BlindSight is a Python application to help the visually impaired in their daily lives.
Primarily, it has two parts,
- An Android Application A custom-camera app built using Java on Android Studio that is used to send a picture to a host address whenever the user taps on the screen or clicks the Volume-Up button.
- Python Scripts On the server, the Python script receives this picture and uses Artificial Intelligence to make sense of this picture and convert it into textual output, which can then be understood by the user as a voice output.
Input : User inputs a touch interaction by touching on the screen or clicking the volume button.
Processing : The camera captures whatever on the screen and sends it to the server using a host address.
Output : The application receives the output from the Server and converts it into voice output for the user to hear.
The Server Side is primarily broken up into two parts,
Input : The server receives the input at the host address in the form of a picture.
Processing : On the basis of the input, the server decides what operation needs to be performed. We have implemented three major operations,
- Object Detection
- Text Recognition
- Face Detection + Recognition
Once the image is passed through these algorithms, we will have an output in the form of textual data.
Output : The Output will be sent back to the user which initiated the connection.
Object Detection has been implemented using RetinaNet - Focal Loss (Object Detection).
RetinaNet is a One-Stage Detector. With Focal Loss and RetinaNet Using ResNet+FPN, it surpasses the Accuracy of two-stage detectors like Faster R-CNN.
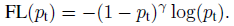

- (a) and (b) Backbone ResNet is used for deep feature extraction. Feature Pyramid Network (FPN) is used on top of ResNet for constructing a rich multi-scale feature pyramid from one single resolution input image. (Originally, FPN is a two-stage detector which has state-of-the-art results. Please read my review about FPN if interested.) FPN is multiscale, semantically strong at all scales, and fast to compute. There are some modest changes for the FPN here. A pyramid is generated from P3 to P7. Some major changes are: P2 is not used now due to computational reasons. (ii) P6 is computed by strided convolution instead of downsampling. (iii) P7 is included additionally to improve the accuracy of large object detection. Anchors The anchors have the areas of 32² to 512² on pyramid levels from P3 to P7 respectively. Three aspect ratios {1:2, 1:1, 2:1} are used. For denser scale coverage, anchors of sizes {2⁰, 2^(1/3), 2^(2/3)} are added at each pyramid level. In total, 9 anchors per level. Across levels, scale is covered from 32 to 813 pixels. Each anchor, there is a length K one-hot vector of classification targets (K: number of classes), and a 4-vector of box regression targets. Anchors are assigned to ground-truth object boxes using IoU threshold of 0.5 and to background if IoU is in [0,0.4). Each anchor is assigned at most one object box, and set the corresponding class entry to one and all other entries to 0 in that K one-hot vector. If anchor is unassigned if IoU is in [0.4,0.5) and ignored during training. Box regression is computed as the offset between anchor and assigned object box, or omitted if there is no assignment.
- (c) Classification Subnet This classification subnet predicts the probability of object presence at each spatial position for each of the A anchors and K object classes. The subnet is a FCN which applies four 3×3 conv layers, each with C filters and each followed by ReLU activations, followed by a 3×3 conv layer with KA filters. (K classes, A=9 anchors, and C = 256 filters)
- (d) Box Regression Subnet This subnet is a FCN to each pyramid level for the purpose of regressing the offset from each anchor box to a nearby ground-truth object, if one exists. It is identical to the classification subnet except that it terminates in 4A linear outputs per spatial location. It is a class-agnostic bounding box regressor which uses fewer parameters, which is found to be equally effective.
Optical Character Recognition involves the detection of text content on images and translation of the images to encoded text that the computer can easily understand. We used Python-Tesseract, which is a wrapper for Google's Tesseract-OCR Engine. An open-source algorithm, it uses a step-by-step approach for text recognition,
- Line Finding
- Baseline Fitting
- Fixed Pitch Detection and Chopping
- Proportional Word Finding
- Word Finding
- Chopping Joined Characters
- Associating Broken Characters
We used two libraries for face detection and recognition.
- dlib
- face_recognition
The dlib library, maintained by Davis King, contains our implementation of “deep metric learning” which is used to construct our face embeddings used for the actual recognition process.
The face_recognition library, created by Adam Geitgey, wraps around dlib’s facial recognition functionality, making it easier to work with.
- Python 3.6.8 |Anaconda custom (64-bit)
- GCC 4.2.1 Compatible Clang 4.0.1
We used Mac OS X to run our project. You must have conda installed in order to start the installation. To know more about installing Conda, visit this link.
Once conda is installed, run the following code,
conda create -n retinanet python=3.6 anaconda
It will install Python3.6 and all the required packages for retinanet. Next, activate the virtual environment you just created.
source activate retinanet
The following imported libraries were used in this project. You can use pip to manually install each library on your PC,
import re
from bs4 import BeautifulSoup
import requests
from sys import byteorder
from array import array
from struct import pack
import pyaudio
import wave
from gtts import gTTS
from pygame import mixer # Load the required library
import threading
from imageai.Detection import ObjectDetection
import os
import collections
from PIL import Image
import pytesseract
import argparse
import cv2
import os
from __main__ import *
import face_recognition
import argparse
import pickle
import cv2
import sys
from gtts import gTTS
import urllib.request
import requests
import base64
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
import base64
import requests
import cv2
import numpy as np
from keras.models import load_model
import sys
import warnings
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
from pydub import AudioSegment
from pydub.playback import play
from imutils import paths
import face_recognition
import argparse
import pickle
import cv2
import os
import shutil
Once installed, you need to download the two models we used,
- RetinaNet for ObjectDetection - Place it inside the BlindSight/ folder as 'resnet50_coco_best_v2.0.1.h5' | Download Now
- Emotion Recognition - Place it inside the face-recognition-opencv/ folder as 'model_5-49-0.62.hdf5'
Once stored, you can run BlindSight.py file to start the code. Face Detection requires a model (needs stored faces) - you will need to use the BlindSight.py's 'save' command to record and save faces.
After that, use encode_faces.py to create a model and place it in the face-recognition-opencv/ folder as 'encodings.pickle' using Python's pickle library.
Now, your code is capable of recognizing the stored faces. You can store more faces for better recognition.
Commands Implemented
- Object Recognition
- Face Recognition + Emotions Detection
- Text Recognition
- Recording Notes (Voice to Text and vice versa)
- Reading Headlines