Are you always using the same words in your scientific papers? This is a tool to run a text analysis on PDF files containing an English corpus.
It's a simple tool to extract keywords and Part-Of-Speech distributions from a given PDF. It employs a spaCy English model to perform tokenization and named-entities extraction. It's pretty much a word counter that employs standard NLP pre-processing, plus the NER part performed by spaCy. Additionally it produces a word cloud image.
This tool has been developed on Ubuntu 18.04 and macOS High Sierra, but
has never been seriously tested.
It requires Python3+ and virtualenv.
With these two installed, simply clone the repo and run source install.sh
The file requirements.txt contains all the needed python packages.
Ubuntu should come with Python3+ installed, so just give
source install.sh and Bob's your uncle.
Follow the following steps:
- Open a Terminal and run
xcode-select --install - log out and back in
- get Homebrew here: copy/paste the link they provide in a terminal.
At this stage, if you get an error that says
git: error: unable to locate xcodebuild, please make sure the path to the Xcode folder is set correctly!
git: error: You can set the path to the Xcode folder using /usr/bin/xcode-select -switch
follow what's been said here, and run the following in a terminal:
sudo xcode-select -switch /Library/Developer/CommandLineTools
Once Homebrew has been downloaded and installed you can install Python3 by:
brew install python
Once Python has been brewed
(a.k.a. Python installation finished successfully),
you should be able to run pip install virtualenv
and finally source install.sh.
Sorry, I have no clue. I don't even care.
Once the virtual environment has been created, and activated, simply run
python main.py --filepath /path/to/PDF_file
This will assume by default a maximum number of words to plot nmaxwords = 20.
To modify this setting, simply specify your preference by add the --nwords flag, e.g.
python main.py --filepath /path/to/PDF_file --nmaxwords 25
The tool is designed to run only on searchable PDF, namely PDF files in which the text can be selected and copied. That's it!
Here there are the sample results obtained by running on my CV, taken from here.
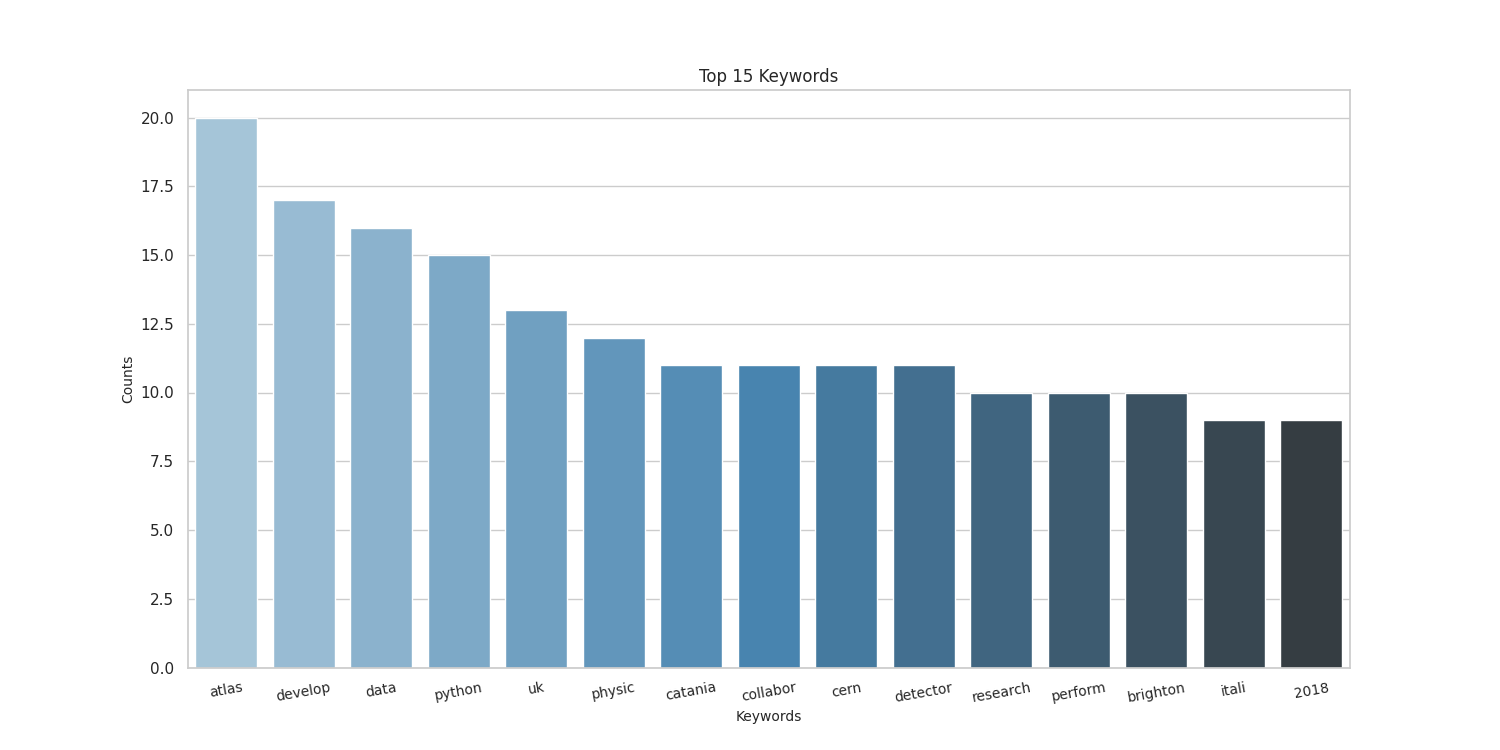
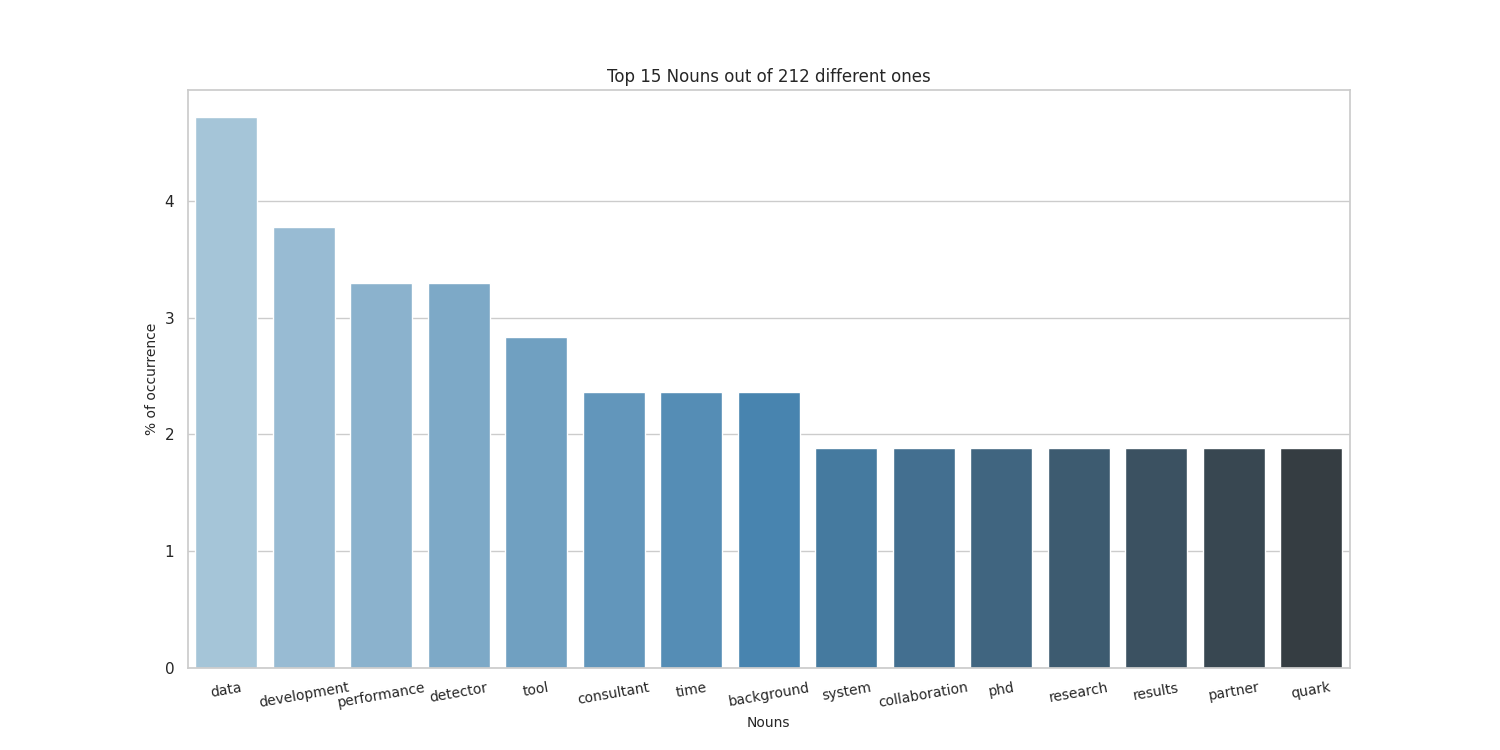
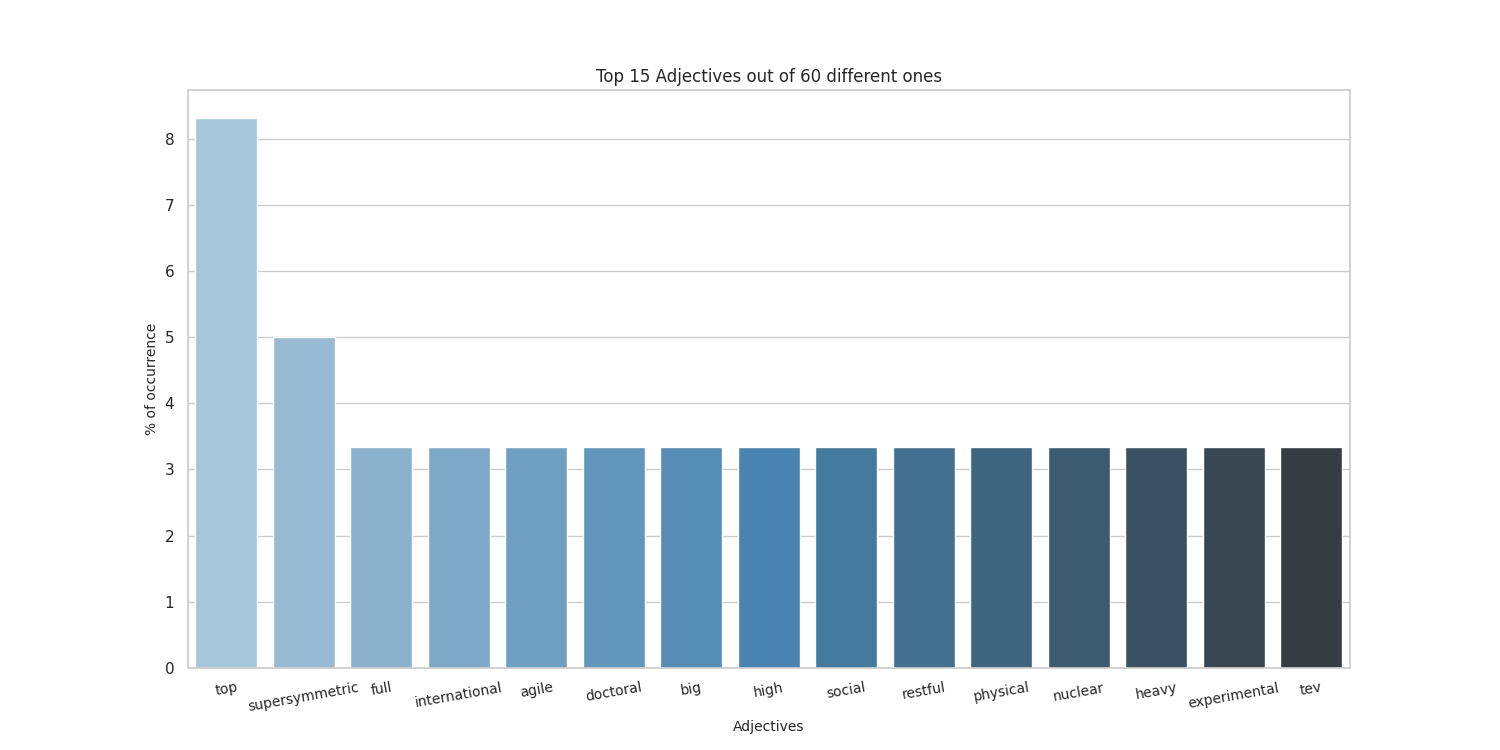
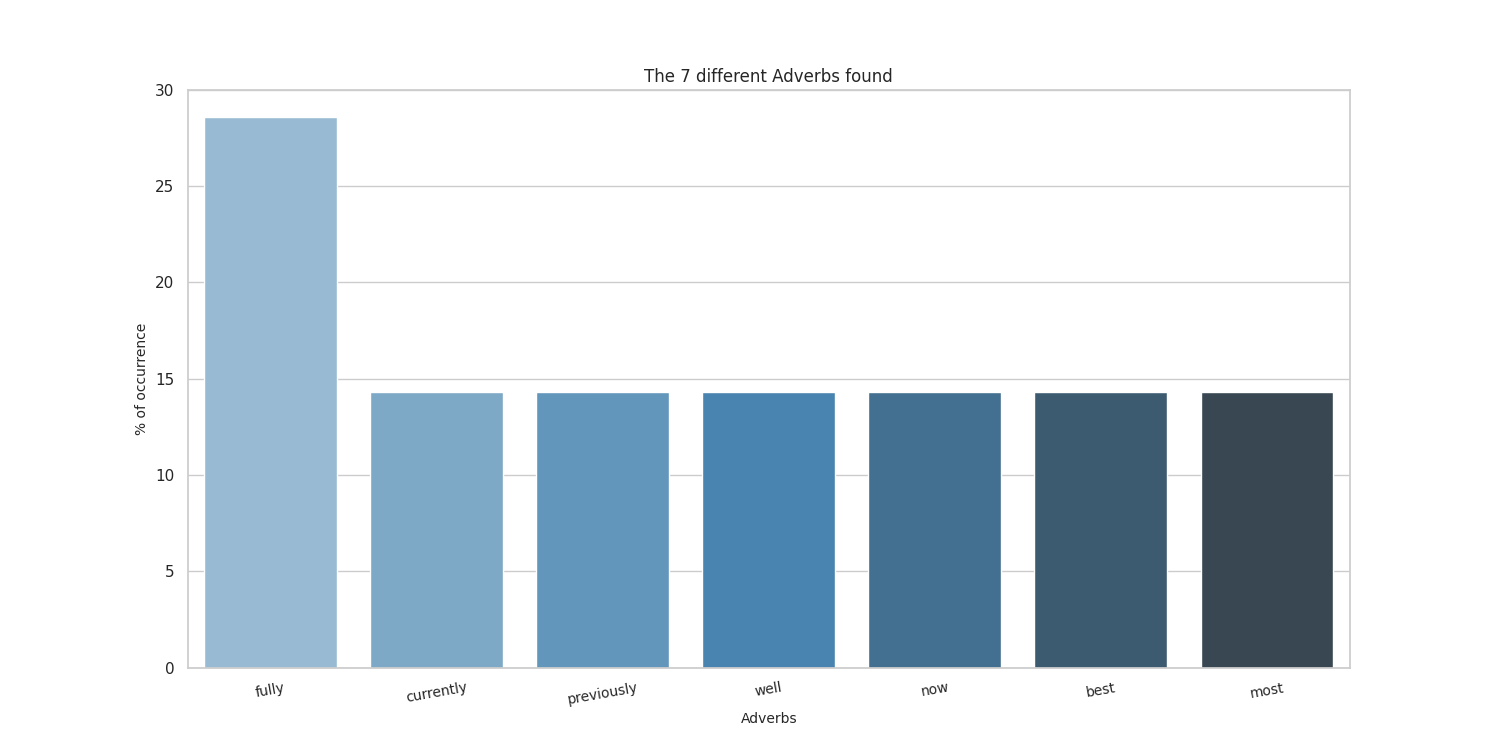
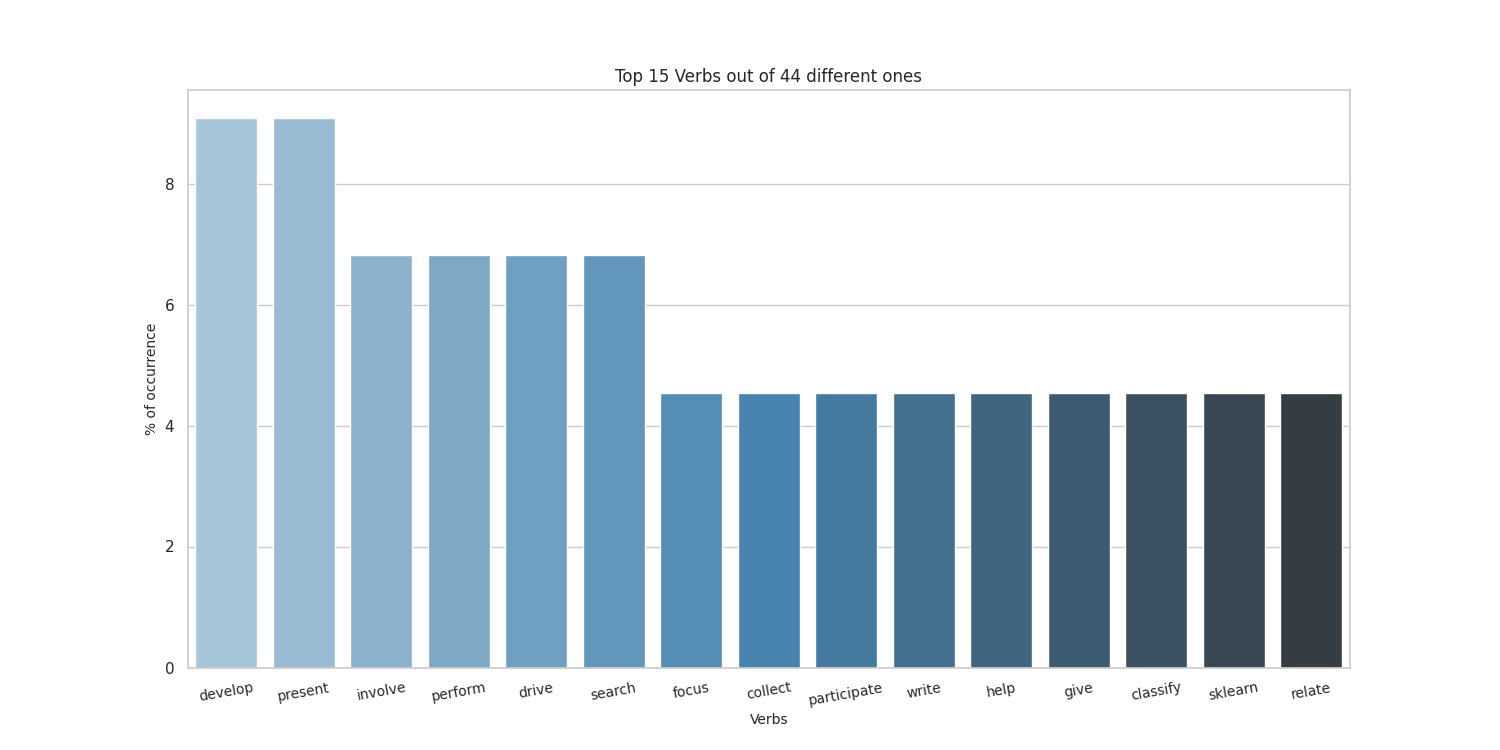
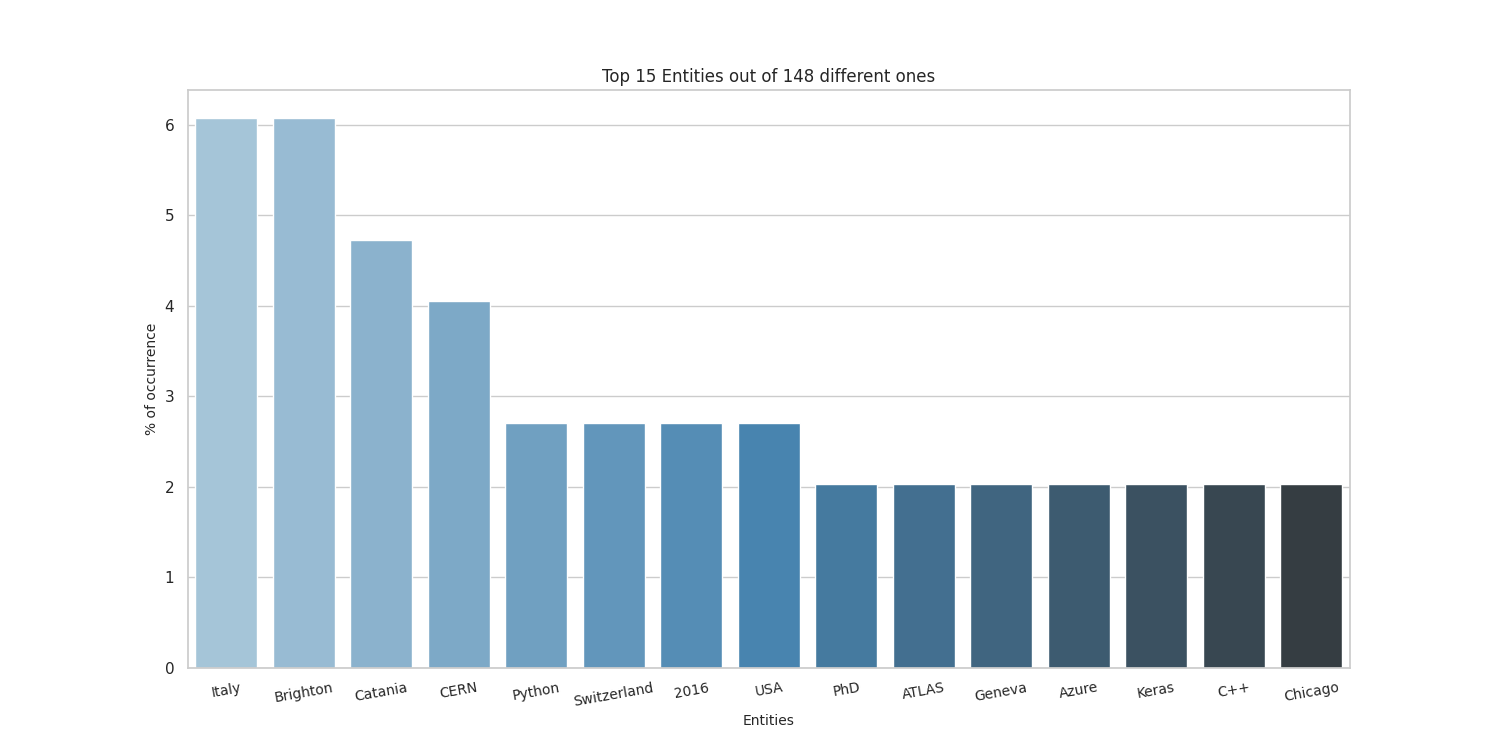
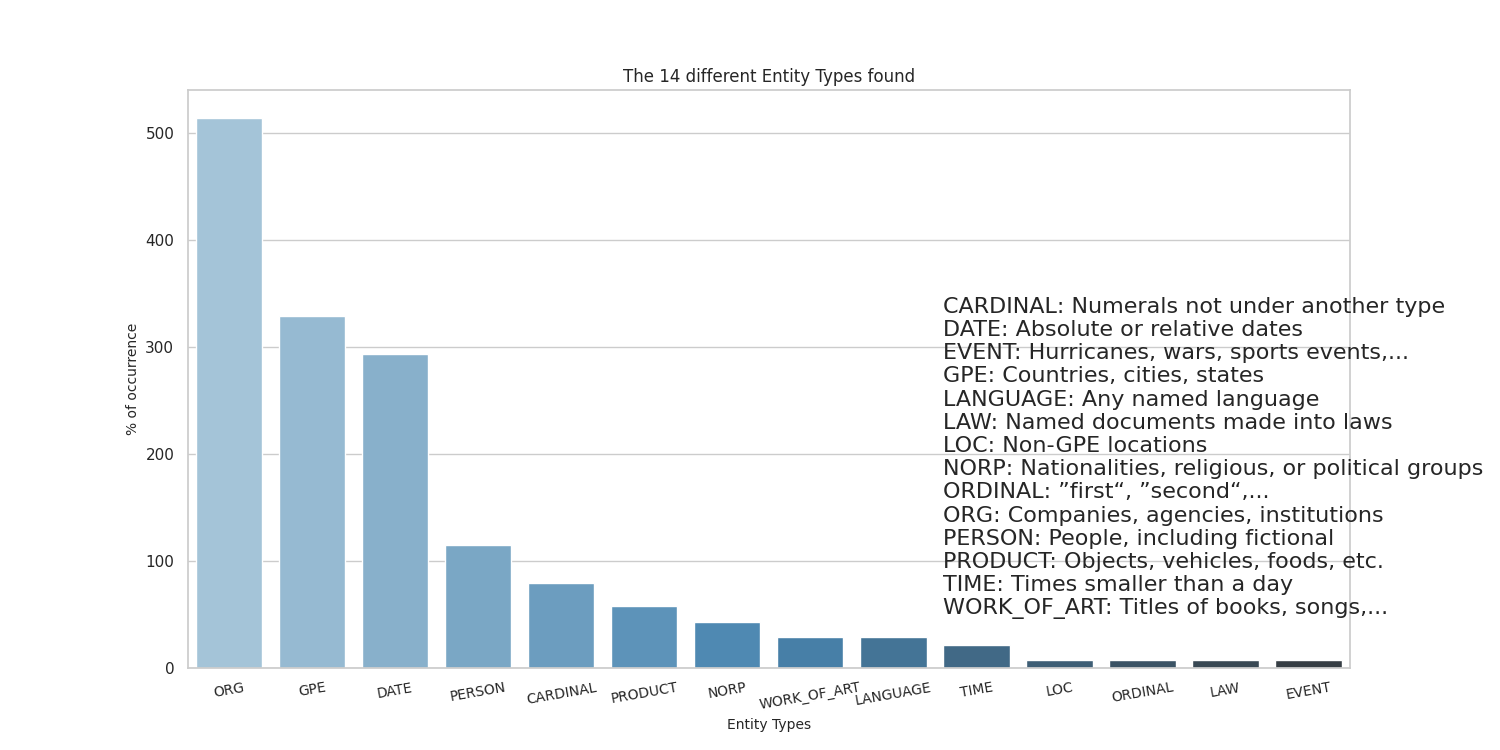

Thanks to the people at spaCy for the NE part, and to the guys who made word cloud for the awesome word-cloud images that can be produced.