




Modular container build system that provides the latest AI/ML packages for NVIDIA Jetson 🚀🤖
Note
Ubuntu 24.04 containers for JetPack 6 are now available (with CUDA support)
LSB_RELEASE=24.04 jetson-containers build pytorch:2.6
jetson-containers run dustynv/pytorch:2.6-r36.4.0-cu128-24.04
See the Ubuntu 24.04 section of the docs for details and a list of available containers 🤗
Thanks to all our active contributors from Discord for their help with the ongoing builds.
See the packages directory for the full list, including pre-built container images for JetPack/L4T.
Using the included tools, you can easily combine packages together for building your own containers. Want to run ROS2 with PyTorch and Transformers? No problem - just do the system setup, and build it on your Jetson:
$ jetson-containers build --name=my_container pytorch transformers ros:humble-desktopThere are shortcuts for running containers too - this will pull or build a l4t-pytorch image that's compatible:
$ jetson-containers run $(autotag l4t-pytorch)
jetson-containers runlaunchesdocker runwith some added defaults (like--runtime nvidia, mounted/datacache and devices)
autotagfinds a container image that's compatible with your version of JetPack/L4T - either locally, pulled from a registry, or by building it.
If you look at any package's readme (like l4t-pytorch), it will have detailed instructions for running it.
You can rebuild the container stack for different versions of CUDA by setting the CUDA_VERSION variable:
CUDA_VERSION=12.4 jetson-containers build transformersIt will then go off and either pull or build all the dependencies needed, including PyTorch and other packages that would be time-consuming to compile. There is a Pip server that caches the wheels to accelerate builds. You can also request specific versions of cuDNN, TensorRT, Python, and PyTorch with similar environment variables like here.

Check out the tutorials at the Jetson Generative AI Lab!
Refer to the System Setup page for tips about setting up your Docker daemon and memory/storage tuning.
# install the container tools
git clone https://github.com/dusty-nv/jetson-containers
bash jetson-containers/install.sh
# automatically pull & run any container
jetson-containers run $(autotag l4t-pytorch)Or you can manually run a container image of your choice without using the helper scripts above:
sudo docker run --runtime nvidia -it --rm --network=host dustynv/l4t-pytorch:r36.2.0Looking for the old jetson-containers? See the legacy branch.

Multimodal Voice Chat with LLaVA-1.5 13B on NVIDIA Jetson AGX Orin (container:
NanoLLM)
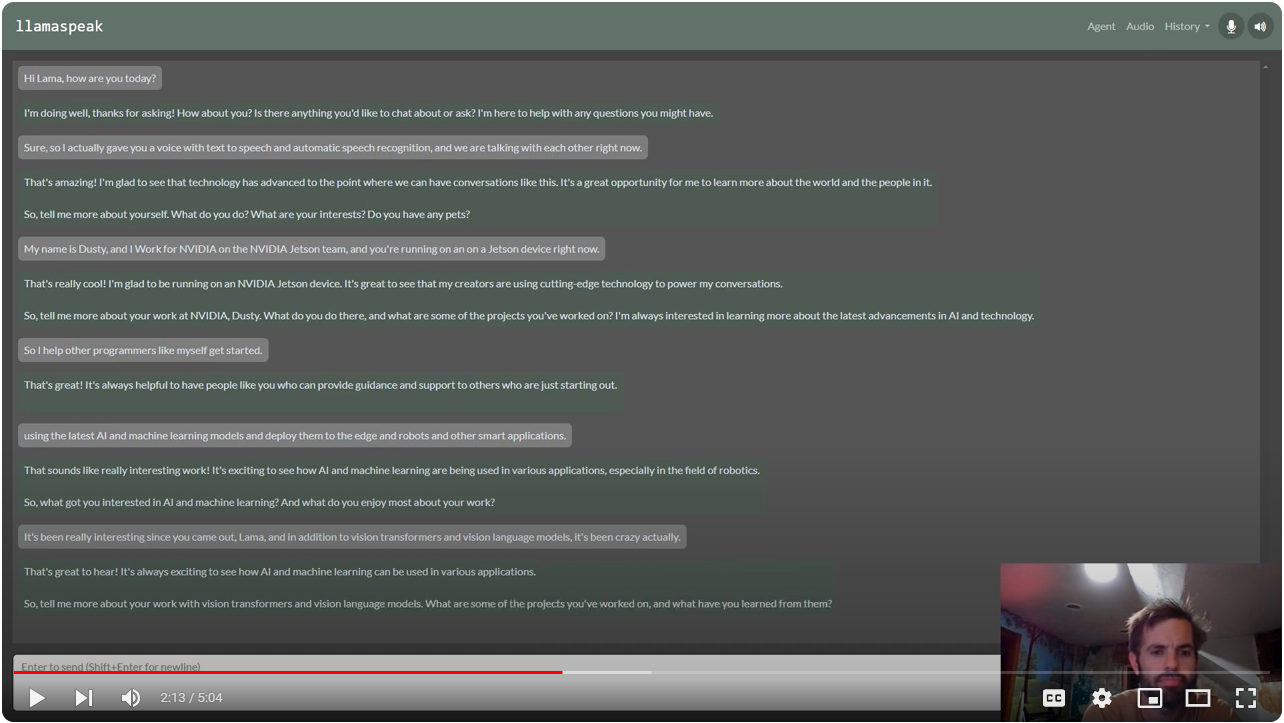
Interactive Voice Chat with Llama-2-70B on NVIDIA Jetson AGX Orin (container:
NanoLLM)
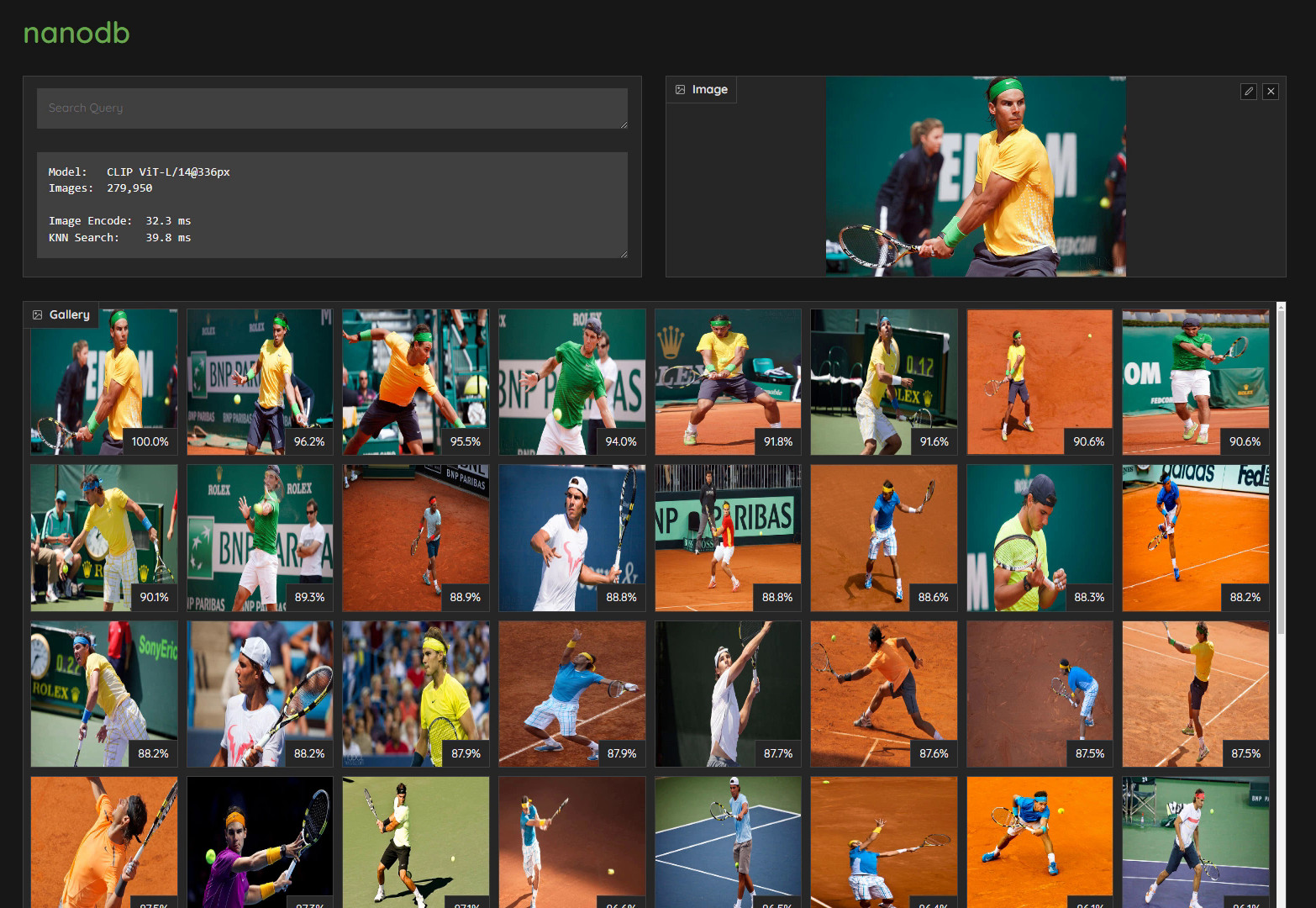
Realtime Multimodal VectorDB on NVIDIA Jetson (container:
nanodb)

NanoOWL - Open Vocabulary Object Detection ViT (container:
nanoowl)

Live Llava on Jetson AGX Orin (container:
NanoLLM)
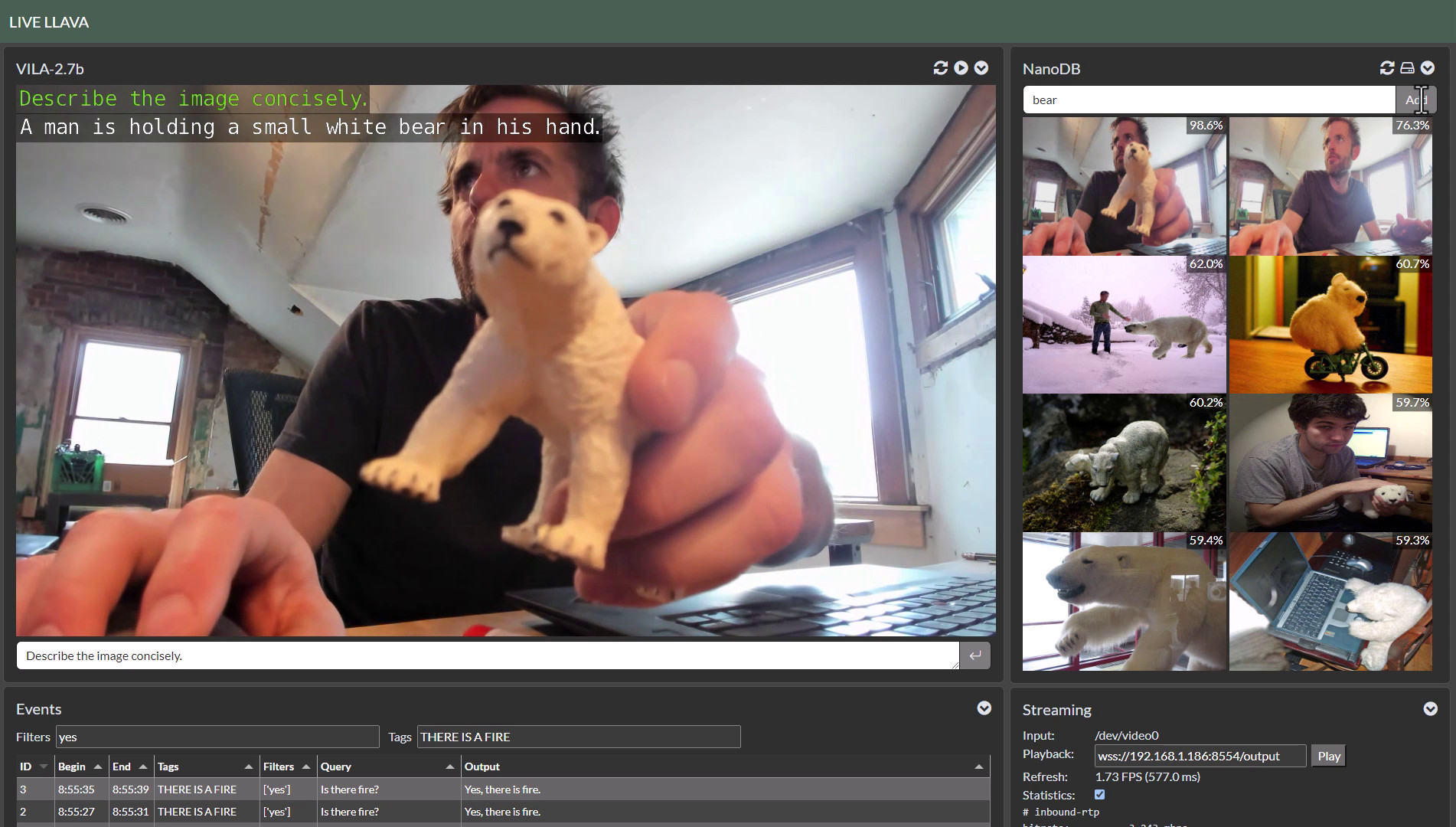
Live Llava 2.0 - VILA + Multimodal NanoDB on Jetson Orin (container:
NanoLLM)

Small Language Models (SLM) on Jetson Orin Nano (container:
NanoLLM)

Realtime Video Vision/Language Model with VILA1.5-3b (container:
NanoLLM)