Extract main article, main image and meta data from URL.

View screenshots for more info.
npm install article-parser
Then:
const {
extract
} = require('article-parser');
const url = 'https://goo.gl/MV8Tkh';
extract(url).then((article) => {
console.log(article);
}).catch((err) => {
console.log(err);
});Since v4, article-parser will focus only on its main mission: extract main readable content from given webpages, such as blog posts or news entries. Although it is still able to get other kinds of content like YouTube movies, SoundCloud media, etc, they are just additions.
Extract data from specified url or full HTML page content. Return: a Promise
Here is how we can use article-parser:
import {
extract
} from 'article-parser';
const getArticle = async (url) => {
try {
const article = await extract(url);
return article;
} catch (err) {
console.trace(err);
}
};In comparison to v3, the article object structure has been changed too. Now it looks like below:
{
"url": URI String,
"title": String,
"description": String,
"image": URI String,
"author": String,
"content": HTML String,
"published": Date String,
"source": String, // original publisher
"links": Array, // list of alternative links
"ttr": Number, // time to read in second, 0 = unknown
}In addition, this lib provides some methods to customize default settings. Don't touch them unless you have reason to do that.
- setParserOptions(Object parserOptions)
- getParserOptions()
- setNodeFetchOptions(Object nodeFetchOptions)
- getNodeFetchOptions()
- setSanitizeHtmlOptions(Object sanitizeHtmlOptions)
- getSanitizeHtmlOptions()
Here are default properties/values:
{
wordsPerMinute: 300,
urlsCompareAlgorithm: 'levenshtein',
}Read string-comparison docs for more info about urlsCompareAlgorithm.
{
headers: {
'user-agent': 'article-parser/4.0.0',
},
timeout: 30000,
redirect: 'follow',
compress: true,
agent: false,
}Read node-fetch docs for more info.
{
allowedTags: [
'h1', 'h2', 'h3', 'h4', 'h5',
'u', 'b', 'i', 'em', 'strong',
'div', 'span', 'p', 'article', 'blockquote', 'section',
'pre', 'code',
'ul', 'ol', 'li', 'dd', 'dl',
'table', 'th', 'tr', 'td', 'thead', 'tbody', 'tfood',
'label',
'fieldset', 'legend',
'img', 'picture',
'br', 'p', 'hr',
'a',
],
allowedAttributes: {
a: ['href'],
img: ['src', 'alt'],
},
}Read sanitize-html docs for more info.
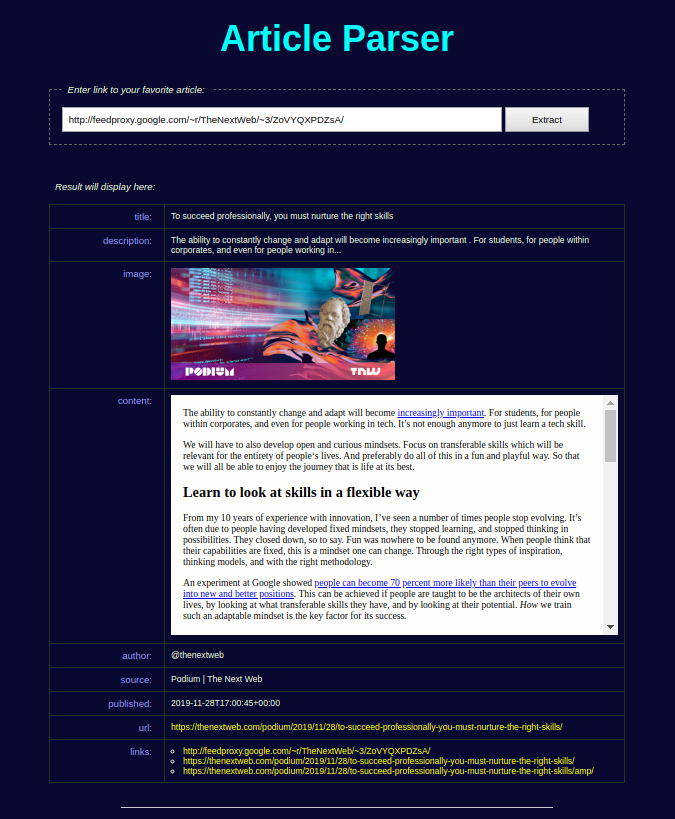
- Article Parser demo:
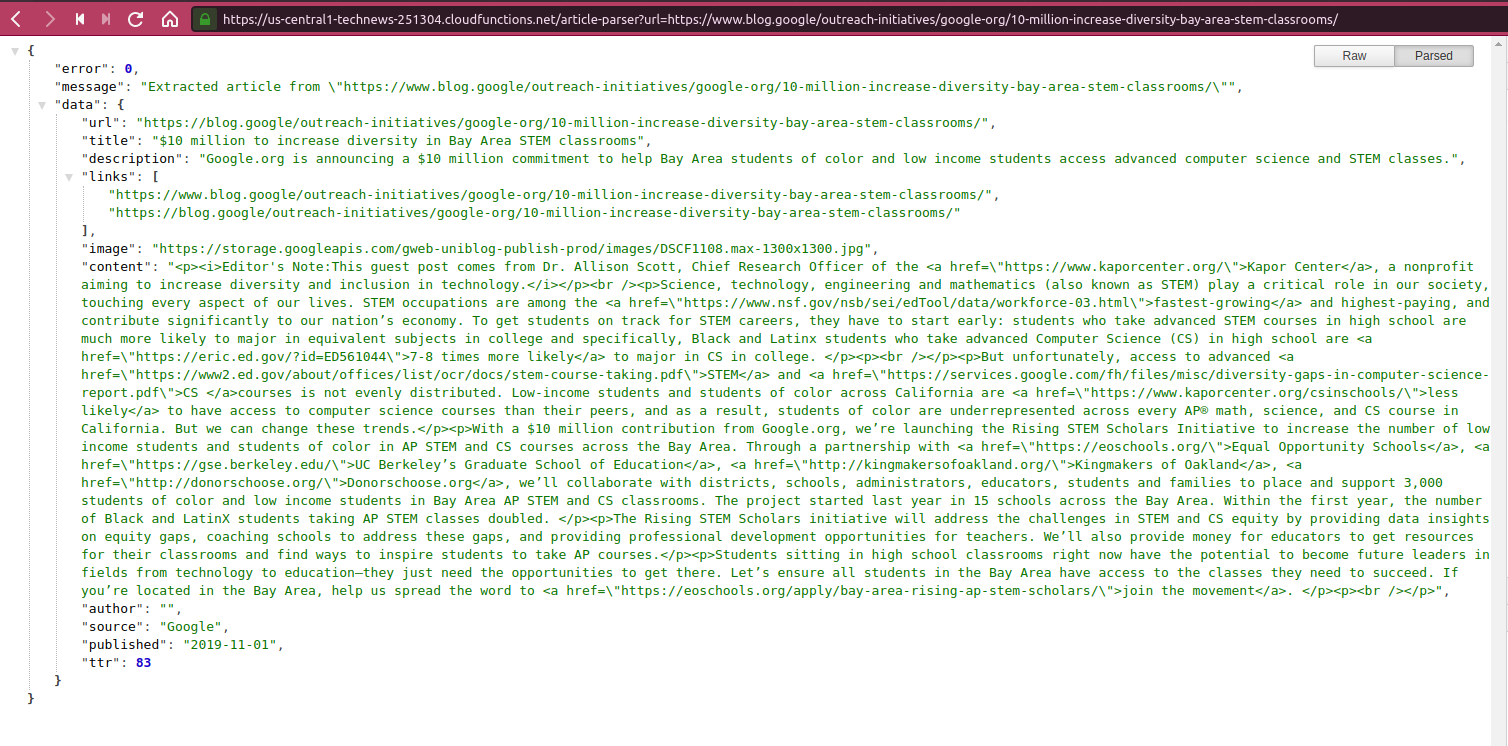
- Example FasS with Google Cloud Function
git clone https://github.com/ndaidong/article-parser.git
cd article-parser
npm install
npm testThe MIT License (MIT)