GoChat 是一款使用 Golang 实现的简易 IM 服务器,主要特性:
- 支持 websocket 接入
- 单聊、群聊
- 离线消息同步
- 支持服务水平扩展
- Web 框架:Gin
- ORM 框架:GORM
- 数据库:MySQL + Redis
- 通讯框架:gRPC
- 长连接通讯协议:Protocol Buffers
- 日志框架:zap
- 消息队列:RabbitMQ
- 服务发现:ETCD
- 配置管理:viper
docker 安装 MySQL、Redis、ETCD 和 RabbitMQ
# ETCD
docker run -d --name etcd -p 2379:2379 -p 2380:2380 -e ALLOW_NONE_AUTHENTICATION=yes -e ETCD_ADVERTISE_CLIENT_URLS=http://etcd-server:2379 bitnami/etcd:latest
# Redis
docker run -d --name redis -p 6379:6379 redis
# RabbitMQ
docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:management-alpine
# MySQL
docker run -d --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root mysql服务端启动:
- 连接 MySQL,创建 gochat 库,进入执行 sql/create_table.sql 文件中 SQL 代码
- app.yaml 修改配置文件信息
- main.go 启动服务端
客户端启动:
- 启动服务端后,执行 test/router_test.go 中测试可进行用户注册和群创建
- test/ws_client/main.go 启动客户端
- 启动多客户端可成功进行通讯
水平扩展:
- 修改 app.yaml 中
http_server_port、websocket_server_port和port,启动第二个服务端 - 修改 test/ws_client/main.go 中
httpAddr和websocketAddr参数,启动第二个客户端 - 连接不同服务端的客户端间亦可成功通讯
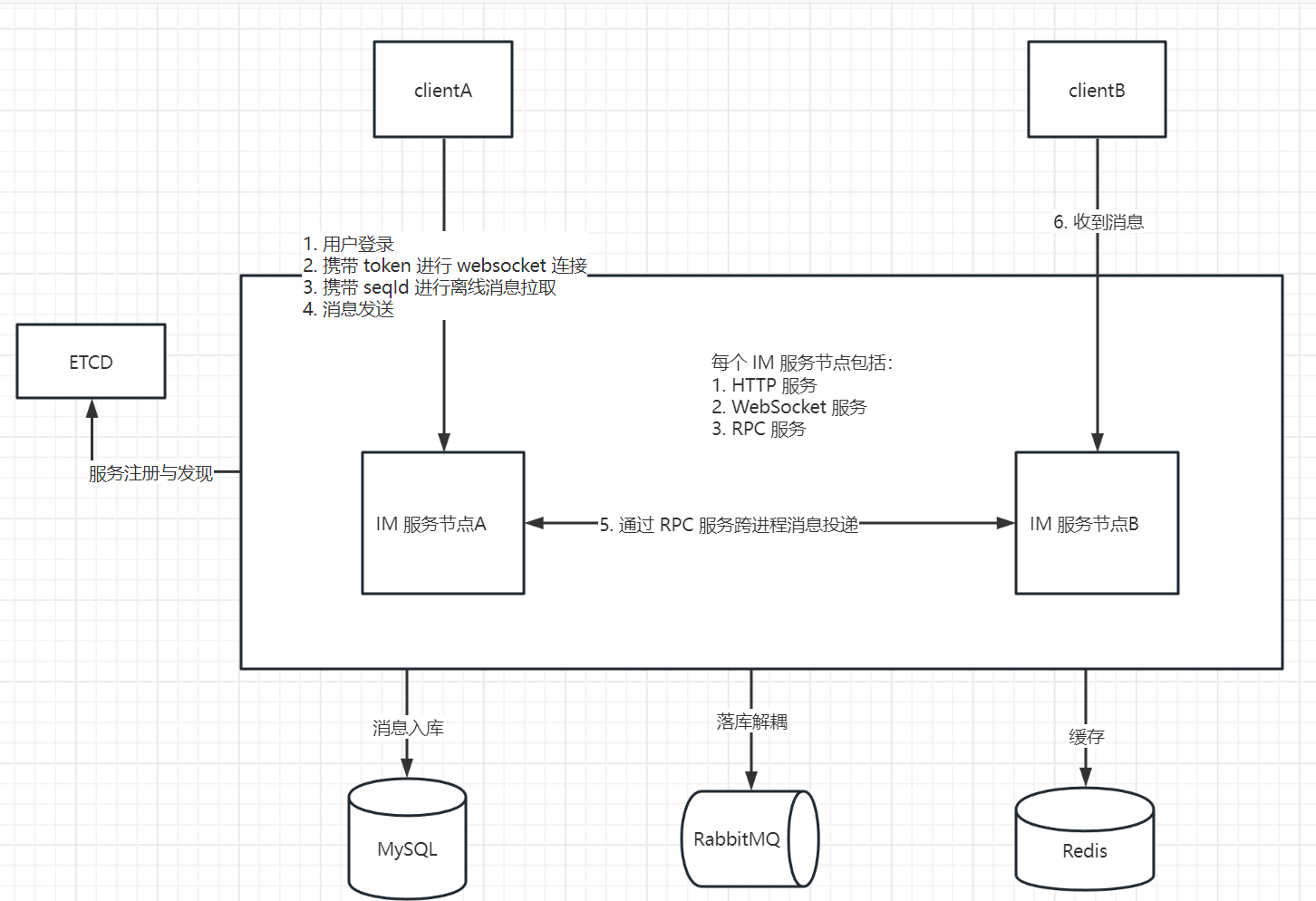
建立 websocket 连接:
- 客户端发送 HTTP 请求,但是携带升级协议的头部信息,路由:/ws
- 服务端接收到升级协议的请求,创建 conn 对象,创建两个 goroutine,一个负责读,一个负责写,然后返回升级响应
- 客户端收到响应信息,成功建立 websocket 连接
A Server
- HTTP upgrade ->
<- Response -
客户端登录:
- 客户端携带
pb.Input{type: CT_Login, data: proto.Marshal(pb.LoginMsg{token:""})}进行登录 - 服务端进行处理后,回复 ACK
- 标记 userId 到 conn 的映射
- Redis 记录 userId 发送消息所在 rpc 地址,跨节点连接能通过该 rpc 地址发送数据到其他节点
- 将该 conn 加入到 connMap 进行心跳超时检测
- 回复 ACK
pb.Output{type: CT_ACK, data: proto.Marshal(pb.ACKMsg{type: AT_Login})
- 客户端收到 ACK,暂时不进行处理
A Server
- Login ->
<- ACK -
心跳和超时检测:
- 客户端间隔时间携带
pb.Input{type: CT_Heartbeat, data: proto.Marshal(pb.HeartbeatMsg{})}发送 - 服务端收到心跳,啥也不干
- 服务端维护的 conn 在每次读数据或写数据后会更新心跳时间,所以收到心跳消息,会更新 conn 活跃时间
- 服务端定期进行超时检测,间隔时间获取全部连接信息,检测连接是否存活,及时清除超时连接
A Server
- Heartbeat ->
上行(客户端发送给服务端)消息投递:
(上行消息依靠 clientId + ACK + 超时重传实现了消息可靠性和有序性,即:不丢、不重、有序)
- 客户端发送消息,消息格式
pb.Input{type: CT_Message, data: proto.Marshal(pb.UpMsg{ClientId: x, Msg:proto.Marshal(pb.Message{})}} - 客户端每次发送消息,clientId++,并启动消息计时器,超时时间内未收到 ACK,再次重发消息
- 服务端收到消息,处理后回复 ACK
- 当且仅当 clientID = maxClientId+1,服务端接收此消息,并更新 maxClientId++
- 进行相应处理
- 回复客户端 ACK
pb.Output{type: CT_ACK, data: proto.Marshal(pb.ACKMsg{type: AT_Up, ClientId: x, Seq: y})
- 客户端收到 ACK 后,取消超时重传,更新 seq(离线消息同步用到)
A Server
- Message ->
<- ACK -
单聊、群聊消息处理:
- 单聊消息处理:获取接收者id的 seq(单调递增),并将消息存入 Message 表,进行下行消息推送
- 群聊使用写扩散,即当一个群成员发送消息,需要向所有群成员的消息列表插入一条记录(同上单聊)
- 优点是每个用户只需要维护一个序列号(Seq)和消息列表,拉取离线消息时只需要拉取自己的消息列表即可获取全部消息
- 缺点是每次转发时,群组有多少人,就需要插入多少条数据
下行消息投递:
(考虑到性能问题,下行消息投递暂未实现消息可靠性和有序性)
下行消息涉及到一个问题:A 和 Server1 进行通信,投递消息给位于 Server2 的 B 该如何实现?
- Server1 和 Server2 启动时,启动各自的 RPC 服务,当前 Server 通过调用其他 Server 的 RPC 方法,能将消息投递到其他 Server
- Server1 处理完 A 发送的消息,组装出下行消息:
pb.Output{type: CT_Message, data: proto.Marshal(pb.PushMsg{Msg:proto.Marshal(pb.Message{})}) - 消息转发流程:
- 根据 Redis 查询 userId 是否在线,如果不在线,不进行推送
- 根据 connMap 查询是否在本地,如果在本地,进行本地推送
- 如果不在本地,调用 RPC 方法 DeliverMessage 进行推送
A Server1 Server2 B
- Message ->
<- ACK -
-- DeliverMessage >
-- Message ->
离线消息同步:
- 客户端请求离线消息同步,消息格式:
pb.Input{type: CT_Sync, data: proto.Marshal(pb.SyncInputMsg{seq: x})}}} - 服务端收到客户端请求,拉取该 userId 大于 seq 的消息列表前 n 条,返回:
pb.Output{type:CT_Sync, data: proto.Marshal(pb.SyncOutputMsg{Messages: "", hasMore: bool})} - 客户端根据返回值 hasMore 是否为 true,更新本地 seq 后决定是否再次拉取消息
A Server
- Sync ->
<- 返回离线消息 -
名词解释:
- PV(页面浏览量):用户每打开一个网站页面,记录一个 PV,用户多次打开同一页面,PV 值累计多次
- UV(网站独立访客):通过互联网访问、流量网站的自然人。1天内相同访客多次访问网站,只计算为1个独立访客
压测指标:
- 压测原则:每天 80% 的访问量集中在 20% 的时间内,这 20% 的时间就叫峰值
- 公式:(总 PV * 80%)/ (86400 * 20%) = 峰值期间每秒请求数(QPS)
- 峰值时间 QPS / 单台机器 QPS = 需要的机器数量
- 举例:网站用户数 100W,每天约 3000W PV,单机承载,这台机器的性能需要多少 QPS?
(3000 0000 * 0.8) / (86400 * 0.2) ≈ 1398 QPS
- 假设单机 QPS 为 70,需要多少台机器来支撑?
1398 / 70 ≈ 20
使用 pprof
- 引入
github.com/gin-contrib/pprof - 将路由注册进 pprof
pprof.Register(r) - 启动服务
分析 CPU 耗时:
- 访问 /debug/pprof
- 访问 profile 等待 30s 可以得到一份 CPU profile 文件,得到性能数据,下面开始分析
- 通过
go tool pprof -http=":8081" ./profile进入 web 界面查看 CPU 使用情况 - 左上角的 VIEW 中:
- Top 按程序运行时间 flat 排序的函数列表
- Graph 是连线图,越大越红的块耗时越多
- Flame Graph 是火焰图,越大块的函数耗时越多
- Peek 同 top 列表,打印每个函数的调用栈
- Source 按程序运行耗时展示函数内部具体耗时情况 内存情况:
分析其他(内存、goroutine、mutex、block)情况:
- 直接通过
go tool pprof -http=":8081" http://localhost:9091/debug/pprof/heap进入 web 页面查看内存使用情况,其他指标同理
本机压测结果:
/*
------ 目标:单机群聊压测 ------
注:本机压本机
系统:Windows 10 19045.2604
CPU: 2.90 GHz AMD Ryzen 7 4800H with Radeon Graphics
内存: 16.0 GB
群成员总数: 500人
在线人数: 500人
每秒/次发送消息数量: 500条
每秒理论响应消息数量:25 0000条 = 500条 * 在线500人
发送消息次数: 40次
响应消息总量:1000 0000条 = 500条 * 在线500人 * 40次
Message 表数量总数:1000 0000条 = 总数500人 * 500条 * 40次
丢失消息数量: 0条
总耗时: 39 948ms(39s)
平均每500条消息发送/转发在线人员/在线人员接收总耗时: 998ms(其实更短,因为消息是每秒发一次)
如果发送消息次数为 1,时间为:940ms
*/
内存占用: 经过测试 1w 连接数,消耗内存:300M 均约内存占用 30KB/连接,支持百万连接需要 30G 内存,理论上单机是可以实现的,优化方案可以采用 I/O 多路复用减少 goroutine 数
- 接入层尝试实现主从 Reactor 线程模型后,再进行性能测试(参考:https://github.com/eranyanay/1m-go-websockets.git)
更友好的日志- 增加负载均衡,选择合适的 WebSocket 服务
- 实现下行消息可靠性,使用时间轮(参考:https://github.com/aceld/zinx/blob/HEAD/ztimer/timewheel.go)
- 实现 docker-compose 脚本
- 完善客户端 sdk,实现 GUI
- prometheus 系统监控
递增 id 使用微信消息序列号生成的思路,使用双 buffer(参考:http://www.52im.net/thread-1998-1-1.html)- 优化完善,实现更多功能