MSA를 기반으로 한 고성능 티켓팅 플랫폼을 개발합니다.
공연, 콘서트 등의 티켓을 구매할 수 있는 온라인 플랫폼으로, 사용자에게 빠르고 안정적인 티켓팅 서비스를 제공하는 것을 목표로 합니다.
- 공연, 콘서트 등의 티켓을 구매할 수 있는 온라인 플랫폼으로, 사용자에게 빠르고 안정적인 티켓팅 서비스를 제공합니다.
- 저희 프로젝트는 MVP 단계별 성능 개선을 목표로, Caching, DB 최적화, Scale Out 등을 통해 부하 테스트로 성능 개선을 눈으로 확인하여 대용량 트래픽을 효율적으로 처리할 수 있는 고성능 시스템을 구축하는 것을 목표로 합니다.

- 1차 MVP(1, 2주차) - 프로젝트 MSA 구성, API 개발, 1차 부하테스트 Gatling, Prometheus, Grafana
- 2차 MVP(3주차) - 1차 MVP 부하테스트 개선, 2차 부하테스트, 병목 지점 파악, Redis 분산 락
- 3차 MVP(4주차) - Kafka 대기열시스템 적용, Redis 캐싱, Kafka 비동기 처리, 서비스 배포 CICD, 2차 MVP 성능 개선, 3차 부하테스트
 |
 |
 |
 |
|---|---|---|---|
| 박주창 | 이상우 | 김용재 | 김휘수 |
- 클라이언트 요청 처리:
- 클라이언트의 요청이 JWT 검증을 마친 후, 카프카 필터로 전달됩니다.
- 요청 모니터링 및 처리:
- 카프카 필터는 요청 수를 모니터링합니다.
- 요청 수가 설정해 놓은 임계값 이하인 경우, 요청은 각 서비스로 전달됩니다.
- 요청 수가 임계값 이상으로 증가하면 과부하 상태가 활성화되고, 프로듀서에 의해 클라이언트에게 대기 순번표(오프셋)가 발급됩니다.
- 요청 정보는 메시지 큐에 저장됩니다.
- 메시지 소비 및 재요청:
- 컨슈머가 오프셋 순서에 맞게 메시지를 소비할 때, 메시지의 값에서 요청 정보를 읽습니다.
- 이때, 해당 요청이 재요청임을 알리기 위해 헤더에 토큰을 추가합니다.
- 서비스 전달:
- 재요청은 카프카 필터를 통과하지 않고 바로 각 서비스로 전달됩니다.
- 요청이 각 서비스로 전달 시 모니터링에서 요청 수가 감소하게 됩니다.
- 과부하 상태 비활성화:
- 요청 수가 임계값 이하로 내려가면 과부하 상태가 비활성화됩니다.


Backend : Java, Spring Boot, Spring Cloud, SpringDataJPA, QueryDSL, Docker
Database : PostgreSQL, Redis
Messaging : Kafka
Monitoring : Grafana Prometheus Zipkin
Testing : Gatling
Infra : Github Actions, AWS (ECR, EC2)
Tools : GitHub Postman Notion
기술 상세
- 서비스 간의 동적 등록을 통해, 서비스의 위치를 자동으로 관리하고 클라이언트가 서비스에 쉽게 접근할 수 있도록 합니다.
- 마이크로서비스 구조에서 서비스의 수가 증가함에 따라, 수동으로 서비스를 관리하는 것이 비효율적이므로, Eureka를 통해 자동화된 서비스 등록을 구현합니다.
- 로그인 후 세션 관리: 사용자가 로그인하면 서버는 JWT를 생성하여 클라이언트에게 반환합니다. 이후 클라이언트는 이 토큰을 사용하여 서버에 요청할 때 인증 정보를 포함시킵니다.
- RESTful API에서의 인증: 클라이언트가 서버에 API 요청을 보낼 때 JWT를 포함시킴으로써, 각 요청에 대해 사용자의 인증을 확인할 수 있습니다. 이는 모바일 앱, 웹 클라이언트, IoT 기기 등 다양한 클라이언트에서 사용됩니다.
- 사용자 역할 기반 접근 제어: JWT에 사용자 역할이나 권한 정보를 포함시킬 수 있어, 요청을 처리하는 서비스에서 이를 기반으로 접근 제어를 수행할 수 있습니다.
- 서비스 간 인증: 마이크로서비스 환경에서 각 서비스가 서로 통신할 때 JWT를 사용하여 인증 정보를 공유할 수 있습니다. 각 서비스는 JWT를 통해 사용자의 권한을 확인하고 필요한 리소스에 접근할 수 있습니다.
- 인메모리 데이터 구조 저장소로,캐싱 처리를 통해 데이터 조회 성능을 개선하고, 데이터베이스에 대한 부하를 줄입니다.
- 특히 높은 성능과 낮은 지연 시간을 제공하여 빈번하게 조회되는 데이터를 메모리에 저장하기 때문에 응답 속도를 극대화할 수 있습니다.
- 비동기 처리:
- 비동기 처리는 특정 작업이 완료될 때까지 기다리지 않고 다른 작업을 동시에 수행할 수 있도록 하는 방식으로, 시스템의 응답성과 처리 속도를 크게 개선할 수 있습니다.
- 주로 반환되는 데이터의 중요성이 떨어지거나(요청의 결과 성공 유무 상태를 모르는 상태로 응답을 보내주므로) 요청자가 빠른 응답을 원하는 경우에 적용이 유의미합니다.
- Producer가 메시지를 Kafka로 보내고, Consumer가 이 메시지를 처리하는 방식으로 동작하므로 데이터를 즉시 처리하지 않고 필요할 때 Consumer가 데이터를 가져가서 처리하는 비동기 처리가 가능합니다.
- 대기열 구현:
- 대규모 데이터 스트리밍을 위해 설계되어 다량의 요청을 안정적으로 처리하는데 유리합니다.
- 메시지를 디스크에 지속적으로 저장하여 데이터의 내구성을 보장합니다. 장애가 발생해도 메시지를 잃지 않도록 설계되어 있어, 데이터 복원이 가능합니다.
- 각 파티션 내에서 offset을 통해 메시지 순서를 보장합니다. 이를 통해 순차적으로 발생한 이벤트를 처리해야 하는 경우에 유리합니다.
- Kafka UI를 통해 강력한 모니터링 기능을 제공하여, 시스템의 성능과 상태를 실시간으로 확인할 수 있습니다.
- 시계열 데이터를 수집하고 저장하는 오픈소스 모니터링 시스템으로, 주로 애플리케이션의 성능 지표를 추적하는 데 사용됩니다.
- Grafana와 같은 시각화 대시보드와 결합할 수 있고 특히 MSA환경에서 여러 서비스의 데이터를 한 번에 가져오고 비교할 수 있습니다.
- 데이터 시각화 도구로, Prometheus를 비롯한 다양한 데이터 소스에서 수집된 메트릭을 대시보드로 시각화할 수 있습니다.
- 여러 데이터 소스와 호환성이 좋으며 다양한 시각화 옵션을 커스터마이징 가능하게 제공하고, 특정 메트릭이 임계값을 초과하거나 조건이 충족될 때 알림을 통해 신속한 대응이 가능합니다.
- Prometheus와 결합해 CPU, MEMORY의 실시간 사용량을 파악할 수 있습니다.
- Scala 또는 Java 언어 기반의 스크립트 작성을 통해 성능 테스트를 수행하며, 코드로 시나리오를 정의하기 때문에 복잡한 시나리오를 구현할 수 있습니다.
- 비동기식 엔진을 사용해 메모리와 CPU를 효율적으로 사용하기 때문에 다른 도구들에 비해 동일한 하드웨어로 더 많은 유저 부하를 발생시킬 수 있습니다.
- 테스트 완료 후 자동으로 시각화된 HTML 리포트를 생성해주며, 리포트의 품질이 높아 성능 분석에 용이합니다.
- 사용자 요청이 여러 서비스로 전달되는 과정을 추적하여 각 요청이 어떤 서비스에서 처리되었는지, 각 서비스의 응답 시간이 얼마나 걸렸는지를 기록하여 전체 요청 흐름을 이해할 수 있습니다.
- 각 서비스의 응답 시간을 기록하여 성능 병목 현상을 식별하고, 어떤 서비스가 느린지, 전체 요청이 얼마나 지연되는지를 쉽게 파악할 수 있습니다.
- 웹 기반 UI를 제공하여 서비스 호출을 시각적으로 분석할 수 있습니다. 이를 통해 복잡한 트랜잭션 흐름을 쉽게 이해하고 분석할 수 있습니다.
- 데이터를 다룰 때 Table에 종속되지 않고 객체에 특화된 쿼리 언어로, 쿼리를 자바 코드로 작성하여 JPA로 해결하지 못하는 복잡한 문제를 해결할 수 있습니다.
- 자바 코드로 작성하기 때문에 오류를 컴파일 시점에서 잡아낼 수 있습니다.
대기열 시스템 구현 방법
- 문제점 :
- 티켓팅 시간에 맞춰 많은 요청이 들어올 경우 서버가 부하를 이기지 못하고 장애가 발생
- 해결 방안 :
- 요청들에 대기열을 부여하여 하나씩 처리할 수 있도록 대기열 시스템을 도입
- Kafka or Redis 기술 적용 방법
- 해결책 비교 :
- Kafka :
- 장점 : 높은 처리량, 확장성, 데이터 내구성, 신뢰성
- 단점 : 지연 시간, Learning Curves
- Redis :
- 장점 : 빠른 속도, 간단한 사용법, 실시간 처리
- 단점 : 데이터 손실에 위험, 순서 보장 부족
- 결론 :
- Kafka가 대규모 트래픽 처리를 위한 대기열 시스템의 핵심 요구사항인 확장성, 데이터 내구성, 메시지 순서 보장에서 Redis보다 더 효과적이라 판단하여 Kafka를 선택
부하 테스트 도구 선택
- 문제점 :
- 대규모 트래픽 발생 시 안정적인 티켓팅 처리를 위한 부하 테스트 도구의 선택이 필요
- 해결책 비교 :
- Apache JMeter :
- 장점 : GUI 기반으로 사용이 간편하여 비전문가도 쉽게 설정이 가능
- 단점 : 대규모 테스트 시 메모리 및 CPU 사용량이 높아 분산 구성이 필요
- Gatling :
- 장점 : 비동기식 엔진을 통해 자원을 효율적으로 사용, 확장성, 리소스 효율성이 높음
- 단점 : 코드 기반 도구로 프로그래밍 지식이 필요, Learning Curves
- nGrinder :
- 장점 : 웹 기반 UI로 쉽게 성능 테스트를 설정하고 관리가 가능, 분산 테스트를 지원
- 단점 : 설정 과정이 복잡하고, 성능 상의 제한이 있을 수 있음
- 결론 :
- Gatling은 대규모 부하 테스트에 최적화되어 있으며, 성능이 중요하다 생각하여 선택
Gatling 부하 테스트시 동시성 문제 발생
- 문제 상황 :
- 동일한 POST 요청을 1000건 이상 발생 시 1건이 아닌 10건이 성공으로 나오게되고, 이후의 요청들은 exception에서 반환 타입의 불일치(예상 반환 타입은 Booking이지만 10건의 List로 반환)로 500 에러를 발생
- 1000번의 요청이 들어갔을 때 10번의 요청에 대해서는 동시성 문제로 DB에 저장되는 모습


- 해결 방안 1 : @Transactional(isolation = Isolation.SERIALIZABLE)
- Transactional을 가장 높은 격리 수준으로 지정하여 처음 요청이 완료되기 전까지 두 번째 트랜잭션은 해당 리소스를 사용할 수 없도록 한다. 동시성 문제는 해결할 수 있지만 성능과의 트레이드 오프가 존재한다.
- 1000건의 요청 → 98.30% 성공
- 5000건의 요청 → 16.26% 성공


- 해결 방안 2 : Redisson 분산 락 적용
- Redisson의 Lock 객체를 생성하여 요청 스레드가 이미 Lock을 획득한 시점이라면 Lock을 획득하지 못한 스레드들은 Redisson 큐에서 대기하도록 하여 동시성 문제를 해결
- 1000건의 요청 → 100% 성공
- 5000건의 요청 → 92.62% 성공


Redis Caching Page 객체 직렬화 문제
조회 api에 Redis Caching처리하여 성능 개선을 시도하던 중 Page 객체를 Redis로 반환할 시 직렬화 문제로 조회되지 않는 현상을 발견.
처음 요청은 DB에서 데이터를 제대로 가져오지만바로 두 번째 요청에서 500 에러를 발생
직렬화/역직렬화 문제:
Redis에 저장될 때 객체가 직렬화되고 다시 읽을 때 역직렬화되는데, 만약 직렬화 방식이 잘못 설정되어 있거나 Page 객체가 올바르게 직렬화되지 않는 경우, 캐시에서 가져올 때 LinkedHashMap으로 변환될 수 있다.
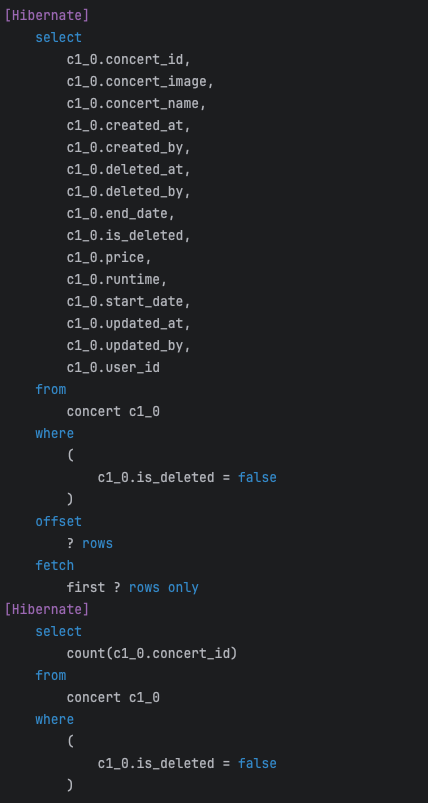
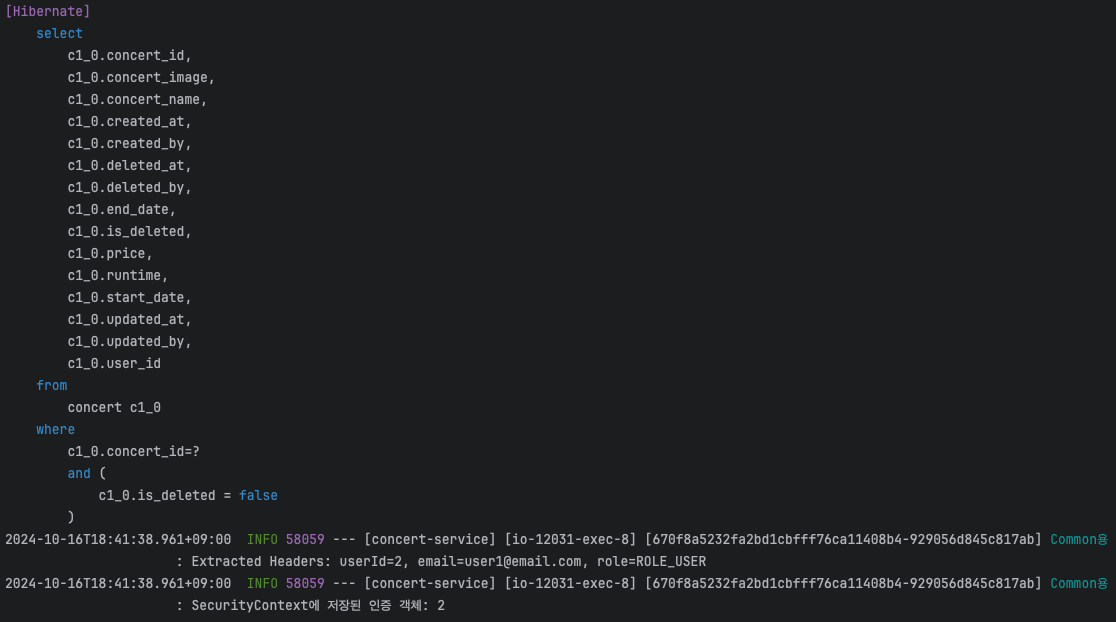
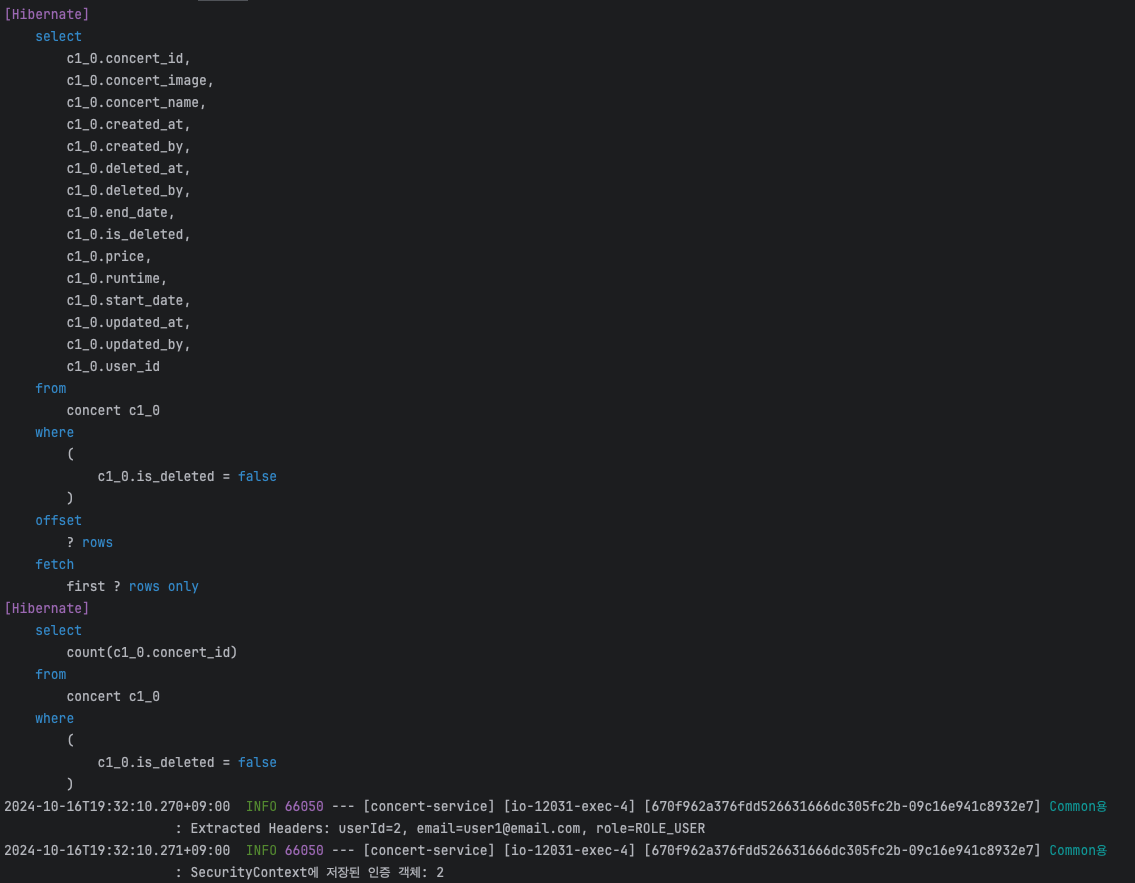
참고로 단일 조회의 경우 두 번째 요청은 Cache에서 조회해오기 때문에 쿼리문이 생략되는걸 확인할 수 있다.
- Page 데이터를 캐싱하기 위한 객체. Page를 리턴하는 부분을 감싸서 사용한다.
@JsonIgnoreProperties(ignoreUnknown = true, value = {"pageable"}) public class RestPage<T> extends PageImpl<T> { @JsonCreator(mode = JsonCreator.Mode.PROPERTIES) public RestPage(@JsonProperty("content") List<T> content, @JsonProperty("number") int page, @JsonProperty("size") int size, @JsonProperty("totalElements") long total) { super(content, PageRequest.of(page, size), total); } public RestPage(Page<T> page) { super(page.getContent(), page.getPageable(), page.getTotalElements()); } }하지만
팀이 사용하는 dto는 record 형식인데 record는 제네릭을 지원하지 않아서 에러가 발생했다.
-> record 형식을 class로 변경
처음 요청은 쿼리문이 날아가고 두 번째는 Redis에서 조회하는데 성공


- 공연 리스트 조회 API
- 10000건(100명 100건) 테스트 진행
- TPS : 161.3 -> 500 으로 개선
- 캐싱 처리 이전(페이징 처리)
- TPS = 161.3


- 캐싱 처리 이후(Redis 적용)
- TPS = 500




- 예매 취소 API
- 평균 3초의 응답 시간을 가지므로 Kafka를 이용하여 비동기 처리를 진행
- 1000건(100명 10건) 테스트 진행
- 비동기 처리 적용 전


- 비동기 처리 적용 후




- 좌석 조회 API
- 10000건(1000명 10건) 테스트 진행
- TPS = 65.8 -> 88.5 (22.7 개선)
- Scale Out 이전(단일 서버) : TPS = 65.8


- Scale Out 적용(Order, Concert) : TPS = 88.5




- 예매 생성 API
- 10000건(100명 100건) 테스트 진행
- TPS = 55.2 -> 400 (344.8 개선)
- 대기열 시스템 적용 전
- TPS = 55.2


- 대기열 시스템 적용 후
- TPS = 400




- 인프라 설계도 & 시스템 구조도 - Wiki 보기
- 컨벤션 - Wiki 보기
- API 명세서 - PostMan API 명세서
- 테이블 명세서 - Wiki 보기
- ERD 명세서 - Wiki 보기