This dataset is a modified version of MovieNet dataset. Original version can be found here: MovieNet Original Dataset
Total Number of Movies in Dataset
64 Movies
- 90% of movies from these 64 Movies are created as Train Dataset (~= 57 movies).
- All sample features created from these 57 movies are further split to Train and Val sets with 80% of total samples to Train and 20% of total samples to Validation Set
NOTE: Train and Validation sets are not splitted based on individual movies instead splitted on all the features created from every movie of these 57 movies (No. of features depends on no. of shots and sequence length we are considering for each feature)
10% of movies from these 64 Movies are created as Test Dataset (~= 7 Movies)
NOTE: This test data is completely unseen and used only for testing purpose after all the epochs of training and validating
Taken from AnyiRao's Model available in the Github Repo (All Credits to Anyi Rao. Thanks for the excellent work.)
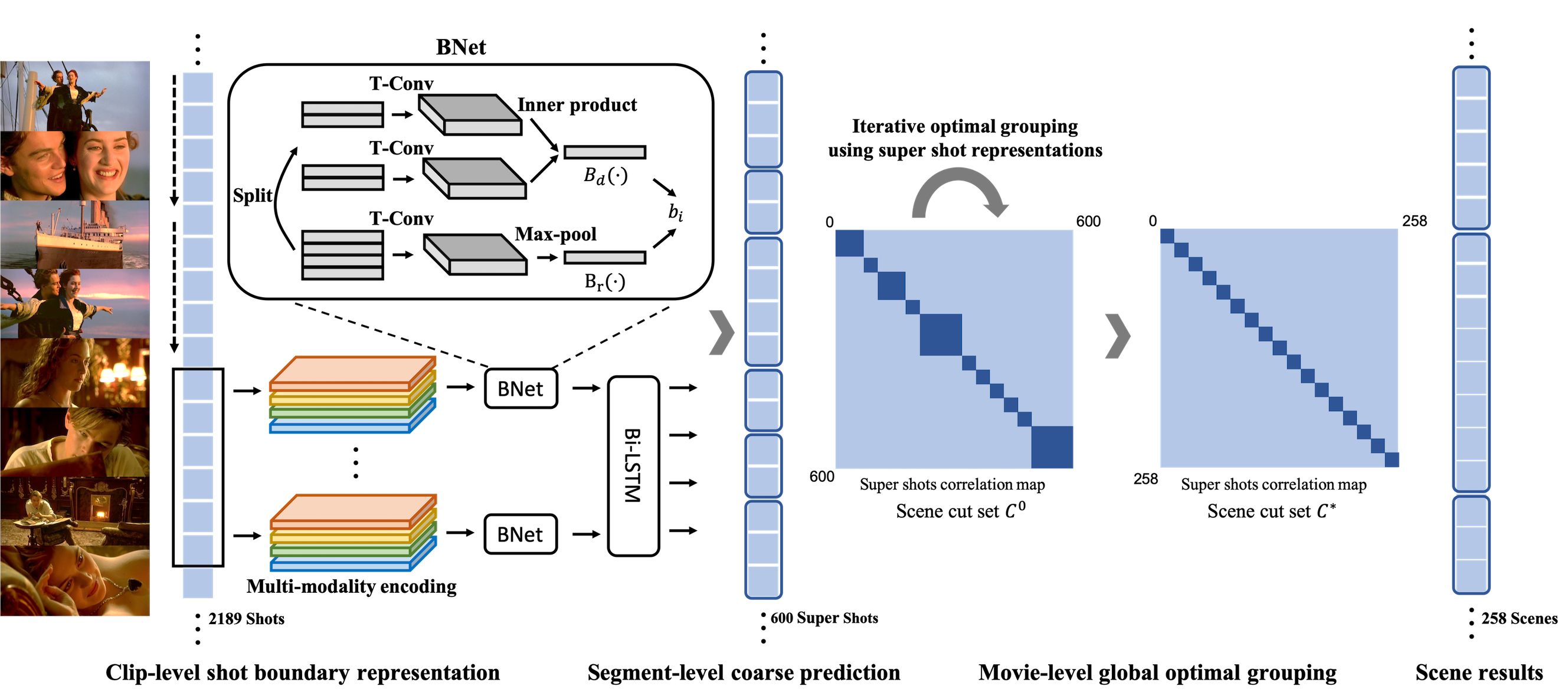
Rao, Anyi, et al. “A Local-to-Global Approach to Multi-modal Movie Scene Segmentation.” arXiv.org, 2020, https://arxiv.org/abs/2004.02678
- Trained for 30 epochs with batch size of 8 (because of my GPU limitation)
- Learning Rate started with 1e-2
epoch #30
AVG Train Loss = 0.2045
AVG Val Loss = 0.2098
Best Val Loss at epoch #28
AVG Train Loss=0.2064
AVG Val Loss=0.2029
On Test Set
After epoch #30,
AVG Test Loss = 0.2833
NOTE: Testing is only performed once in the end after completing all the epochs of training and validation.
Eluvio ML Challenges Github repo
Average Precision:
AP = 0.4243547650003294
mAP = 0.44133263058275096
AP_dict = {'tt1205489': 0.44937209408748796, 'tt1375666': 0.43944004051079305, 'tt1412386': 0.5537258781590395, 'tt1707386': 0.2981230102629725, 'tt2024544': 0.5690226130102841, 'tt2488496': 0.3108997275319894, 'tt2582846': 0.4687450505166901}
IoU:
mean_miou = 0.053972835141407056
miou_dict = {'tt1205489': 0.028535499731287987, 'tt1375666': 0.07579754604309327, 'tt1412386': 0.05955595098601886, 'tt1707386': 0.030215081417225047, 'tt2024544': 0.030116858728477875, 'tt2488496': 0.08702184776057309, 'tt2582846': 0.06656706132317326}
NOTE: Average Precision and IoU are only computed for completely unseen Test set
Saved Checkpoint can be found here: Checkpoint with best val loss = 0.2029 at epoch #28


Python v3.8
numpy v1.19.5
torch v1.6.0
sklearn v0.24.1
tensorboard v2.3.0
pickle v4.0
glob
- Set Configuration Parameters in
configuration.pyfile or while instantiatingConfigclass object from'__main__'inmain.pyfile
Important Parameters to Change:
data_folder: Change to your data path
save_dir: Give some path to save your checkpoints, otherwise checkpoints will not be saved
cp_dir: To resume training from certain checkpoint, give your checkpoint path here
num_epochs: number of epochs to run
batch_size: batch size to consider
n_seq: sequence length of each feature/sample
n_shots: no. of shots to consider in each sequence of a feature/sample
- Run
python main.py
Model graphs are provided in the project ./runs directory.
Command to visualize graphs:
tensorboard --logdir runs