Prepare for multiple potentials by defining a list of potentials #332
Conversation
|
@brucefan1983 I've started work on adding support for multiple potentials. I have two questions:
|
|
ping @erhart1 |
|
How do you think one should store the results from all the calls to potential->compute? For the average results one could just add up all the results and then divide by the number of potentials, but that doesn't work for more complicated combinations of the potentials. Isn't this only for NEP models? Does it make sense for other potentials? Do you think that the approach of having a list of potentials makes sense? There had been a list of potentials in older verions where we allowed for hybridization. So defining a list (array) of potentials is not a problem in the code at least. |
|
It sounds like the case you are considering is already the specialized case of using the model ensemble to predict uncertainties. I suggest to also think about how this is supposed to be specified from the user side in the input file. |
I agree that this really only makes sense for NEP potentials, but I don't see the point of having the list of potentials only be NEPs. From what I can tell the code makes it seem like it's simpler to allow any combination of potentials. |
Having a list of potentials also covers the basic use case that you point out, the only thing that differs between the different use cases is when to run
Here is my sketch for the potential nep0.txt ... # Potential0
potential nep1.txt ... # Potential1
observer_mode observe # one of observe, average, uncertainty, corresponding to the cases above.
dump_observer 1000 # Dump frequency with which to evaluate the potentials and dump to file. Here one has to take care to write the potentials in the correct order, but I think that is a pretty intuitive for the user. |
|
Sounds a good plan! |
|
perhaps it's too early to discuss this, I think |
…e. At the moment the number of potentials is not adding up though.
|
@brucefan1983 I've added logic for evaluating all potentials when writing to file (for Lines 90 to 112 in 792e664 Basically each potential writes it's own set of
I also have a suspicion that modifying the Lines 187 to 201 in 792e664 What do you think? |
|
I think if the extra method |
|
Because this new feature is quite experemental, my suggestion is to make sure that existing features are not affected. You can extend the internel code as you have already done for the dump_exyz part, but the features of |
Alright, I'll add the keyword then and only run the function when it is present.
I agree, that's why I only extended Do you have any suggestions for how the other functionality, i.e., running MD on an average PES? I guess I would need to compute the forces with all potentials and add them to an extra GPU Vector? |
|
Yes, you can make this keyword as a new class, similar to Dump_XYZ class. And for the class, you can have GPU_Vector member for the averaged quantities. You can chech some classes such as HAC to see how to do preprocess, process, and postprocess. |
Makes sense! But how would that allow me to use that computed force as the one to run MD with? I assume you mean this class should be under |
|
I see, then you can make new GPU_Vectors for quantities from individual potentials as members in the Force class. Only allocating them if you have the relevant keyword present. Then you can make sure the existing global GPU_Vector for force, energy virial are contain the data you want (from the main potential or the averaged). |
|
@brucefan1983 I've implemented the changes you suggested :) There is now a new class ´dump_observer Lines 385 to 403 in eea2865 I've created two kernels in The use of the kernels in Lines 437 to 473 in eea2865 Two questions remain:
|
|
Alright 👍
I meant if you had any tests that you usually run so that we can make sure that I didn't break anything. As for a multi-potential example, we have some examples at the department that we can probably use. |
|
I usually ran the regression tests in
|
|
If you don't want to do it, I can do at some point. That is to assure that most of the existing features are not broken/affected. Zheyong |
I tried running the tests, but they segfault on my branch. It seems to be because of a CUDA out of memory error, I'm guessing because the program tries to allocate too much. Checking the memory usage its only ~1GB of 16GB. This only seems to happen if I run multiple In GPUMD/src/measure/dump_observer.cu Lines 104 to 110 in affd44f A more likely culprit would be the GPU vectors I allocate for the average properties in Lines 73 to 81 in affd44f |
|
There is no need to free GPU memory manually. It is handled by the GPU_Vector class. The calling of some post-processing function might have side effects. I need to study it in detail to understand it. |
Okay, I see. I think the error is raised during |
|
Yes i will read your changes this weekend. |
|
As far as I understand, you wanted to reuse some code in |
Ah I see, I'll reimplement the logic from |
|
Can you see my comments on the code? Perhaps they are not visible to you? |
No I can't see the comments. |
|
oh, that's strange, you can see them before for the message-passing PR. |
Yeah I've been able to see review comments before. Maybe they are toggled to be private or something? |
|
So you still cannot see this? |

Nope :/ Maybe it has something to do with my permissions/rights? |
|
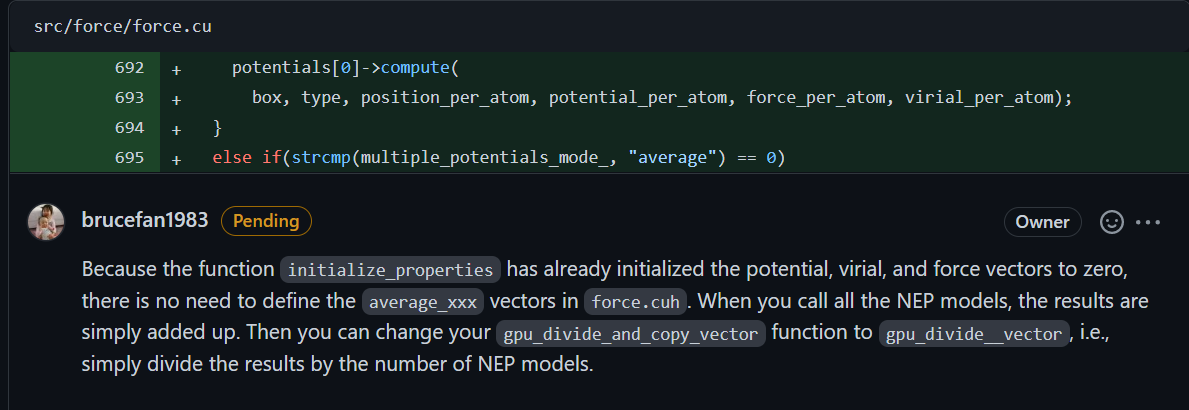
Or a bug of github. You are already a collaborator. Ok, I will copy those images here for your reference:
|





|
@brucefan1983 I've fixed the code according to your review comments. I've also gotten the regression tests running, and I get the same results on If it works on your machine as well, then I believe the only remaining step is adding a specific test for multiple nep potentials. I hope to have time to implement such a test either today or tomorrow. |
|
Ok, I will run the regression tests in my computer, and you can go and prepare the example(s) for the new features. You can create a folder in |
|
I have confirmed that all the regression tests pass in this branch. So you only need to create examples using the new features. |
I've started with the tests for |
|
Sorry to hear that. Have a good rest. It is not in a hurry. |
|
@brucefan1983 I've finished the tests. Please take a look, and if you're happy I think we are ready to merge this :) |
|
I will have a look on friday, thanks |
Adds support for multiple potentials in
gpumd.Use cases:
Checklist
forceto handle a list ofPotentialsforcetake multiple potentialsforce->compute.Fixes #239