This project was created for a presentation at the 2018-02-03 Queen City Hacks meeting. The purpose of the project was to provide an illustration of how Spark can be used to perform a computation on a cluster of worker nodes. This code is not intended to be the most efficient implementation of the algorithm but rather to provide a useful illustration of how things can be done in Spark.
- Distributed computation platform
- https://i0.wp.com/www.crackinghadoop.com/wp-content/uploads/2015/11/sparkEco.png?resize=859%2C526
- http://image.slidesharecdn.com/sparkarchitecture-jdkievv04-151107124046-lva1-app6892/95/apache-spark-architecture-44-638.jpg?cb=1446900275
- https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
- Breaks computations into stages
- Operates on collections called Resilient Distributed Datasets
- Immutable collection of values
- Resilience
- Computational history of RDD tracked by spark
- Regenerated if node failure causes data loss
- Distribution
- Each RDD consists of 1 or more partitions
- Partitions distributed to across worker nodes
- Two types of RDDs
- Individual values
- Key/Value pairs
- Stages follow one another and produce new data sets from previous ones
- http://image.slidesharecdn.com/jumpstartwithspark2-161216190918/95/jump-start-with-apache-spark-20-on-databricks-24-638.jpg?cb=1481915465
- Each stage is a series of transformations
- Input is one RDD and output is a new one
- At each stage distributes RDD across all workers in each stage
- https://dzone.com/storage/rc-covers/6616-thumb.png
- RDD data is split evenly among workers
- Each worker computes its result independently of others
- Operations in stages
- map
- flatMap
- filter
- sort
- distinct
- intersection
- union
- coalesce
- repartition
- for pair RDDs operations can be performed independently on the values for each key
- example: summing all values for each key
- How spark programs run in java
- Compile program into jar conaining all the code needed by workers
- Create a spark context and add jar to it
- trigger the job
- Context distributes jar to workers, creates initial RDD, triggers stages and tasks
{kind=link}
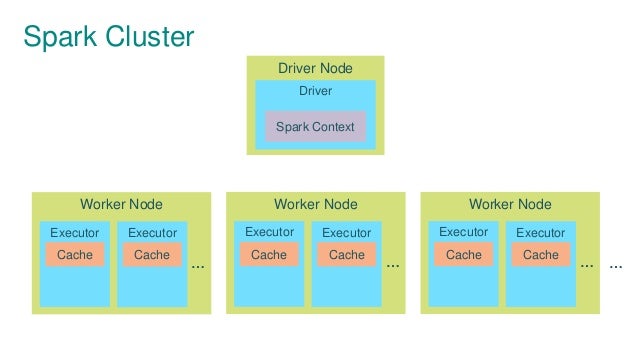{kind=link}
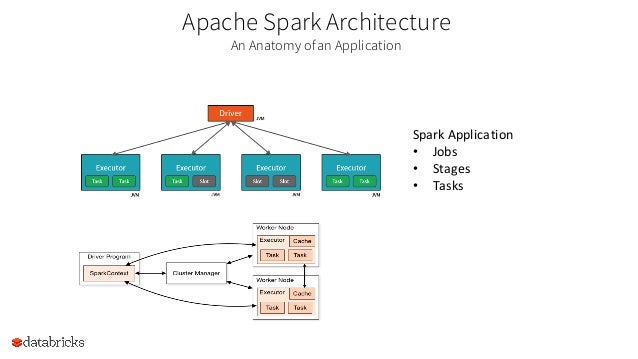{kind=link}
{kind=link}
- Trivial recommendations algorithm for purposes of the demo
- This is not a serious contender for great algorithms
- Intended for use with movies (might work also with songs)
- Database of movies
- For any given movie produce list of all movies to recommend based on user liking that movie
- Rank recommendations for each movie in descending order based on score
- 200 features defined for association with movies
- actor
- director
- genre
- anything else useful
- Every movie has 5 key features
- ranked in order 1-5
- first feature is most important, 5 is least important
- Scores based on common features
- two movies with no features in common get score of zero
- ideal score when two movies have exactly same features in same order
- characteristics of score
- having more features in common increases score
- having common features in different positions decreases score
- algorithm is asymmetric, i.e. score(A,B) != score(B,A)
- Formula
- let Fxn be feature #n of movie x (e.g. FA3 is feature 3 of movie A)
- Compute score as follows:
- Common feature for movie A and B is FAx and FAy.
- score is 15 - 2 * x - abs(x - y)
- Example
- movie A has 5 features in common with movie B in same order
- FA1 -> FB1 => 15 - 2 - abs(1 - 1) == 13
- FA2 -> FB2 => 15 - 4 - abs(2 - 2) == 11
- FA3 -> FB3 => 15 - 6 - abs(3 - 3) == 9
- FA4 -> FB4 => 15 - 8 - abs(4 - 4) == 7
- FA5 -> FB5 => 15 - 10 - abs(5 - 5) == 5
- total score is 45 (best possible score)
- movie A has 1 feature in common with movie B
- FA5 -> FB1 => 15 - 10 - abs(5 - 1) == 1
- total score is 1 (worst possible score)
- note that score for B would be much higher
- FB1 -> FA5 => 15 - 2 - abs(1 - 5) == 9
- movie A has 5 features in common with movie B
- FA1 -> FB5 => 15 - 2 - abs(1 - 5) == 9
- FA2 -> FB4 => 15 - 4 - abs(2 - 4) == 9
- FA3 -> FB1 => 15 - 6 - abs(3 - 1) == 7
- FA4 -> FB2 => 15 - 8 - abs(4 - 2) == 5
- FA5 -> FB3 => 15 - 10 - abs(5 - 3) == 3
- total score is 33 (good but not great)
- movie A has 3 features in common with movie B
- FA1 -> FB2 => 15 - 2 - abs(1 - 2) == 12
- FA3 -> FB1 => 15 - 6 - abs(3 - 1) == 7
- FA4 -> FB5 => 15 - 8 - abs(4 - 5) == 6
- total score is 25 (few common features decent alignment)
- movie A has 2 features in common with movie B
- FA1 -> FB1 => 15 - 2 - abs(1 - 1) == 13
- FA2 -> FB2 => 15 - 4 - abs(2 - 2) == 11
- total score is 24 (few common features but great alignment)
- movie A has 5 features in common with movie B in same order
- Input
- list of all movies
- for each movie a list of 5 features in rank order
- for purposes of demo actually used 500 features per movie instead of 5
- Output
- list of all movies
- for each movie a list of all recommended movies with associated scores
- Steps
- flatMap input Movies into pairs
- key is feature
- value is movie
- aggregate the pairs
- key is feature
- value is set of movies having that feature in any position
- <X, [A,D]>
- <Y, [D,E]>
- <Z, [A,E]>
- flip to RDD of pairs
- key is movie
- value is set of movies having a feature in common with key movie
- <A, [D]>
- <D, [A]>
- <D, [E]>
- <E, [D]>
- <A, [E]>
- <E, [A]>
- every movie will be the key in one pair per feature (5 pairs)
- map every pair into a new pair
- key is movie (unchanged)
- value is set of <movie,score>
- just replace each member in original set with new object that adds score
- use a set that sorts its members by score
- now you have same number of pairs but with scores added
- <A, [score(A,D)]>
- <D, [score(D,A)]>
- <D, [score(D,E)]>
- <E, [score(E,D)]>
- <A, [score(A,E)]>
- <E, [score(E,A)]>
- reduce by key to minimal set of pairs
- reduce takes union of the 5 sets for each key movie
- <A, [score(A,D),score(A,E)]>
- <D, [score(D,A),score(D,E)]>
- <E, [score(E,A),score(E,D)]>
- use a set that sorts its members by score
- reduce takes union of the 5 sets for each key movie
- flatMap input Movies into pairs