
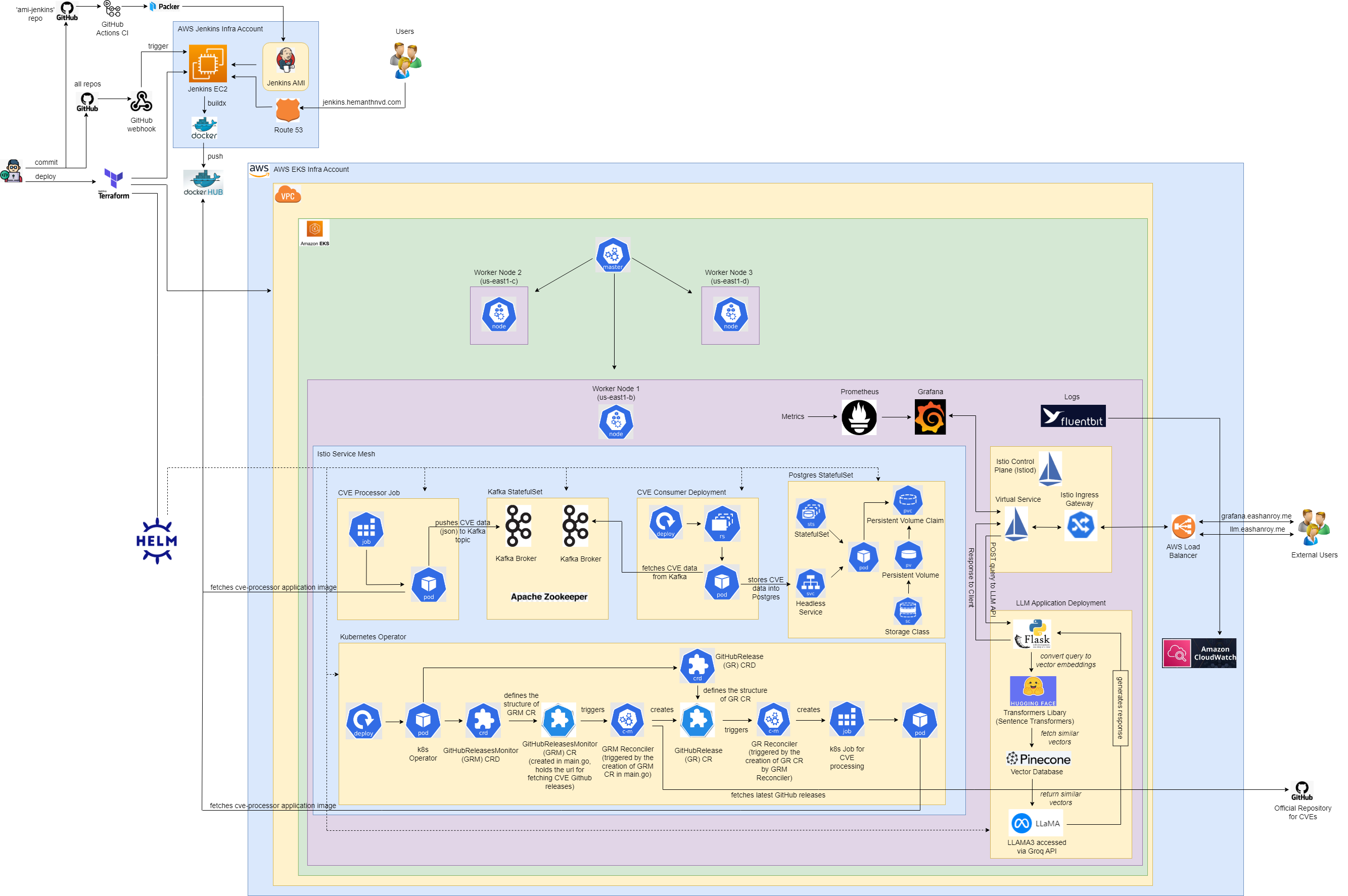
This project delivers a scalable, cloud-native solution for processing and retrieving CVE data, powered by Kubernetes, microservices, and a Retrieval-Augmented Generation (RAG) model integrated with a large language model (LLM).
Built on AWS EKS with Go, Kafka, and PostgreSQL, the system continuously monitors the official CVE GitHub repository, processes new releases, and stores the data for easy querying. Users can submit queries through an API, and our LLM-powered application—integrating Flask, Hugging Face, Pinecone, and LLaMA3—provides intelligent responses based on the latest CVE data.
The infrastructure is managed with Terraform and Helm, ensuring high availability and reliability. Jenkins handles automated CI/CD, while Istio secures inter-service communication. Logging and monitoring are streamlined through FluentBit, CloudWatch, Prometheus, and Grafana.
-
CVE Processor and Consumer Application written in Go
The core of our system is built around a Go-based CVE Processor that downloads, extracts, and processes JSON files from CVEProject's Official GitHub Repository, and then pushes it to a Kafka topic.Next, we have a Go-based CVE Consumer that retrieves those messages from Kafka and stores them in a PostgreSQL database. Before storing in Postgres, we have Flyway migration scripts to automatically create the necessary schema, tables, and views in PostgreSQL.
We maintain Dockerfiles for the Flyway migration scripts, the CVE processor, and the CVE consumer applications. These Docker images are integrated into custom Helm charts that are deployed to an EKS Cluster, provisioned through Terraform. The PostgreSQL database is deployed using Bitnami's Helm chart.
Whenever we push code to these repositories on GitHub, Jenkins builds and publishes multi-architecture Docker images (supporting both arm and amd architectures) to our private Docker Hub repositories.
-
CI/CD with Jenkins, Jenkins AMI with Packer
The Jenkins AMI is built using Packer templates, deployed via a GitHub Actions Workflow. Once the AMI is created, Terraform provisions the Jenkins server using this custom AMI.The Jenkins server is configured to host multiple DSL jobs that automatically scan for Jenkinsfiles across all our GitHub repositories. These Jenkinsfiles define our automated CI/CD pipelines, which include:
- Commit linting to enforce consistent commit messages.
- Building and pushing multi-architecture Docker images (supporting ARM and x86).
- Semantic versioning for both Helm charts and Docker image tags, ensuring proper version management across deployments.
This setup allows for fully automated and reliable CI/CD processes across our entire ecosystem.
-
Infrastructure with Terraform, Kubernetes, and Helm Charts
Our infrastructure spans two AWS accounts within an AWS organization: the Jenkins Infra Account and the EKS Infra Account. Using Terraform, we provision all cloud resources, including the EKS Cluster, along with the supporting infrastructure. The cluster is bootstrapped with several Kubernetes namespaces dedicated to our microservices, and the deployment of applications is automated using Terraform’s Helm provider.We manage deployments through Helm charts for the following components:
- CVE Processor
- CVE Consumer
- Postgres (for persistent data storage)
- Custom Kubernetes Operator
- Cluster Autoscaler
- FluentBit (for centralized logging)
- Grafana (for visualization of metrics)
- Istio Base, Istiod and Istio Gateway (for service mesh configuration and Istio Ingress Gateway)
- Kafka (for message streaming)
- Kafka Exporter (for monitoring Kafka metrics)
- Prometheus (for metrics collection and monitoring)
These Helm charts ensure that all applications and infrastructure components are deployed in a consistent, repeatable manner, streamlining management across environments.
-
Custom Kubernetes Operator written in Go
We developed a Custom Kubernetes Operator using Kubebuilder. The operator defines two Custom Resource Definitions (CRDs): GitHubReleasesMonitor and GitHubRelease. These CRDs track the GitHub repository for new CVE releases, fetches them and processes them.-
CRD and Controller: The
GitHubReleasesMonitorCRD specifies the repository URL and amonitorFromvalue to track releases. The controller watches for events on these resources and triggers the required reconciliation logic. -
Reconciliation Process: When a GitHubReleasesMonitor resource (CR) is created, the controller reconciles it by making API calls to GitHub to fetch new CVE releases. For each new release, a GitHubRelease resource (CR) is created. This triggers another reconciliation loop, which launches a Kubernetes Job to process the CVE data, using the containerized CVE processor application.
-
Deployment: We build an image of the operator and deploy it as a Kubernetes Deployment via Helm Chart. The Helm chart bundles all necessary resources such as the operator's Deployment, Services, and CRDs.
This automated approach enables continuous monitoring of CVE releases and seamless integration of new data into our system.
-
-
Service Mesh with Istio
We implemented Istio as a service mesh to secure and manage communication between our microservices. Istio’s sidecar proxies enhance security, reliability, and observability by controlling and monitoring all service-to-service traffic. Additionally, we utilize Istio's Ingress Gateway and Virtual Services to securely expose select services to the internet, ensuring external access is tightly controlled and monitored. -
Logging with FluentBit and CloudWatch
For centralized logging, we integrated FluentBit, which aggregates logs from both the EKS control plane and all microservices. These logs are forwarded to AWS CloudWatch, providing a unified view for tracing errors and monitoring application behavior across the entire system. -
Monitoring and Visualization with Prometheus and Grafana
To maintain system health and performance, we implemented Prometheus for comprehensive metrics collection. Prometheus scrapes metrics from each microservice, which are then visualized through Grafana dashboards. This setup enables real-time monitoring of CPU, memory, network usage, and application-specific metrics, providing deep insights into system behavior and performance. -
Scalability and Reliability
- Scalability: The system dynamically auto-scales both pods (via Horizontal Pod Autoscaler) and nodes (via Cluster Autoscaler) to meet varying demands. Additionally, we employed Pod Disruption Budgets (PDBs) to minimize service disruptions during scaling operations.
- Reliability: To ensure robust service operation, we deployed liveness and readiness probes for all microservices.
- Avilability: We applied anti-affinity rules to prevent pods from being scheduled on the same node, enhancing fault tolerance and improving the overall availability of services.
-
Security
We implemented the Principle of Least Privilege (PoLP) by enforcing strict IAM roles, RBAC policies, and network policies. Additionally, we secured communications with SSL certificates managed through Kubernetes cert-manager, ensuring robust protection of our system. -
LLM Application Deployment
Our system incorporates an RAG-powered LLM-based CVE question-answer application that generates responses from the latest CVE data. This workflow utilizes several components:-
Flask API:
External users send their queries related to CVEs via this API. These queries are then converted into vector embeddings for further processing. -
Hugging Face Transformers:
We use Hugging Face's Sentence Transformers Library to convert user queries into vector embeddings. This embedding process is essential for finding similar vectors in the vector database. -
Pinecone Vector Database:
The Pinecone Vector Database stores precomputed embeddings for all CVE data. When a query embedding is generated, Pinecone efficiently retrieves the most similar vectors from its database, enabling fast and accurate matching of relevant CVE information. -
LLaMA3 Model:
The similar vectors, along with the query embedding, are provided as a prompt to the LLaMA3 LLM model, which then generates an accurate, context-aware response. We access the LLaMA3 model via the Groq API, ensuring high-performance and accurate query handling.
This architecture allows external users to query the system for insights into the latest CVEs, with real-time processing and response generation powered by state-of-the-art machine learning models and vector databases.
-