-
Blogpost with more details: The Joy of Neural Painting
-
The implementation is broken down in a set of Notebooks to ease exploration and understanding
-
This Neural Painters implementation is the core technique used by the collective
diavlexfor their Art+AI collection Residual at Cueva Gallery.

I am sure you know Bob Ross and his program The Joy of Painting where he taught thousands of viewers how to paint beautiful landscapes with a simple and fun way, combining colors and brushstrokes, to achieve great results very quickly. Do you remember him teaching how to paint a pixel at the time? of course not!
However, most of the current generative AI Art methods are still centered to teach machines how to 'paint' at the pixel-level in order to achieve or mimic some painting style, e.g., GANs-based approaches and style transfer. This might be effective, but not very intuitive, specially when explaining this process to artists, who are familiar with colors and brushstrokes.
At Libre AI, we have started a Creative AI initiative with the goal to make more accessible the advances of AI to groups of artists who do not necessarily have a tech background. We want to explore how the creative process is enriched by the interaction between creative people and creative machines.
As first step, we need to teach a machine how to paint. It should learn to paint as a human would do it: using brushstrokes and combining colors on a canvas. We researched the state-of-the-art and despite the great works, there was not really a single paper that satisfied our requirements, until we found Neural Painters: A Learned Differentiable Constraint for Generating Brushstroke Paintings by Reiichiro Nakano [1]. This finding was quite refreshing.
Neural Painters [1] are a class of models that can be seen as a fully differentiable simulation of a particular non-differentiable painting program, in other words, the machine "paints" by successively generating brushstrokes (i.e., actions that defines a brushstrokes) and applying them on a canvas, as an artist would do.
The code available to reproduce the experiments is offered by the author in a series of Google's Colaboratory notebooks available in this Github repo and the dataset used is available in Kaggle. The implementation uses TensorFlow, which is great in terms of performance, but let's face it, it is not great fun to digest TensorFlow's code (specially without Keras ;) ).
Teaching machines is the best way to learn Machine Learning – E. D. A.
We played around with the notebooks provided, they were extremely useful to understand the paper and to generate nice sample paintings, but we decided that in order to really learn and master Neural Painters, we needed to experiment and reproduce the results of the paper with our own implementation. To this end, we decided to go with PyTorch and fast.ai as deep learning frameworks instead of TensorFlow as the paper's reference implementation, to do some tinkering and in the process, hopefully, come with a more accessible piece of code.
GANs are great generative models but they are known to be notoriously difficult to train, specially due to requiring a large amount of data, and therefore, needing large computational power on GPUs. They require a lot of time to train and are sensitive to small hyperparameter variations. We indeed tried first a pure adversarial training following the paper, but although we obtained some decent results with our implementation, in terms of brushstrokes quality, it took a day or two to get there with a single GPU using a Colaboratory notebook and the full dataset.
To overcome these known GANs limitations and to speed up the Neural Painter training process, we leveraged the power of Transfer Learning
Transfer learning is a very useful technique in Machine Learning, e.g., the ImageNet models trained as classifiers, are largely used as powerful image feature extractors, in NLP, word embeddings, learned unsupervised or with minimal supervision (e.g., trying to predict words in the same context), have been very useful as representations of words in more complex language models. In Recommender Systems, representations of items (e.g., book, movie, song) or users can be learned via Collaborative Filtering and then use them not only for personalized ranking, but also for adaptive user interfaces. The fundamental idea, is to learn a model or feature representation on a task, and then transfer that knowledge to another related task, without the need to start from scratch, and only do some fine-tuning to adapt the model or representation parameters on that task.
More precisely, since GANs main components are the Generator and Critic the idea is to pre-train them independently, that is in a non-adversarial manner, and do transfer learning by hooking them together after pre-training and proceed with the adversarial training, i.e., GAN mode. This process has shown to produce remarkable results [2] and is the one we follow here.
The main steps are as described as follows:
-
Pre-train the Generator with a non-adversarial loss, e.g., using a feature loss (also known as perceptual loss). (01_neural_painter_x_training_Generator_Non_Adversarial.ipynb)
-
Freeze the pre-trained Generator weights
-
Pre-train the Critic as a Binary Classifier (i.e., non-adversarially) using the pre-trained Generator (in evaluation mode with frozen model weights) to generate
fakebrushstrokes. That is, the Critic should learn to discriminate between real images and the generated ones. This step uses a standard binary classification loss, i.e., Binary Cross Entropy, not a GAN loss. (02_neural_painter_x_training_Critic_Non_Adversarial.ipynb) -
Transfer learning for adversarial training (GAN mode): continue the Generator and Critic training in a GAN setting. Faster! (03_neural_painter_x_training_GAN_mode.ipynb)
Let's Paint: 04_neural_painter_x_painting.ipynb
The training set consists of labeled examples where the input corresponds to an action vector and the corresponding brushstroke image to the target. The input action vectors go through the Generator, which consists of a fully-connected layer (to increase the input dimensions) and of a Deep Convolutional Neural Network connected to it. The output of the Generator is an image of a brushstroke. The loss computed between the images is the feature loss introduced in [3] (also known as perceptual loss [4]). The process is depicted in Figure 1.
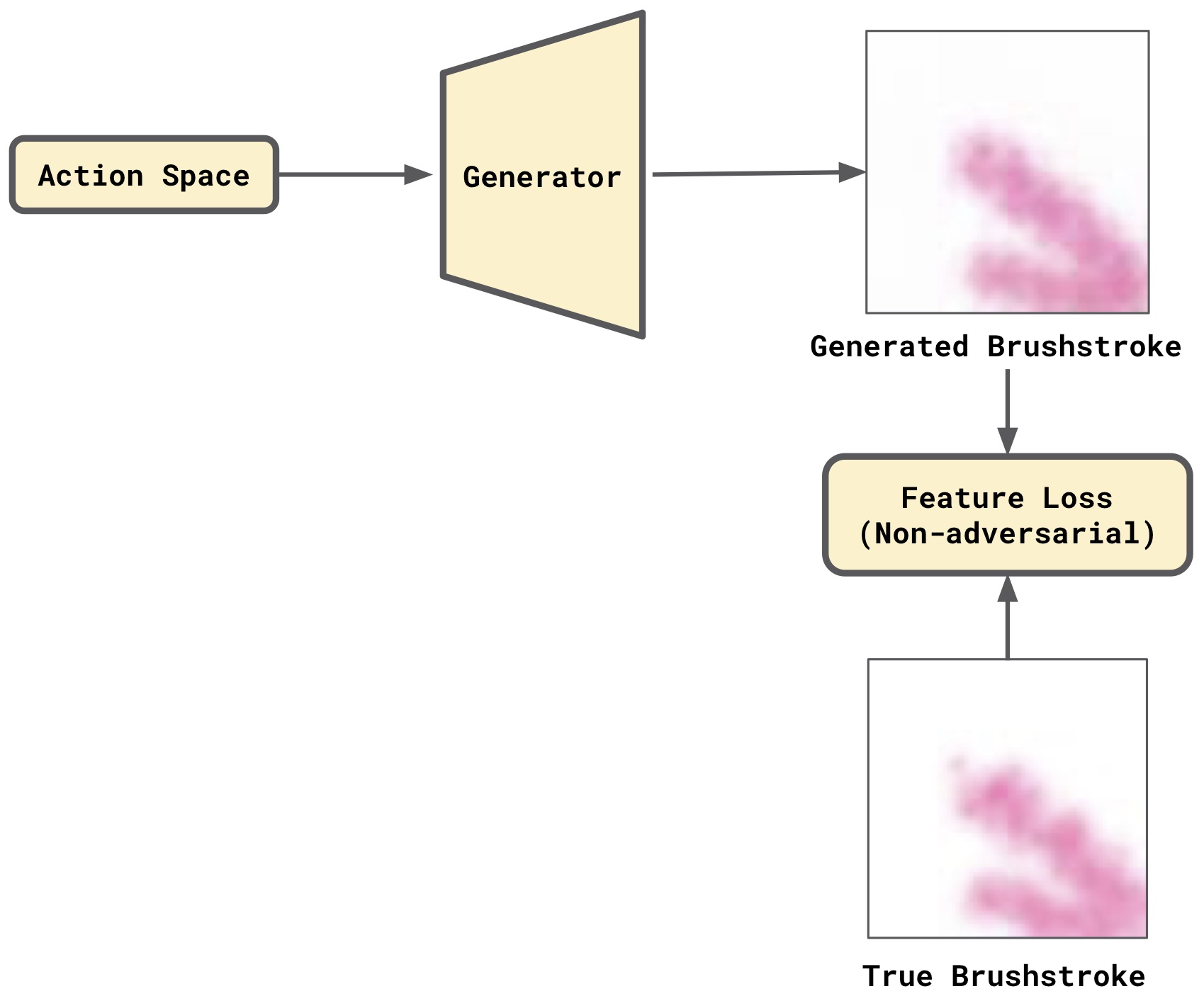
Figure 1. Pre-train the Generator using a (non-adversarial) feature loss.
After pre-training the Generator using the non-adversarial loss, the brushstrokes look like the ones depicted in Figure 2. A set of brushstrokes images is generated that will help us pre-train the Critic in the next step.

Figure 2 . Sample Brushstrokes from the Generator Pre-trained with a Non-Adversarial Loss.
We train the Critic as binary classifier (Figure 3), that is, the Critic is pre-trained on the task of recognizing true vs generated brushstrokes images (Step (2)). We use is the Binary Cross Entropy as binary loss for this step.
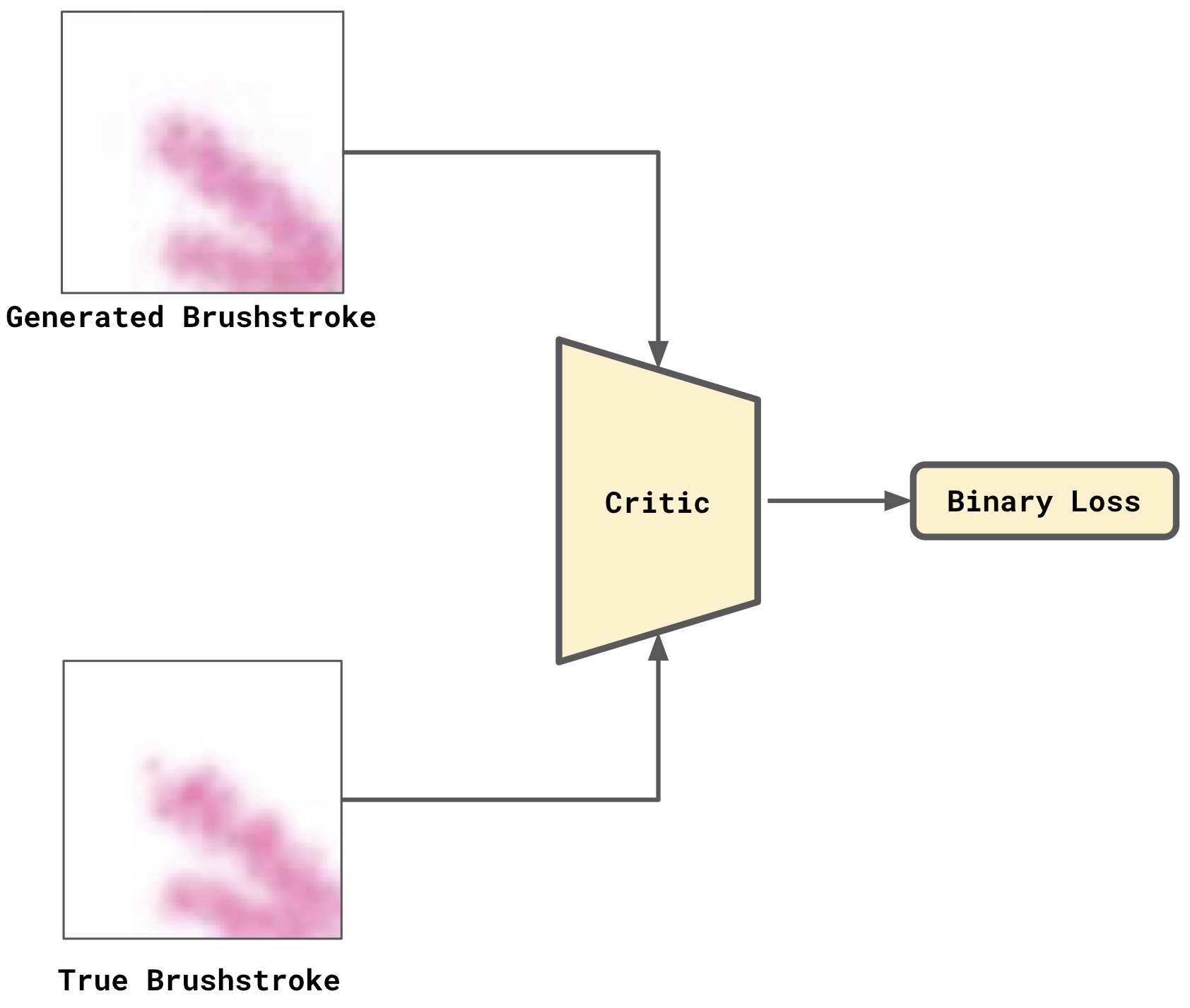
Figure 3 . Pre-train the Critic as a Binary Classifier.
Finally, we continue the Generator and Critic training in a GAN setting as shown in Figure 4. This final step is much faster that training the Generator and Critic from scratch as a GAN.
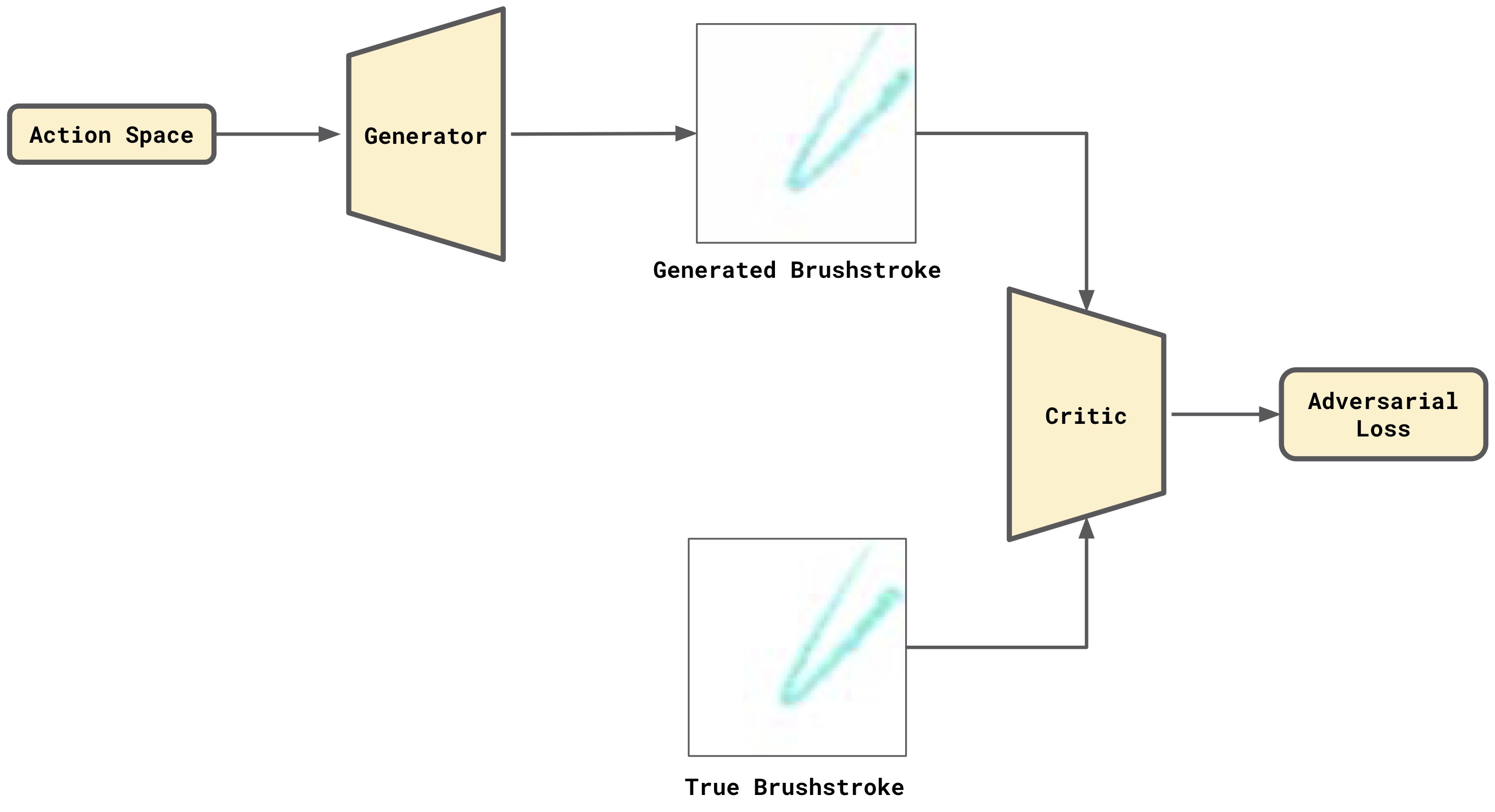
Figure 4 . Transfer Learning: Continue the Generator and Critic training in a GAN setting. Faster.
One can observe from Figure 2 that the pre-trained Generator is doing a decent job learning brushstrokes. However, there are still certain imperfections when compared to the true strokes in the dataset.
Figure 5 shows the output of the Generator after completing a single epoch of GAN training, i.e., after transferring the knowledge acquired in the pre-training phase. We can observe how the brushstrokes are more refined and, although slightly different to the true brushstrokes, they have interesting textures, which makes them very appealing for brushstrokes paintings.

Figure 5 . Sample Brushstrokes from the Generator after Adversarial Training (GAN mode).
Once the Generator training process is completed, we have a machine that is able to translate vectors of actions to brushstrokes, but how do we teach the machine to paint like a Bob Ross' apprentice?
Given an input image for inspiration, e.g., a photo of a beautiful landscape, the machine should be able to create a brushstroke painting for that image. To achieve this, we will freeze the Generator model weights and learn a set of action vectors that when input to the Generator will produce brushstrokes, that once combined, will create such painting, which should look similar to the given image, but of course as a painting :)
The Neural Painters paper [1] introduces a process called Intrinsic Style Transfer, similar in spirit to Neural Style Transfer [6] but which does not require a style image. Intuitively, the features of the content input image and the one produced by the Neural Painter should be similar. The image features are extracted using a VGG16 [7] network as a feature extractor, denoted as CNN in Figure 6, which depicts the whole process.
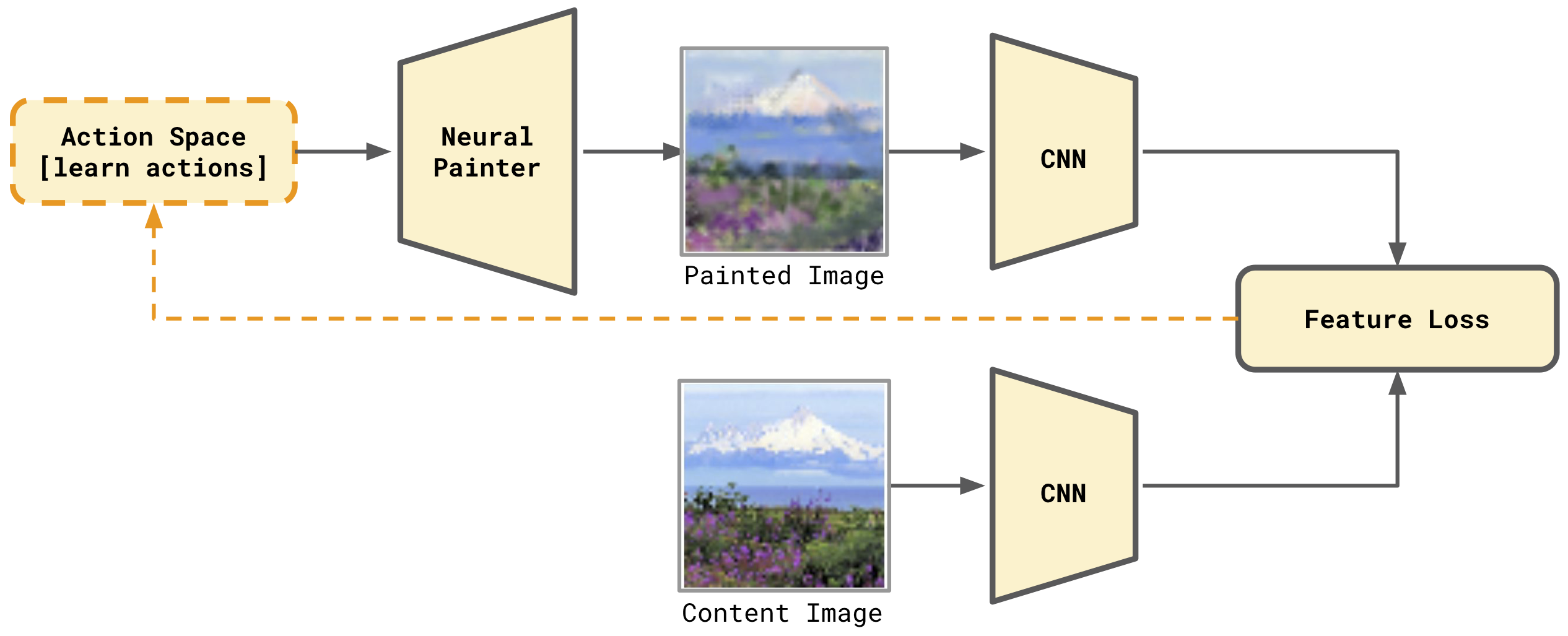
Figure 6. Painting with Neural Painters using Intrinsic Style Transfer.
Note that the optimization process is targeted to learn the tensor of actions, while the remaining model weights are not changed, that is, the ones of the Neural Painter and CNN models. We use the same Feature Loss as before [3].
- For blending the brushstrokes, we follow a linear blending strategy to combine the generated strokes in a canvas, this process is described in detail in a very nice post titled Teaching Agents to Paint Inside Their Own Dreams also by Reiichiro Nakano [5]. We are currently exploring an alternative process that uses the alpha channel for blending.
We would like to thank Reiichiro Nakano for helping us clarifying doubts during the implementation of our Neural Painters and for his supportive and encouraging comments and feedback. Thanks a lot Reiichiro! @reiinakano.
[1] Neural Painters: A Learned Differentiable Constraint for Generating Brushstroke Paintings. Reiichiro Nakano arXiv preprint arXiv:1904.08410, 2019. Github repo.
[2] Decrappification, DeOldification, and Super Resolution. Jason Antic (Deoldify), Jeremy Howard (fast.ai), and Uri Manor (Salk Institute) https://www.fast.ai/2019/05/03/decrappify/ , 2019.
[3] Fast.ai MOOC Lesson 7: Resnets from scratch; U-net; Generative (adversarial) networks. https://course.fast.ai/videos/?lesson=7 ; Notebook: https://nbviewer.jupyter.org/github/fastai/course-v3/blob/master/nbs/dl1/lesson7-superres.ipynb [Accessed on: 2019–08]
[4] Perceptual Losses for Real-Time Style Transfer and Super-Resolution. Justin Johnson, Alexandre Alahi, Li Fei-Fei https://arxiv.org/abs/1603.08155, 2016
[5] Teaching Agents to Paint Inside Their Own Dreams. Reiichiro Nakano. https://reiinakano.com/2019/01/27/world-painters.html, 2019
[6] A Neural Algorithm of Artistic Style. Leon A. Gatys, Alexander S. Ecker, Matthias Bethge. https://arxiv.org/abs/1508.06576, 2015
[7] Very Deep Convolutional Networks for Large-Scale Image Recognition. Karen Simonyan, Andrew Zisserman. https://arxiv.org/abs/1409.1556, 2014