这是一个轻松赚钱的项目。
短视频时代,谁掌握了流量谁就掌握了Money!
所以给大家分享这个经过精心打造的MoneyPrinter项目。
它可以:使用AI大模型技术,一键批量生成各类短视频。
它可以:一键混剪短视频,批量生成短视频不是梦。
它可以:自动把视频发布到抖音,快手,小红书,视频号上。
赚钱从来没有这么容易过!
觉得有用的朋友,请给个star!

https://www.bilibili.com/video/BV1JKgYe5ERF/?pop_share=1&vd_source=a563b6c970df6e7665845c15089bd618
使用介绍: 重磅!免费一键批量混剪工具它来了,一天上万短视频不是梦
- 视频混剪功能已经上线了!!!!
- 20240628 重磅更新!支持批量视频混剪,批量生成大量不重复的短视频!!!!!!
- 20240620 优化视频合成效果,让视频结束更加自然。
- 20240619 语音识别和语音合成支持腾讯云。 需要开通腾讯云语音合成和语音识别这两个功能
- 20240615 语音识别和语音合成支持阿里云。 需要开通阿里云智能语音交互功能--必须开通语音合成和录音文件识别(极速版)这两个功能
- 20240614 资源库支持pixabay,支持语音试听功能,修复一些bug
- 视频批量混剪,批量产出大量不重复的短视频
- 支持本地素材选择(支持各种素材mp4,jpg,png),支持各种分辨率。
- 大模型接入OpenAI,Azure,Kimi,Qianfan,Baichuan,Tongyi Qwen, DeepSeek,
- 支持Azure语音功能
- 支持阿里云语音功能
- 支持腾讯云语音功能
- 支持100+不同的语音种类
- 支持语音试听功能
- 支持30+种视频转场特效
- 支持不同分辨率,不同尺寸和比例的视频生成
- 支持语音选择和语速调节
- 支持背景音乐
- 支持背景音乐音量调节
- 支持自定义字幕
- 覆盖市面上主流的AI大模型工具
- [] 支持本地语音字幕识别模型
- [] 支持更多的视频资源获取方式
- [] 支持更多的视频转场特效
- [] 支持更多的字幕特效
- [] 视频批量自动发布到各个视频平台
- [] 接入stable diffusion,AI生图,合成视频
- [] 接入Sora等AI视频大模型工具,自动生成视频
| 竖屏 | 横屏 | 正方形 |
|---|---|---|
final-1718158522826.mp4 |
final-1718160166012.mp4 |
final-1718160533551.mp4 |
- Python 3.10+
- ffmpeg 6.0+
- LLM api key
- Azure语音服务(https://speech.microsoft.com/portal)
- 或者阿里云智能语音功能(https://nls-portal.console.aliyun.com/overview)
- 或者腾讯云语音技术功能(https://console.cloud.tencent.com/asr)
切记!!!!! 一定要安装好ffmpeg,并把ffmpeg路径添加到环境变量中。
- 确保你有Python 3.10+的运行环境。如果是windows, 请确保安装了python路径已经添加到了PATH中。
- 确保你有ffmpeg 6.0+的运行环境。如果是windows, 请确保安装了ffmpeg路径已经添加到了PATH中。没有安装ffmpeg的朋友,请通过 https://ffmpeg.org/ 来安装对应的版本。
- 如果python和ffmpeg环境都有了。那么就可以通过pip安装依赖包了。
pip install -r requirements.txt使用下面命令运行程序:
streamlit run gui.py在日志文件中可以看到程序运行的日志信息。
里面有浏览器的地址,可以通过浏览器打开这个地址来访问程序。
打开之后,你会看到下面的界面:
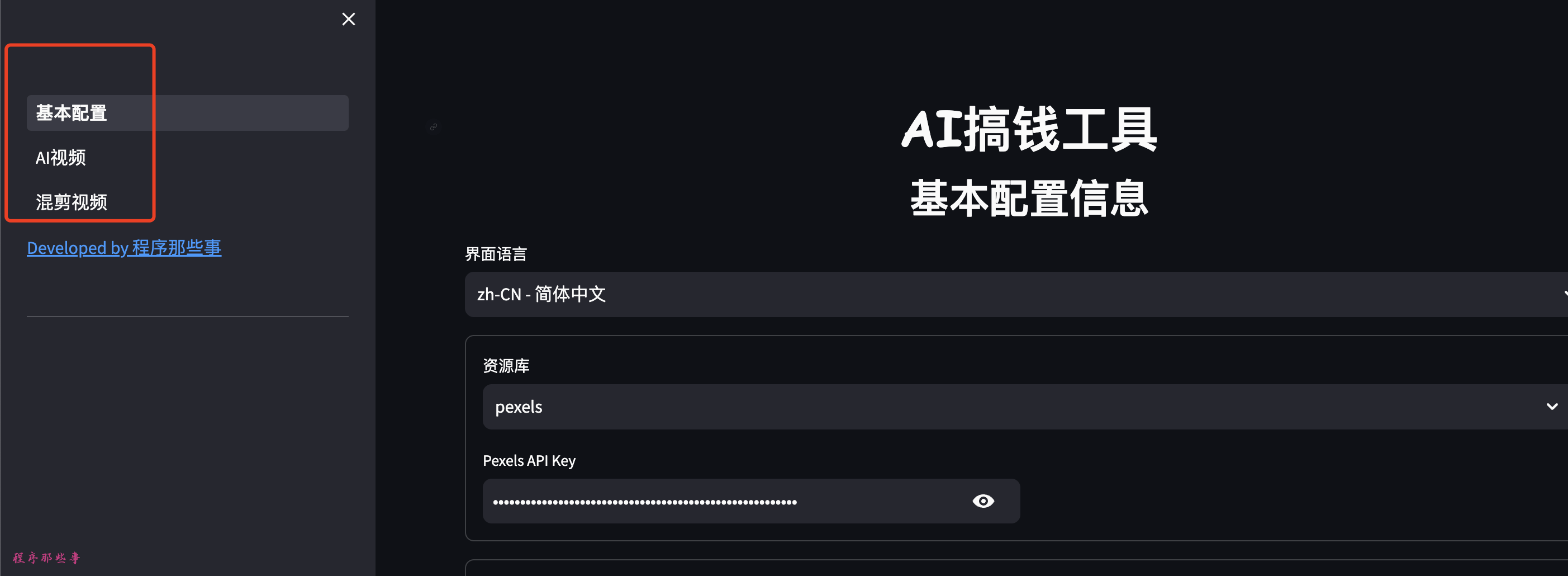
左侧目前有三项配置, 分别是基本配置,AI视频和混剪视频(开发中)。
目前资源支持:
- pexels: www.pexels.com Pexels 是世界上著名的免费图片,视频素材网站。
- pixabay: pixabay.com
大家需要到对应的网站上注册一个key来实现API调用。
后续会陆续添加其他资源库。如(videvo.net,videezy.com 等)
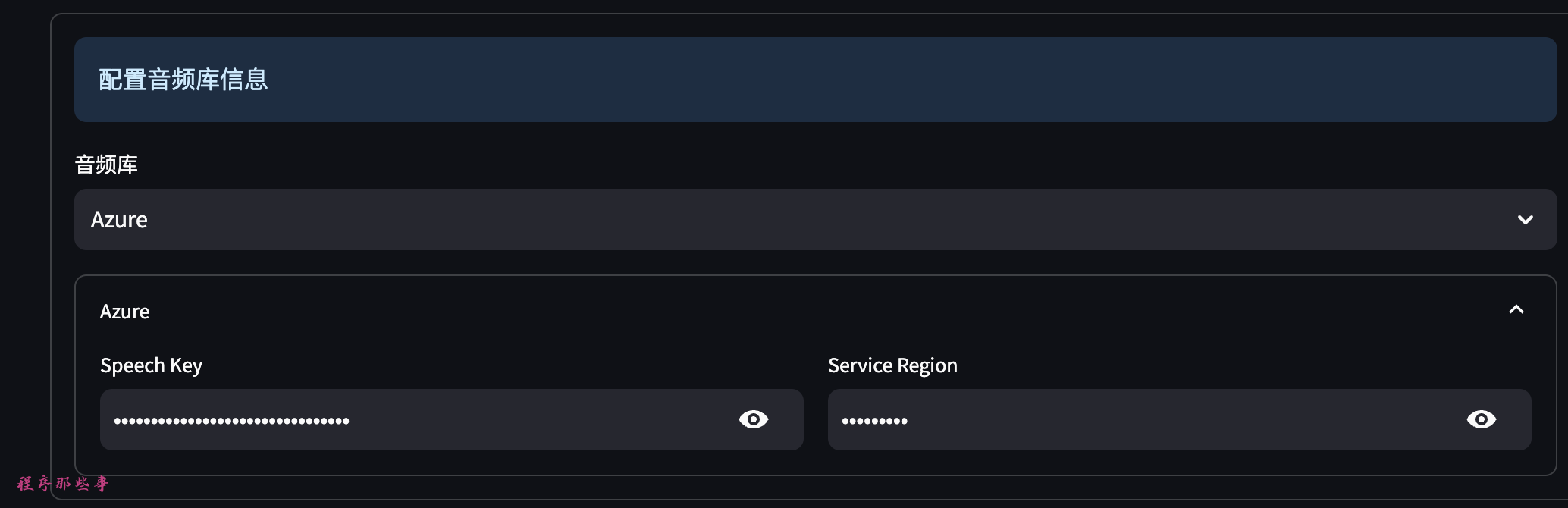
目前文字转语音和语音识别功能支持:
- Azure的cognitive-services服务。
- 阿里云的智能语音交互
- 腾讯云语音技术功能(https://console.cloud.tencent.com/asr)
- Azure:
大家需要到 https://speech.microsoft.com/portal 这里注册一个key。
Azure对新用户是1年免费的。费用也是比较便宜。
- 阿里云:
大家需要到 https://nls-portal.console.aliyun.com/overview 这里开通服务,并添加一个项目。
需要开通阿里云智能语音交互功能--必须开通语音合成和录音文件识别(极速版)这两个功能.
- 腾讯云:
腾讯云语音技术功能(https://console.cloud.tencent.com/asr) 开通语音识别和语音合成功能。
后续会添加本地语音识别大模型。但是文字转语音还是微软的服务最为优秀。
大模型区目前支持Moonshot,openAI,Azure openAI,Baidu Qianfan, Baichuan,Tongyi Qwen, DeepSeek这些。
推荐使用Moonshot。
会陆续添加市面上其他流行的大模型。
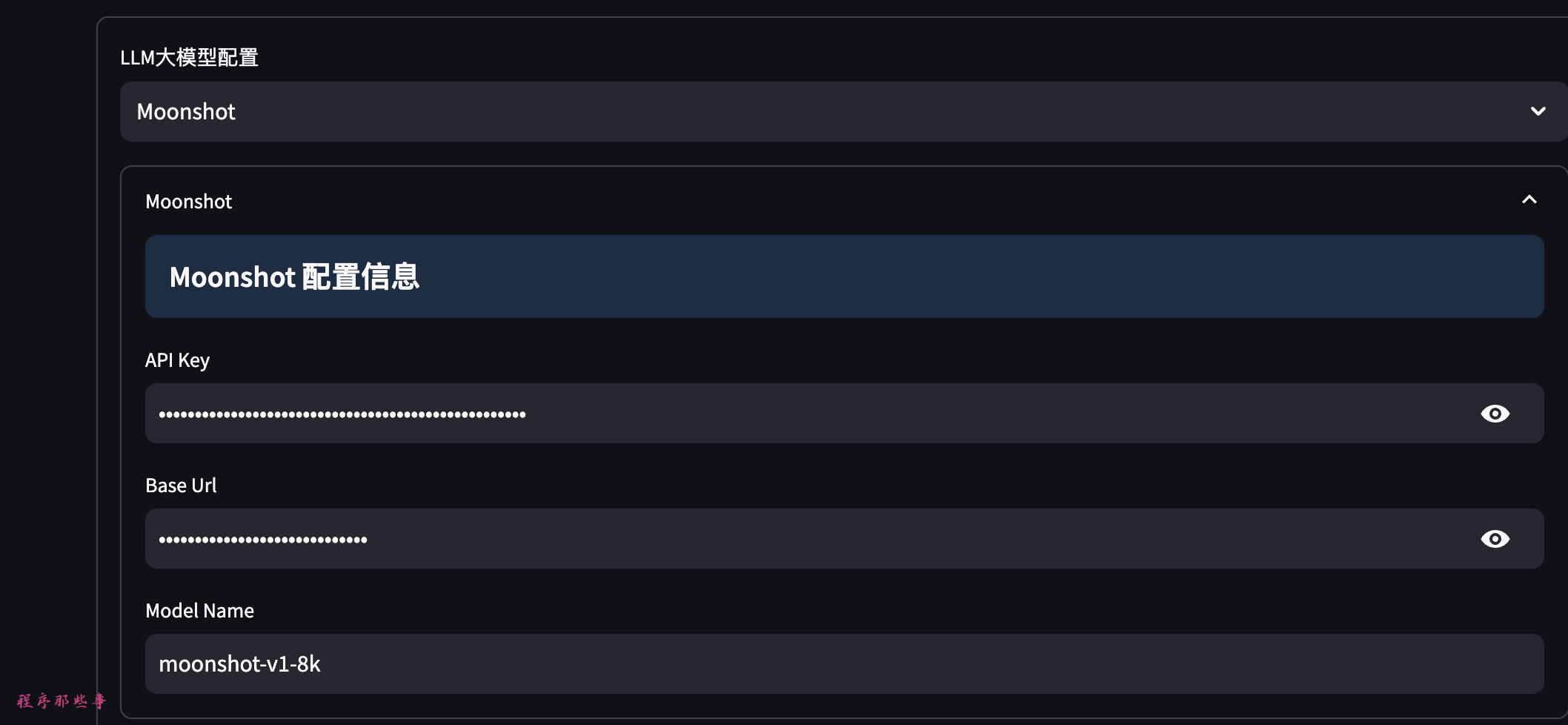
Moonshot API获取地址: https://platform.moonshot.cn/
baidu qianfan API获取地址:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/yloieb01t
baichuan API获取地址: https://platform.baichuan-ai.com/
阿里tongyi qwen API获取地址: https://help.aliyun.com/document_detail/611472.html?spm=a2c4g.2399481.0.0
DeepSeek API获取地址: https://www.deepseek.com/
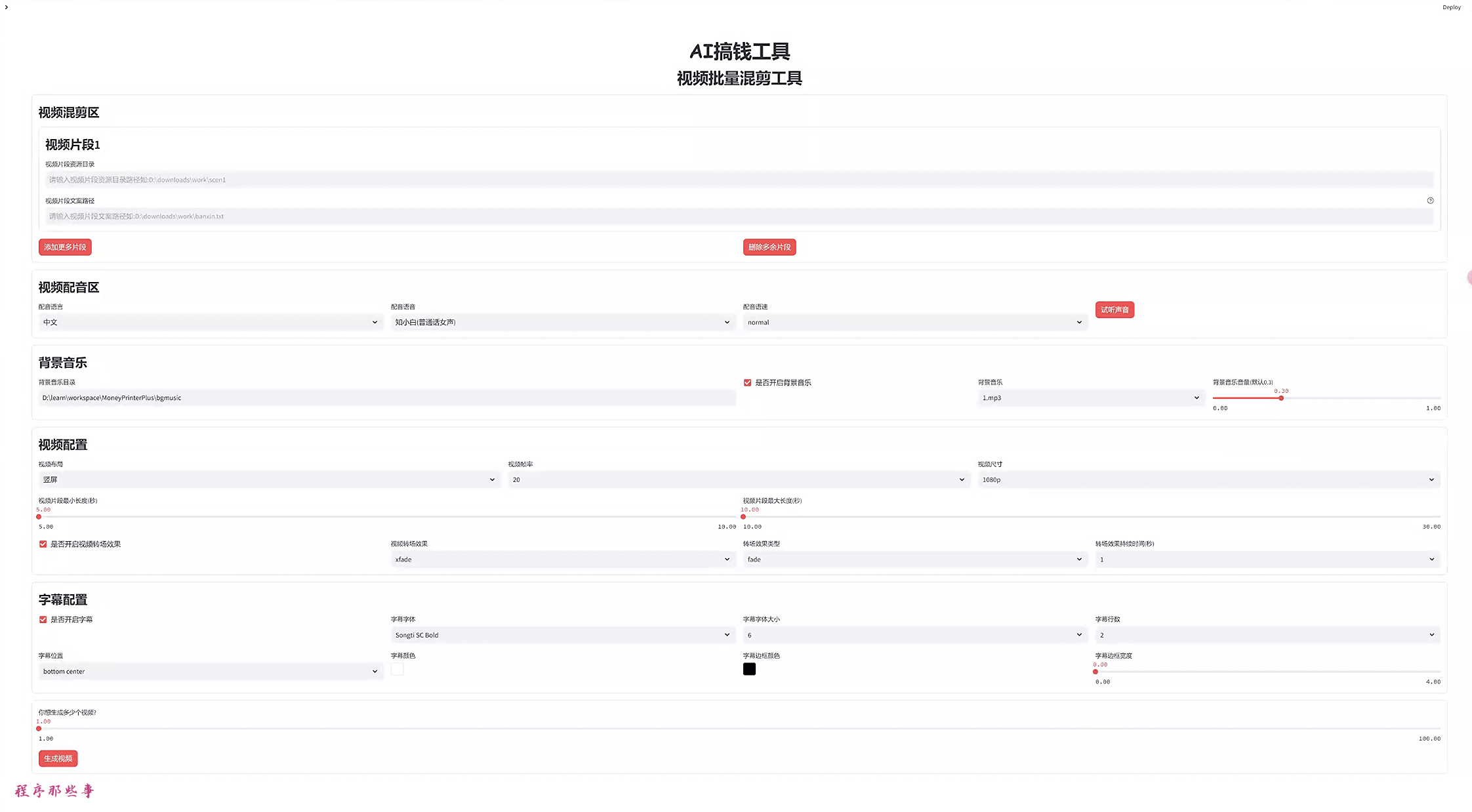
基本配置设置完毕之后。就可以进入到AI视频了。
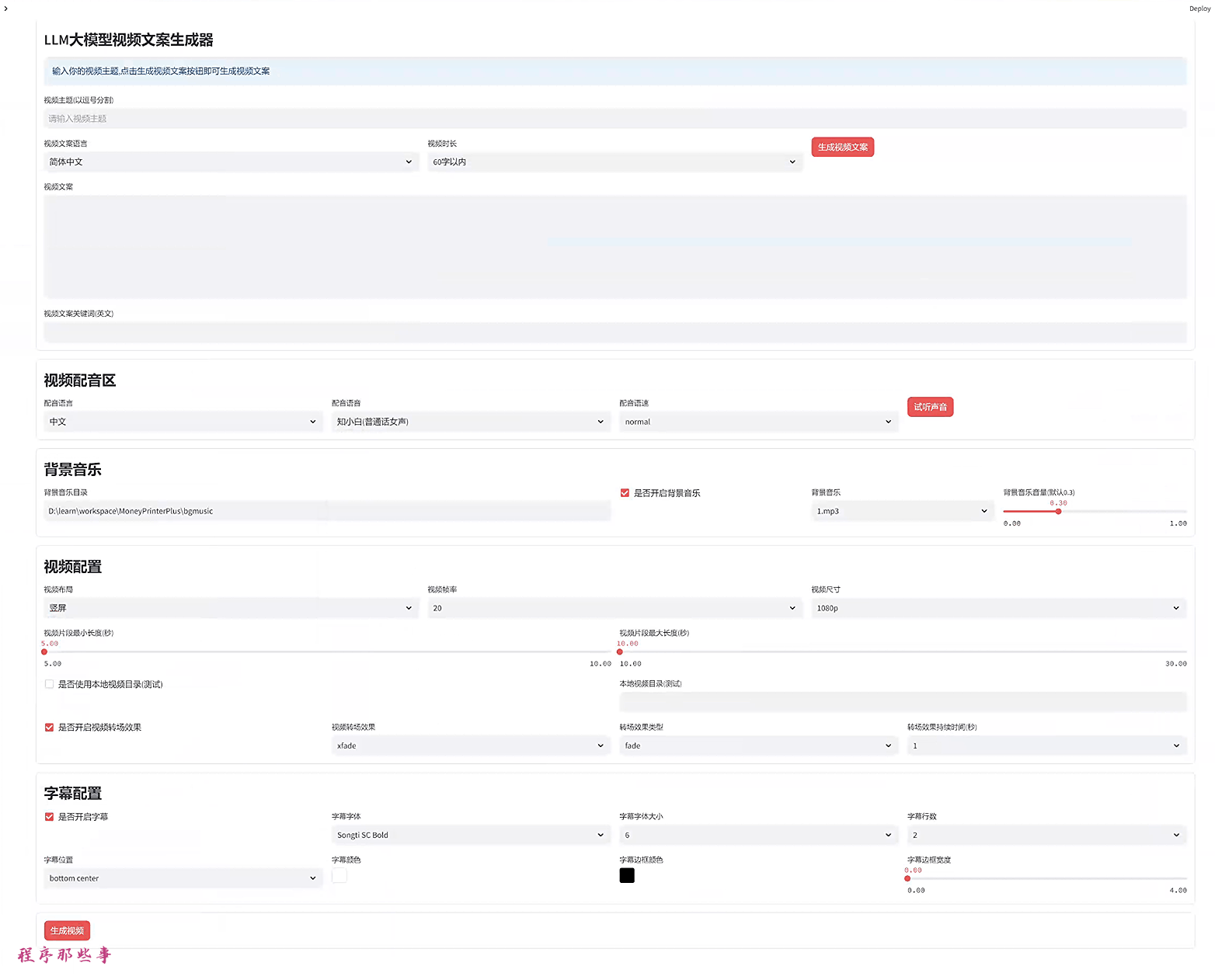
首先,我们给一个关键词,然后用大模型生成视频文案:
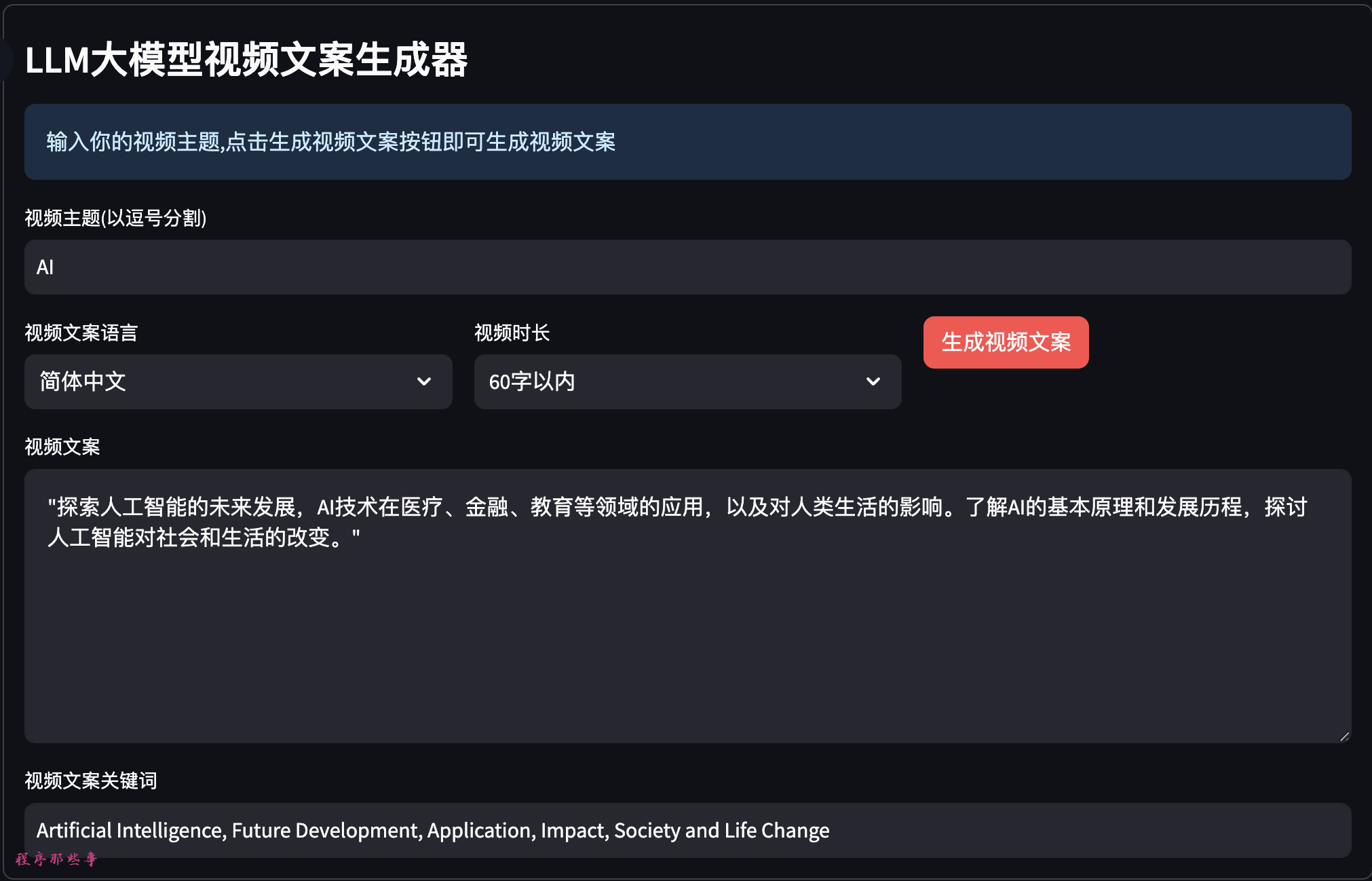
可以选择视频的文案语言,视频时长。
如果大家对视频文案和关键词不满意的话,可以手动修改。
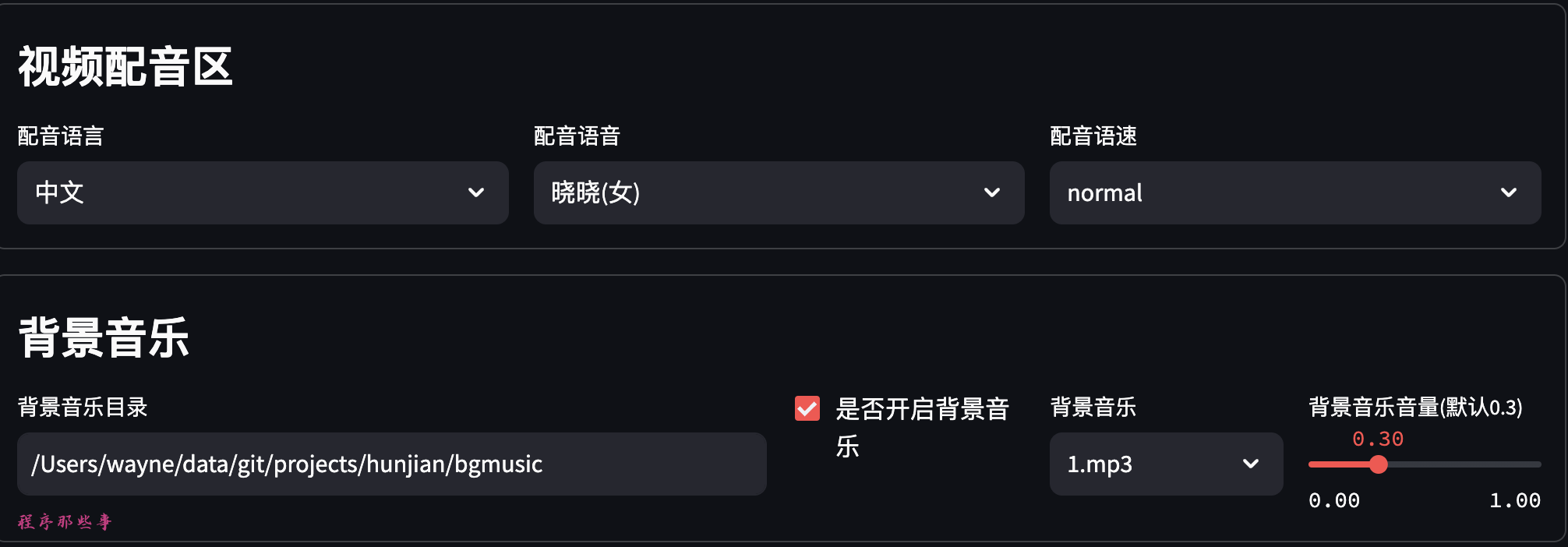
可以选择配音的语言和配音的语音。
还支持配音语速调节。
后续会支持语音试听功能。
背景音乐放在项目的bgmusic文件夹中。
目前里面只有两个背景音乐。大家可以自行添加自己需要的背景应用。
视频配置区,大家可以选择视频的布局,视频帧率,视频尺寸。
视频片段最小长度和最大长度。
还可以开启视频转场效果。目前支持30+转场效果。
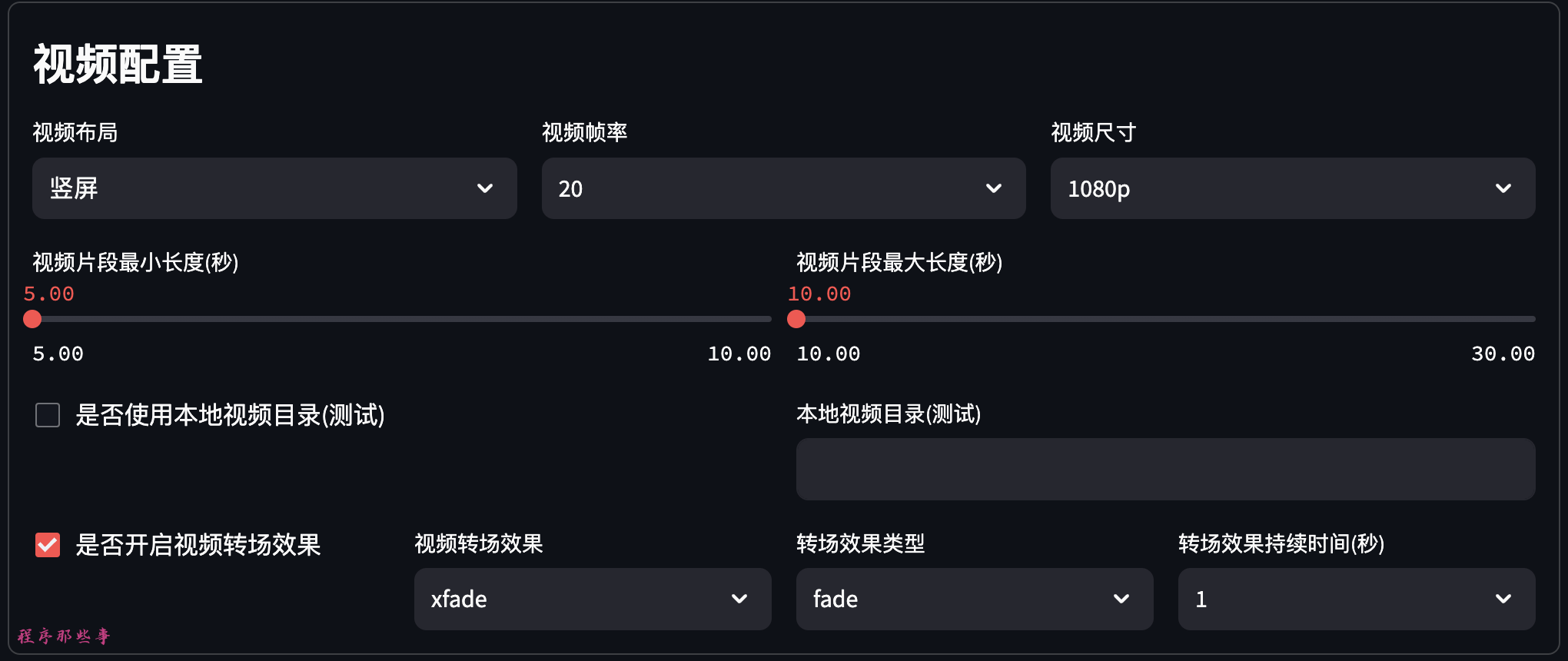
后续会添加使用本地视频资源功能。
字幕文件位于项目根目录的fonts文件夹。
目前支持宋体和苹方两个字体集合。
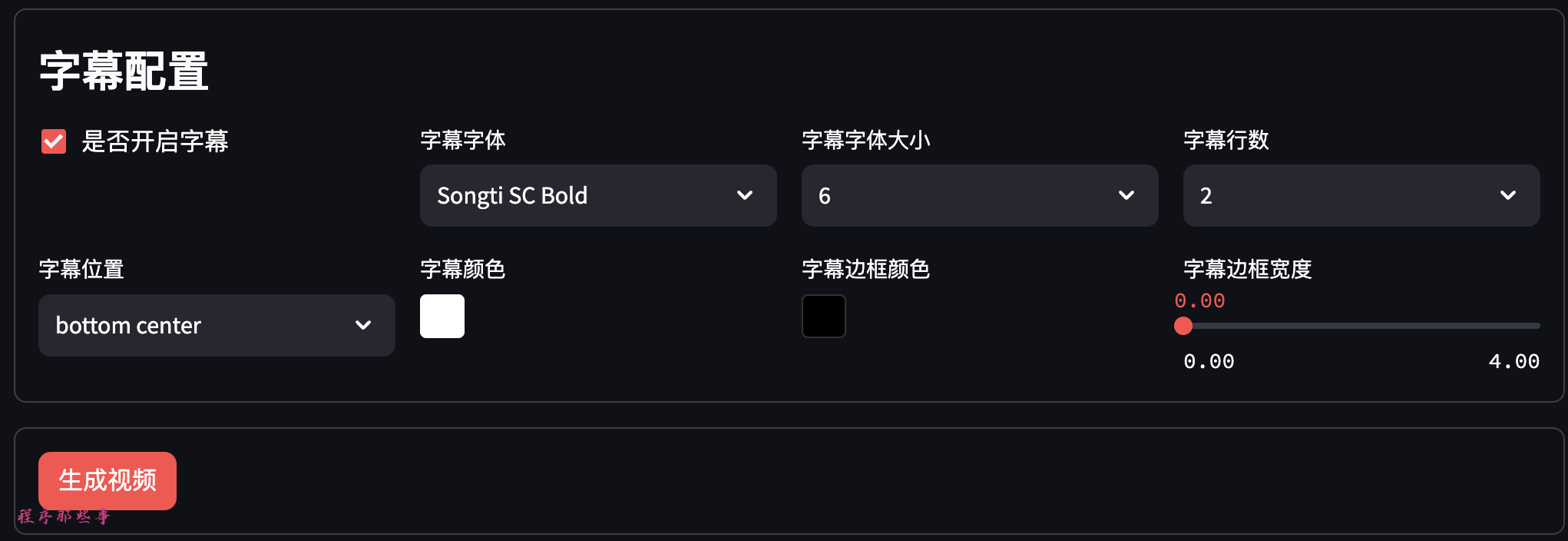
可以选择字幕位置,字幕颜色,字幕边框颜色和字幕边框宽度。
最后,就可以点击生成视频生成视频了。
会在页面上列出具体的步骤名称和进度。
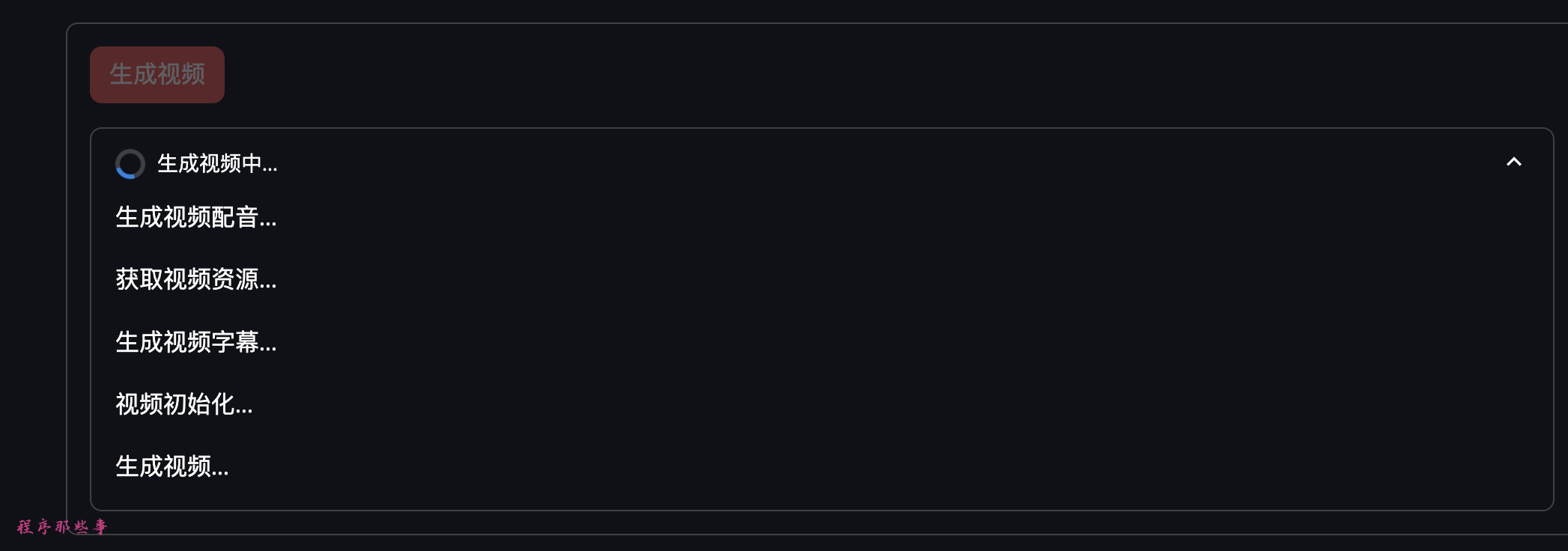
生成视频完成后,视频会显示在最下方,大家直接可以播放观看效果。

遇到问题的朋友,可以先看看这里的问题汇总,看看能不能解决问题先。
如果大家有什么问题或者想法,欢迎入群讨论。

{kind=link}