context与handle的变化
在 HandlerFunc 中,希望能够访问到解析的参数,因此,需要对 Context 对象增加一个属性和方法,来提供对路由参数的访问。我们将解析后的参数存储到Params中,通过c.Param("lang")的方式获取到对应的值。
type Context struct {
// origin objects
Writer http.ResponseWriter
Req *http.Request
// request info
Path string
Method string
Params map[string]string
// response info
StatusCode int
}
func (c *Context) Param(key string) string {
value, _ := c.Params[key]
return value
}时间:2021/7/20
分组控制(Group Control)是 Web 框架应提供的基础功能之一。所谓分组,是指路由的分组。如果没有路由分组,我们需要针对每一个路由进行控制。但是真实的业务场景中,往往某一组路由需要相似的处理。例如:
- 以
/post开头的路由匿名可访问。 - 以
/admin开头的路由需要鉴权。 - 以
/api开头的路由是 RESTful 接口,可以对接第三方平台,需要三方平台鉴权。
大部分情况下的路由分组,是以相同的前缀来区分的。因此,我们今天实现的分组控制也是以前缀来区分,并且支持分组的嵌套。例如/post是一个分组,/post/a和/post/b可以是该分组下的子分组。作用在/post分组上的中间件(middleware),也都会作用在子分组,子分组还可以应用自己特有的中间件。
简单的来讲就是将路由进行分组,方便提供重复的中间件,便于查询路由,将路由进行分类处理。
分组路由所必须有的功能
- 分组嵌套
- 可以承担中间件
- 提供接口
根据功能分析路由有哪些属性
- 前缀
- 父亲
- 中间件
- engine(为了调用接口)
//路由分组
//满足的条件
//1.前缀 ----分组的路径
//2.具有中间件
//3.可以进行嵌套
//4.提供分组的接口
type RouterGroup struct {
prefix string
middlewares []HandlerFunc
parent *RouterGroup
engine *Engine
}进一步抽象,将Engine作为最顶层的分组,也就是说Engine拥有RouterGroup所有的能力。
type Engine struct {
//router map[string]HandlerFunc
*RouterGroup
router *router
groups []*RouterGroup //存所有分组路由
}相对应的变化
//初始化,创建Engine实例
func Default() *Engine {
// return &Engine{router: make(map[string]HandlerFunc)}
//进行初始化
//此时engine是最顶层的分组,它可以调用RouterGroup的所有接口
engine := &Engine{router: newRouter()}
engine.RouterGroup = &RouterGroup{engine: engine}
engine.groups = []*RouterGroup{engine.RouterGroup}
return engine
}
//为分组创建一个engine
func (group *RouterGroup) Group(prefix string) *RouterGroup {
engine := group.engine
newGroup := &RouterGroup{
prefix: group.prefix + prefix,
parent: group,
engine: engine,
}
engine.groups = append(engine.groups, newGroup)
return newGroup
}
//增加路由
//将请求方式,路径,函数都添加到Engine结构体
func (group *RouterGroup) addRoute(method string, comp string, handler HandlerFunc) {
// key := method + "-" + pattern
// engine.router[key] = handler
//engine.router.addRoute(method, pattern, handler)
pattern := group.prefix + comp
//log.Printf("Route %4s - %s", method, pattern)
group.engine.router.addRoute(method, pattern, handler)
}
//请求的方法
//GET
func (group *RouterGroup) GET(pattern string, handler HandlerFunc) {
group.addRoute("GET", pattern, handler)
}
//POST
func (group *RouterGroup) POST(pattern string, handler HandlerFunc) {
group.addRoute("POST", pattern, handler)
}结合group使用,你会发现不同group他对应的engine都不同,像树往下进行分开。
时间:2021/7/21
中间件(middlewares),简单说,就是非业务的技术类组件。Web 框架本身不可能去理解所有的业务,因而不可能实现所有的功能。因此,框架需要有一个插口,允许用户自己定义功能,嵌入到框架中,仿佛这个功能是框架原生支持的一样。因此,对中间件而言,需要考虑2个比较关键的点:
- 插入点在哪?使用框架的人并不关心底层逻辑的具体实现,如果插入点太底层,中间件逻辑就会非常复杂。如果插入点离用户太近,那和用户直接定义一组函数,每次在 Handler 中手工调用没有多大的优势了。
- 中间件的输入是什么?中间件的输入,决定了扩展能力。暴露的参数太少,用户发挥空间有限。
Gee 的中间件的定义与路由映射的 Handler 一致,处理的输入是Context对象。插入点是框架接收到请求初始化Context对象后,允许用户使用自己定义的中间件做一些额外的处理,例如记录日志等,以及对Context进行二次加工。另外通过调用(*Context).Next()函数,中间件可等待用户自己定义的 Handler处理结束后,再做一些额外的操作,例如计算本次处理所用时间等。即 Gee 的中间件支持用户在请求被处理的前后,做一些额外的操作。举个例子,我们希望最终能够支持如下定义的中间件,c.Next()表示等待执行其他的中间件或用户的Handler.
中间件是应用在RouterGroup上的,应用在最顶层的 Group,相当于作用于全局,所有的请求都会被中间件处理。
那为什么不作用在每一条路由规则上呢?
作用在某条路由规则,那还不如用户直接在 Handler 中调用直观。只作用在某条路由规则的功能通用性太差,不适合定义为中间件。
我们之前的框架设计是这样的,当接收到请求后,匹配路由,该请求的所有信息都保存在Context中。中间件也不例外,接收到请求后,应查找所有应作用于该路由的中间件,保存在Context中,依次进行调用。
为什么依次调用后,还需要在Context中保存呢?
因为在设计中, 中间件不仅作用在处理流程前,也可以作用在处理流程后, 即在用户定义的 Handler 处理完毕后,还可以执行剩下的操作。
那么根据上面我们来分析一下,中间件的执行过程
func A(c *Context) {
part1
c.Next()
part2
}
func B(c *Context) {
part3
c.Next()
part4
}这里定义了两个中间件A和B和路由映射的Handler 按照上面的说法,中间件的调用顺序应该是
part1->part3->handler->part4->part2
这样既可以满足处理流程前的工作,也可以处理流程结束的工作
type Context struct {
//起始结构
Writer http.ResponseWriter
Req *http.Request
//请求信息
Path string
Method string
Params map[string]string
//返回信息
StatusCode int
//中间件信息
handlers []HandlerFunc
index int
}
func newContext(w http.ResponseWriter, req *http.Request) *Context {
return &Context{
Writer: w,
Req: req,
Path: req.URL.Path,
Method: req.Method,
index: -1,
}
}
//next方法
func (c *Context) Next() {
c.index++
s := len(c.handlers)
for ; c.index < s; c.index++ {
c.handlers[c.index](c)
}
}index主要是记录中间件的位置,当前执行到了第几个中间件
next()就是向下一个中间件进行执行
这样子就可以满足我们上诉说的中间件的执行过程
详细的再说一遍过程
- c.index++,c.index 变为 0
- 0 < 3,调用 c.handlers[0],即 A
- 执行 part1,调用 c.Next()
- c.index++,c.index 变为 1
- 1 < 3,调用 c.handlers[1],即 B
- 执行 part3,调用 c.Next()
- c.index++,c.index 变为 2
- 2 < 3,调用 c.handlers[2],即Handler
- Handler 调用完毕,返回到 B 中的 part4,执行 part4
- part4 执行完毕,返回到 A 中的 part2,执行 part2
- part2 执行完毕,结束。
// Use is defined to add middleware to the group
func (group *RouterGroup) Use(middlewares ...HandlerFunc) {
group.middlewares = append(group.middlewares, middlewares...)
}
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
var middlewares []HandlerFunc
for _, group := range engine.groups {
if strings.HasPrefix(req.URL.Path, group.prefix) {
middlewares = append(middlewares, group.middlewares...)
}
}
c := newContext(w, req)
c.handlers = middlewares
engine.router.handle(c)
}
func (r *router) handle(c *Context) {
n, params := r.getRoute(c.Method, c.Path)
if n != nil {
key := c.Method + "-" + n.pattern
c.Params = params
c.handlers = append(c.handlers, r.handlers[key])
} else {
c.handlers = append(c.handlers, func(c *Context) {
c.String(http.StatusNotFound, "404 NOT FOUND: %s\n", c.Path)
})
}
c.Next()
}设置了中间件后,映射的handler不再直接执行了,而是添加到handlers里面和中间件一起执行
ServerHTTP里面当收到一个请求的时候通过前缀进行匹配路由,得到中间件,都添加到handlers,然后一一执行
时间:2021/7/22
现在流行前后端分离的开发模式,后端提供RESful的接口,前端进行调用,以及渲染数据。
其实我对服务端渲染接触的都比较少。对于这方面理解就比较少了。
现在越来越流行前后端分离的开发模式,即 Web 后端提供 RESTful 接口,返回结构化的数据(通常为 JSON 或者 XML)。前端使用 AJAX 技术请求到所需的数据,利用 JavaScript 进行渲染。Vue/React 等前端框架持续火热,这种开发模式前后端解耦,优势非常突出。后端童鞋专心解决资源利用,并发,数据库等问题,只需要考虑数据如何生成;前端童鞋专注于界面设计实现,只需要考虑拿到数据后如何渲染即可。使用 JSP 写过网站的童鞋,应该能感受到前后端耦合的痛苦。JSP 的表现力肯定是远不如 Vue/React 等专业做前端渲染的框架的。而且前后端分离在当前还有另外一个不可忽视的优势。因为后端只关注于数据,接口返回值是结构化的,与前端解耦。同一套后端服务能够同时支撑小程序、移动APP、PC端 Web 页面,以及对外提供的接口。随着前端工程化的不断地发展,Webpack,gulp 等工具层出不穷,前端技术越来越自成体系了。
但前后分离的一大问题在于,页面是在客户端渲染的,比如浏览器,这对于爬虫并不友好。Google 爬虫已经能够爬取渲染后的网页,但是短期内爬取服务端直接渲染的 HTML 页面仍是主流。
今天的内容便是介绍 Web 框架如何支持服务端渲染的场景。
网页的三剑客,JavaScript、CSS 和 HTML。要做到服务端渲染,第一步便是要支持 JS、CSS 等静态文件。还记得我们之前设计动态路由的时候,支持通配符*匹配多级子路径。比如路由规则/assets/*filepath,可以匹配/assets/开头的所有的地址。例如/assets/js/geektutu.js,匹配后,参数filepath就赋值为js/geektutu.js。
那如果我么将所有的静态文件放在/usr/web目录下,那么filepath的值即是该目录下文件的相对地址。映射到真实的文件后,将文件返回,静态服务器就实现了。
找到文件后,如何返回这一步,net/http库已经实现了。因此,gee 框架要做的,仅仅是解析请求的地址,映射到服务器上文件的真实地址,交给http.FileServer处理就好了。
// create static handler
func (group *RouterGroup) createStaticHandler(relativePath string, fs http.FileSystem) HandlerFunc {
absolutePath := path.Join(group.prefix, relativePath)
fileServer := http.StripPrefix(absolutePath, http.FileServer(fs))
return func(c *Context) {
file := c.Param("filepath")
// Check if file exists and/or if we have permission to access it
if _, err := fs.Open(file); err != nil {
c.Status(http.StatusNotFound)
return
}
fileServer.ServeHTTP(c.Writer, c.Req)
}
}
// serve static files
func (group *RouterGroup) Static(relativePath string, root string) {
handler := group.createStaticHandler(relativePath, http.Dir(root))
urlPattern := path.Join(relativePath, "/*filepath")
// Register GET handlers
group.GET(urlPattern, handler)
}我们给RouterGroup添加了2个方法,Static这个方法是暴露给用户的。用户可以将磁盘上的某个文件夹root映射到路由relativePath。
Go语言内置了text/template和html/template2个模板标准库,其中html/template为 HTML 提供了较为完整的支持。包括普通变量渲染、列表渲染、对象渲染等。gee 框架的模板渲染直接使用了html/template提供的能力。
Engine struct {
*RouterGroup
router *router
groups []*RouterGroup // store all groups
htmlTemplates *template.Template // for html render
funcMap template.FuncMap // for html render
}
func (engine *Engine) SetFuncMap(funcMap template.FuncMap) {
engine.funcMap = funcMap
}
func (engine *Engine) LoadHTMLGlob(pattern string) {
engine.htmlTemplates = template.Must(template.New("").Funcs(engine.funcMap).ParseGlob(pattern))
}首先为 Engine 示例添加了 *template.Template 和 template.FuncMap对象,前者将所有的模板加载进内存,后者是所有的自定义模板渲染函数。
另外,给用户分别提供了设置自定义渲染函数funcMap和加载模板的方法。
接下来,对原来的 (*Context).HTML()方法做了些小修改,使之支持根据模板文件名选择模板进行渲染。
type Context struct {
// ...
// engine pointer
engine *Engine
}
func (c *Context) HTML(code int, name string, data interface{}) {
c.SetHeader("Content-Type", "text/html")
c.Status(code)
if err := c.engine.htmlTemplates.ExecuteTemplate(c.Writer, name, data); err != nil {
c.Fail(500, err.Error())
}
}我们在 Context 中添加了成员变量 engine *Engine,这样就能够通过 Context 访问 Engine 中的 HTML 模板。实例化 Context 时,还需要给 c.engine 赋值。
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// ...
c := newContext(w, req)
c.handlers = middlewares
c.engine = engine
engine.router.handle(c)
}时间:2021/7/23
Go 语言中,比较常见的错误处理方法是返回 error,由调用者决定后续如何处理。但是如果是无法恢复的错误,可以手动触发 panic,当然如果在程序运行过程中出现了类似于数组越界的错误,panic 也会被触发。panic 会中止当前执行的程序,退出。
下面是主动触发的例子:
// hello.go
func main() {
fmt.Println("before panic")
panic("crash")
fmt.Println("after panic")
}
$ go run hello.go
before panic
panic: crash
goroutine 1 [running]:
main.main()
~/go_demo/hello/hello.go:7 +0x95
exit status 2panic 会导致程序被中止,但是在退出前,会先处理完当前协程上已经defer 的任务,执行完成后再退出。效果类似于 java 语言的 try...catch。
// hello.go
func main() {
defer func() {
fmt.Println("defer func")
}()
arr := []int{1, 2, 3}
fmt.Println(arr[4])
}
$ go run hello.go
defer func
panic: runtime error: index out of range [4] with length 3可以 defer 多个任务,在同一个函数中 defer 多个任务,会逆序执行。即先执行最后 defer 的任务。
在这里,defer 的任务执行完成之后,panic 还会继续被抛出,导致程序非正常结束。
Go 语言还提供了 recover 函数,可以避免因为 panic 发生而导致整个程序终止,recover 函数只在 defer 中生效。
// hello.go
func test_recover() {
defer func() {
fmt.Println("defer func")
if err := recover(); err != nil {
fmt.Println("recover success")
}
}()
arr := []int{1, 2, 3}
fmt.Println(arr[4])
fmt.Println("after panic")
}
func main() {
test_recover()
fmt.Println("after recover")
}
$ go run hello.go
defer func
recover success
after recover我们可以看到,recover 捕获了 panic,程序正常结束。test_recover() 中的 after panic 没有打印,这是正确的,当 panic 被触发时,控制权就被交给了 defer 。就像在 java 中,try代码块中发生了异常,控制权交给了 catch,接下来执行 catch 代码块中的代码。而在 main() 中打印了 after recover,说明程序已经恢复正常,继续往下执行直到结束。
对一个 Web 框架而言,错误处理机制是非常必要的。可能是框架本身没有完备的测试,导致在某些情况下出现空指针异常等情况。也有可能用户不正确的参数,触发了某些异常,例如数组越界,空指针等。如果因为这些原因导致系统宕机,必然是不可接受的。
我们在第六天实现的框架并没有加入异常处理机制,如果代码中存在会触发 panic 的 BUG,很容易宕掉。
例如下面的代码:
func main() {
r := gee.New()
r.GET("/panic", func(c *gee.Context) {
names := []string{"geektutu"}
c.String(http.StatusOK, names[100])
})
r.Run(":9999")
}在上面的代码中,我们为 gee 注册了路由 /panic,而这个路由的处理函数内部存在数组越界 names[100],如果访问 localhost:9999/panic,Web 服务就会宕掉。
今天,我们将在 gee 中添加一个非常简单的错误处理机制,即在此类错误发生时,向用户返回 Internal Server Error,并且在日志中打印必要的错误信息,方便进行错误定位。
我们之前实现了中间件机制,错误处理也可以作为一个中间件,增强 gee 框架的能力。
新增文件 gee/recovery.go,在这个文件中实现中间件 Recovery。
func Recovery() HandlerFunc {
return func(c *Context) {
defer func() {
if err := recover(); err != nil {
message := fmt.Sprintf("%s", err)
log.Printf("%s\n\n", trace(message))
c.Fail(http.StatusInternalServerError, "Internal Server Error")
}
}()
c.Next()
}
}Recovery 的实现非常简单,使用 defer 挂载上错误恢复的函数,在这个函数中调用 recover(),捕获 panic,并且将堆栈信息打印在日志中,向用户返回 Internal Server Error。
你可能注意到,这里有一个 trace() 函数,这个函数是用来获取触发 panic 的堆栈信息,完整代码如下:
package gee
import (
"fmt"
"log"
"net/http"
"runtime"
"strings"
)
func trace(message string) string {
var pcs [32]uintptr
//Callers 用来返回调用栈的程序计数器,
//第 0 个 Caller 是 Callers 本身,
//第 1 个是上一层 trace,
//第 2 个是再上一层的 defer func。
//因此,为了日志简洁一点,我们跳过了前 3 个 Caller。
n := runtime.Callers(3, pcs[:])
var str strings.Builder //一个string类型的数值写入builder
//Builder的底层实现其实就是一个string类型的切片
str.WriteString(message + "\nTraceback:")
for _, pc := range pcs[:n] {
fn := runtime.FuncForPC(pc)
file, line := fn.FileLine(pc)
str.WriteString(fmt.Sprintf("\n\t%s:%d", file, line))
}
//当执行WriteString操作时,实际上就是append操作,最后利用String()函数将他拼接成一个字符串
return str.String()
}
//错误处理机制
//可以避免因为 panic 发生而导致整个程序终止,recover 函数只在 defer 中生效。
func Recovery() HandlerFunc {
return func(c *Context) {
defer func() {
if err := recover(); err != nil {
message := fmt.Sprintf("%s", err)
log.Printf("%s\n\n", trace(message)) //获取触发 panic 的堆栈信息
c.Fail(http.StatusInternalServerError, "Internal Server Error")
}
}()
c.Next()
}
}在 trace() 中,调用了 runtime.Callers(3, pcs[:]),Callers 用来返回调用栈的程序计数器, 第 0 个 Caller 是 Callers 本身,第 1 个是上一层 trace,第 2 个是再上一层的 defer func。因此,为了日志简洁一点,我们跳过了前 3 个 Caller。
接下来,通过 runtime.FuncForPC(pc) 获取对应的函数,在通过 fn.FileLine(pc) 获取到调用该函数的文件名和行号,打印在日志中。
至此,gee 框架的错误处理机制就完成了。
时间:2021/7/24