A graph-based dependency parser, trained on linguistic features with the (averaged) structured-perceptron. This project is an mash-up of the following ingredients:
Dependecy parsing with an MST algorithm from McDonald et al. 2006, and the training objective of Dozat and Manning 2017 (for each token predict a head).
Inspired by and partially based on the spaCy blog posts Parsing English in 500 Lines of Python and A Good Part-of-Speech Tagger in about 200 Lines of Python.
The feature-set is largely taken from McDonald et al. 2005. For the Universal Dependencies dataset we can also make good use of the lemma and feats fields, but I haven't come around to this yet.
All code to do handle conllu and conllx files is taken from bastings parser.
To obtain data from the Universal Dependencies project, type:
cd data
./get-ud.shBy default, this downloads the English-EWT dataset. The script will give you the option to download a second language from a selection of provided languages.
You can also use the PTB. We assume you have the PTB in standard train/dev/test splits in conll-format, stored somewhere in one directory, and that they are named train.conll, dev.conll, test.conll.
To train the perceptron for 5 epochs on the English UD dataset, type:
./main.py train --epochs 5The training can be halted at any point with cntrl-c. The trained weights are saved as a json file at models/model.json by default. To specify this path use --model path/to/model.
To use another language, e.g. Dutch, type:
./main.py train --lang nl --epochs 5By default the UD dataset is used. If you want to use the PTB, type:
./main.py train --use-ptb --ptb-dir your/ptb/dirTo evaluate the trained perceptron on the development and test set, type:
./main.py eval --model path/to/modelTo plot heatmaps of the predicted score matrices for five sentences in the development set (like those in image) type:
./main.py plot --model path/to/modelTraining can now be done in parallel. To be precise: asynchronous and lock-free, also known as Hogwild! because without locks, processors might block each other wile rewriting memory (like a herd of wild hogs stepping on each others trotters). Since our optimization problem is sparse, meaning that most updates only modify a small number of the total parameters, this does not affect the quality of the learning algorithm.
Just add one flag:
./main.py train --parallelBy default we use all the available processors, so expect some venting.
The basic features are all of the following form:
head dep pos pos=VBN VBZ
head dep word word=is a
head dep pos word=VBN have
head dep suffix suffix=ing is
head dep shape shape=Xxxx dd/dd/dddd
head dep shape shape=xxxx xx
With shape inspired by spaCy's token.shape feature. This feature-set has no positional, context or otherwise sentence-level features.
Optionally you can add distance:
head dep pos pos=VBN have (-1)
head dep word word=is a (1)
With (-1) indicating the linear distance from the head to the dependent. This is a cheap way of giving some sentence-level information to the model.
Optionally you can add left and right surrounding pos tags for context:
head dep i i+1/i-1 i=DT NNS/VBZ VBG
with i i+1 meaning the word itself and its right neighbor.
Finally there is an 'in-between' feature that finds all tags linearly in between head and dependent:
head between dep=DT JJ NNS (2 1)
With (2 1) indicating respectively the distance from head to between, and from between to dependent.
To choose these additional features for the model, type:
./main.py train --features dist surround between(Or any combination from these three.)
Making the full feature set for the training set (~66 million for the basic features) takes about 14 minutes. One epoch with these features on the training set also takes around 15 minutes (~40 sentences per second). After training, we prune the model by removing weights smaller than a certain threshold (1e-3 by default):
Pruning weights with threshold 0.001...
Number of weights: 66,475,707 (64,130,339 exactly zero).
Number of pruned weights: 2,343,424.
Due to the sheer enormity of the feature-set, the model saved model is still pretty big: ~140 MB!
On the PTB we can get the following results:
./main.py train --use-ptb --epochs 3 --features dist surround between # Train UAS 94.97, dev UAS 89.55Averaging the weights makes quite a difference on the dev-set: from 86.87 to 89.55. More epochs will also help.
Let's see the difference in accuracy between Eisner's algorithm and the maximum spanning tree (CLE) decoding:
./main.py eval --model models/model.json --use-ptb --decoder mst # Test UAS 89.61
./main.py eval --model models/model.json --use-ptb --decoder eisner # Test UAS 90.15English has few relatively few non-projective sentences, and yes, Eisner decoding makes some difference accordingly!
Fun fact one: the trained weights of the features are extremely interpretable. Here are the largest ones (from the simple feature-set):
distance=1 29.9918
distance=-1 27.3818
distance=-2 22.3953
distance=2 21.1036
distance=3 18.2438
head dep pos pos=NN PRP$ 17.6982
head dep pos pos=NNS PRP$ 16.0800
head dep pos word=NN a 15.4661
head dep pos pos=NN DT 15.3968
distance=-3 15.1488
head dep shape shape=XXXXX . 14.9128
head dep pos word=NN of 14.8744
head pos=VBN 14.7640
head dep pos word=VBZ . 14.7317
head dep pos pos=VBD . 14.5186
head dep pos pos=NNS JJ 14.3879
head pos=VBD 14.3672
head pos=VBZ 14.0784
head dep pos pos=VBZ . 14.0720
distance=4 13.8039
head dep pos pos=NN JJ 13.1833
head dep pos pos=IN NNS 12.8427
head dep pos word=CD than 12.7341
head pos=VBP 12.6299
head dep word pos=% CD 12.5798
head dep pos pos=NNS DT 12.5320
head dep pos word=VBP . 12.3965
head dep pos word=VB that 12.3921
head dep pos pos=IN NNPS 12.3371
head dep pos word=VBD . 12.2725
Fun fact two: We can make some nifty heatmaps out of the score matrices:
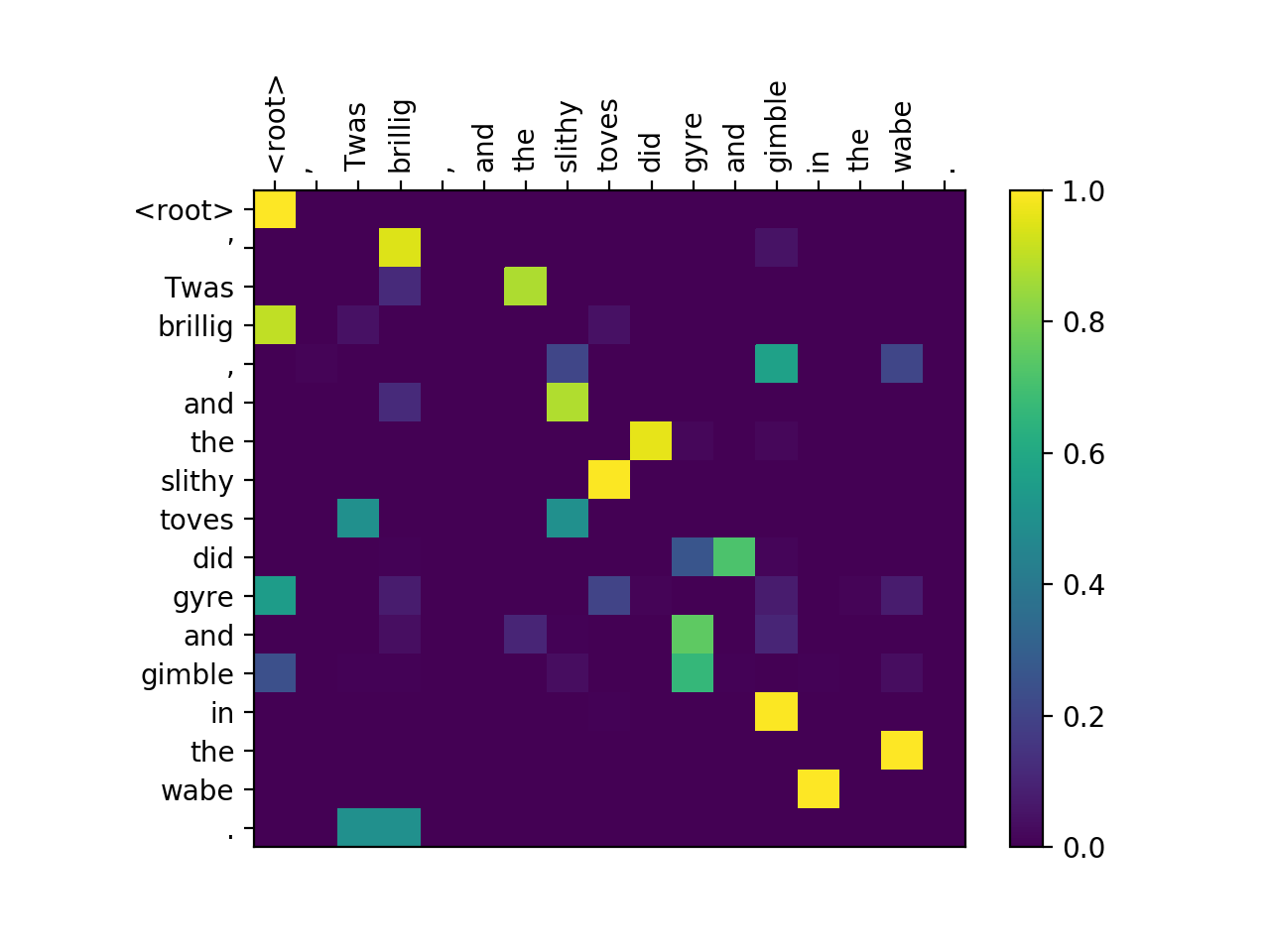
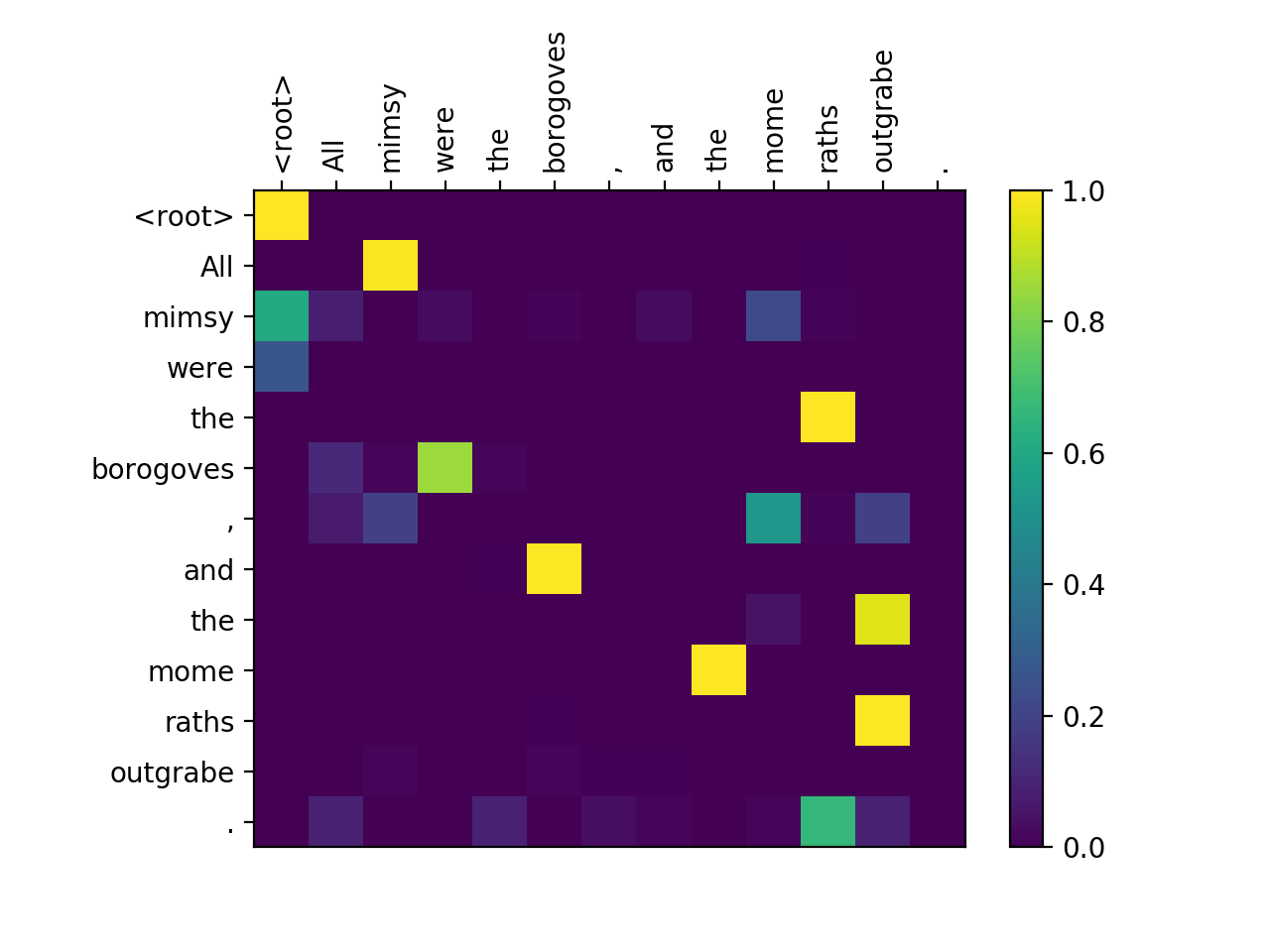
python>=3.6.0
numpy
matplotlib
tqdm
- Make a new class
DependencyParserand remove parsing specific methods fromPerceptronto there. - Make integration with Universal Dependencies easier. (Now only using conllx format)
- Make data loading less name-dependent.
- Perform full training till convergence.
- Make training parallel ('hogwild'). Really easy, and perhaps even some regularization.
- Prune the averaged weights by removing all features that are exactly 0.
- Decide: extract features from all possible head-dep pairs in training data, or only for gold head-dep pairs? (It makes a very large memory and speed difference)
- When we make features from all possible head-dep pairs, maybe we should prune this feature-set before training? E.g. remove all features that occur less than 10 times?
- Parsing is really confusing for UD: the ones with
20.1type word-ids, how to parse these!? - The
eval.plscript complains:Use of uninitialized value in subtraction (-) at scripts/eval.pl line 954, <SYS> line 41816.I don't like that -- it messes with my clean message logging efforts. - Predict labels. Maybe a second perceptron altogether for that?
- Understand which features matter.
- Enable weight-averaging for parallel training.
- Evaluate model trained on one UD dataset, on another dataset (same language!), e.g. from another domain. For example: Is the model robust against these domain changes?