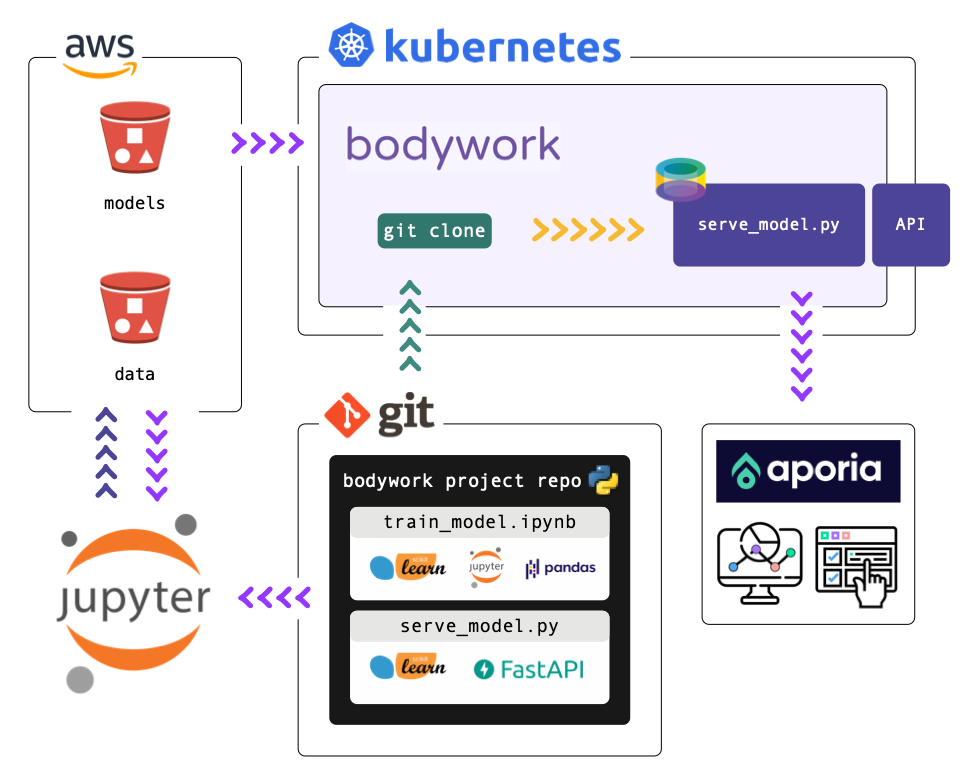
This repository demonstrates how to integrate Aporia's ML model monitoring service into a Bodywork serving pipeline. The steps for engineering the pipeline are:
- Create synthetic regression datasets off-line - see the notebook
notebooks/create_datasets.ipynb. - Train a model off-line, upload it to cloud object storage and register the datasets with Aporia - see the notebook
notebooks/train_model.ipynbnotebook. - Use FastAPI to develop a web service for exposing the model (downloaded from cloud object storage), and setup the Aporia client to log predictions, so that the model can be monitored in production - see
pipeline/serve_model.py. - Configure the deployment to Kubernetes in
bodywork.yaml. - Deploy to Kubernetes using the Bodywork CLI.
To run this project yourself, follow the steps below. All of the datasets and model artefacts required to run and deploy the pipeline are hosted on a publicly accessible AWS S3 bucket, so there's no need to setup anything unless you want to.
Before we get going,
$ python3.9 -m venv .venv
$ source .venv/bin/activate
$ pip install -r requirements.txt
$ pip install -r requirements_dev.txt
You'll also need an Aporia account. In this guide we'll use the cloud version, but Aporia can be installed on-prem as well.
Start by creating a model in Aporia.
Copy your token and Model ID to the last snippet in notebooks/train_model.ipynb, and train the model by running the notebook. This will send aggregations of your train & test data to Aporia.
Make sure that everything is working as it should, by running the tests,
$ pytest
Then, start the web service,
$ python pipeline/serve_model.py --aporia-model-id <APORIA_MODEL_ID> --aporia-model-version <APORIA_MODEL_VERSION>
And in another shell send it a request for a prediction,
$ curl http://localhost:8000/api/v1/predict \
--request POST \
--header "Content-Type: application/json" \
--data '{"id": "001", "f1": 0.2, "f2": "c2"}'
Which should return,
{
"y": 0.3251021235012182
}If you've got this far, it's now time to deploy to Kubernetes.
In order to run this example pipeline, you will need access to a Kubernetes cluster. Check out our guide to get up-and-running with a single-node test cluster on your local machine, in under 10 minutes!
To enable ML model monitoring with Aporia, you will need to deploy your Aporia token to the cluster (as an encrypted secret that the web service can retrieve securely). This can be done with the following command,
$ bodywork create secret aporia \
--group prod \
--data APORIA_TOKEN=PASTE_YOUR_TOKEN_IN_HERE \
--data APORIA_HOST=app.aporia.com \
--data APORIA_ENVIRONMENT=production
If you're using an on-premise Aporia cluster, make sure to change APORIA_HOST as well.
First, make sure to set the correct model ID & version in bodywork.yaml. Then deploy the pipeline,
$ bodywork create deployment https://github.com/bodywork-ml/bodywork-pipeline-with-aporia-monitoring
The deployment is configured to expose the endpoint via an ingress controller, which will be reached as follows,
$ curl http://YOUR_CLUSTERS_EXTERNAL_IP/bodywork-aporia/serve-model/api/v1/predict \
--request POST \
--header "Content-Type: application/json" \
--data '{"id": "001", "f1": 0.2, "f2": "c2"}'
Which will return,
{
"y": 0.3251021235012182
}As before. See here for instruction on how to retrieve YOUR_CLUSTERS_EXTERNAL_IP.
To clean-up the deployment in its entirety run,
$ bodywork delete deployment bodywork-aporiaThis repository is a GitHub template repository that can be automatically copied into your own GitHub account by clicking the Use this template button above.
After you've cloned the template project, use official Bodywork documentation to help modify the project to meet your own requirements.