针对nastools一些功能进行更新优化,自用
-
修复bug:
(1)识别词替换中不能使用正则匹配(通过识别标记开启正则匹配)-已完成
实现效果:
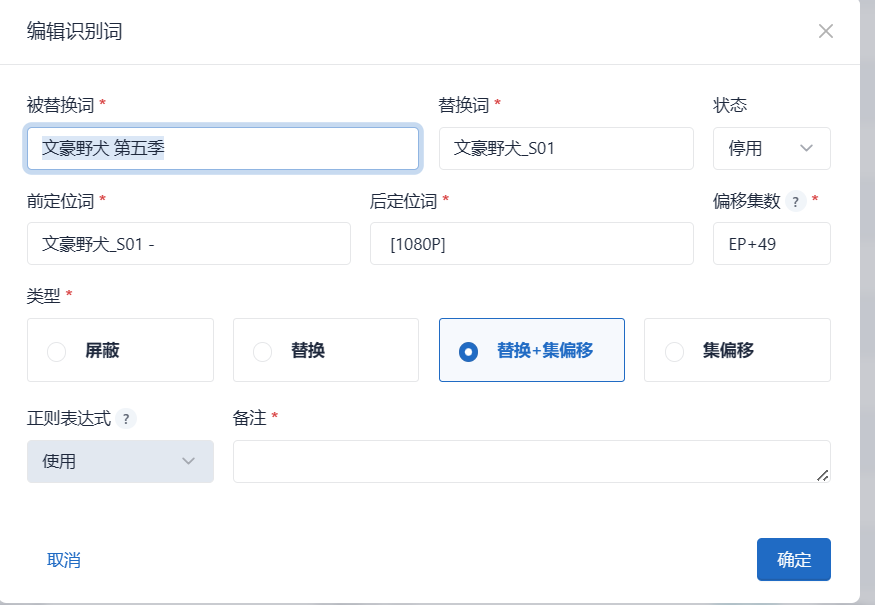
原文件名:
[ANi] 文豪野犬 第五季 - 01 [1080P][Baha][WEB-DL][AAC AVC][CHT].mp4新文件名:
[ANi] 文豪野犬_S01 - 50 [1080P][Baha][WEB-DL][AAC AVC][CHT].mp4
(2)解决了豆瓣api中不能同步收藏数据问题
-
目前进度:
(1)已优化普通视频文件识别、转移目录的逻辑,解决文件名中因文件md5编码会识别错误集数的问题,适应90%视频的识别,其余10%需要自添加自定义识别词来增强识别,其中自定义识别词中的“[]、【】、()、()”等符号需要加
\进行转义,也可以直接使用名称,不加符号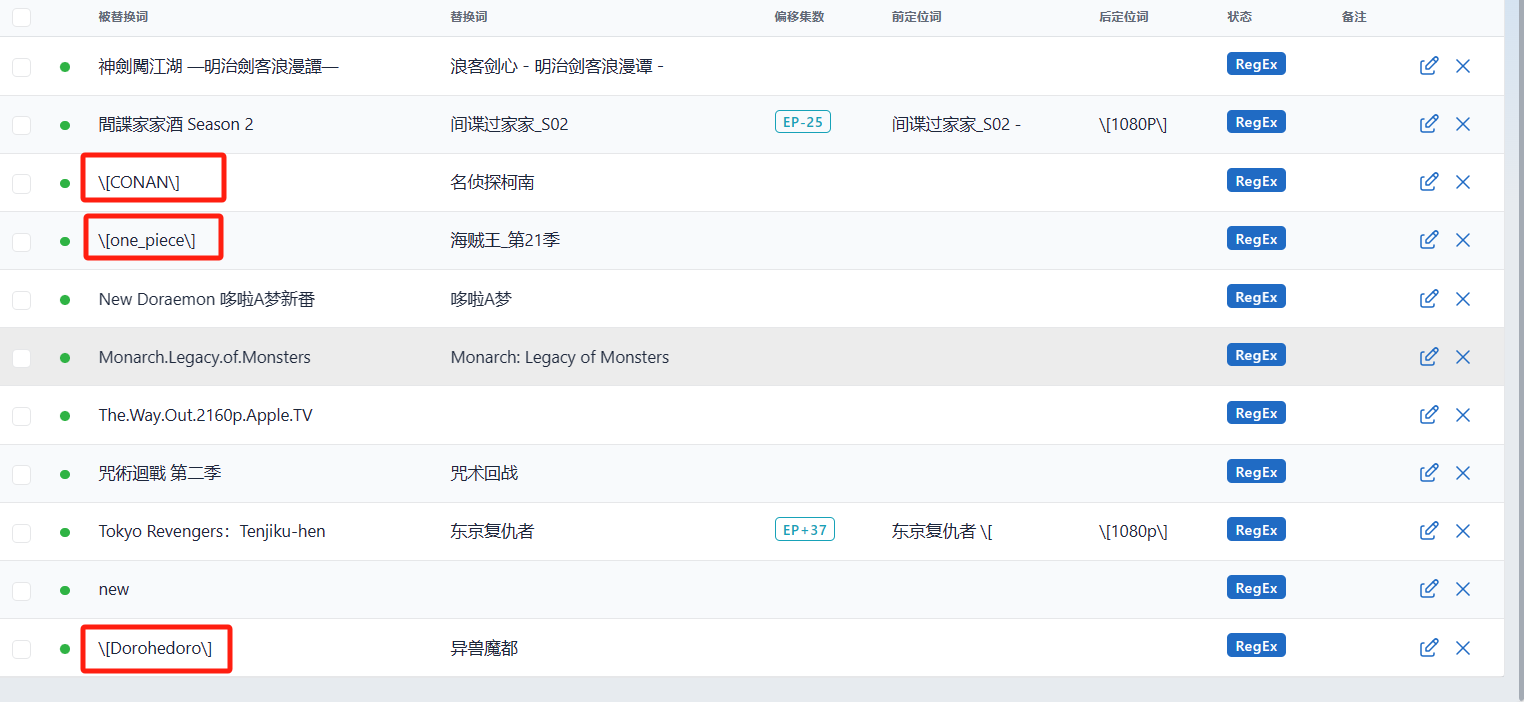
(2)已新增临时文件夹的目录的手动规整规范性目录的file_helper底层代码编写
(3)已增加is_anime的逻辑判断,利用anitopy库对anime进行文件识别,增强动漫的识别率
(4)已新增media代码里对多层目录的文件识别判断,增强对那种外层目录文件名的可以识别成电视剧、动漫的识别,再取最里面的文件名的信息,进行补全优化文件目录的识别,例如:(/鬼武者/01.1080p.HD中字[最新电影www.dygangs.me].mp4、/鬼武者/S01/01.1080p.HD中字[最新电影www.dygangs.me].mp4),优先识别外层目录中季数、名称等信息,再采取文件名信息补全,识别率又提高了
-
打算新增的功能:
- file_helper主要针对那种tmdb和豆瓣信息对anime每季信息不统一以及集数标号不是顺序排列的问题,比如精灵宝可梦、海贼王等,进行对每季的集数重新编排(根据目录文件的集数从小到大的顺序进行从1到xx进行重命名),会在前端中增加这个模块(持续中)
- 新增国内比较多的字幕组和其他的bt站的bt下载爬取适配,增加索引源
- 新增下载工具-百度云的转存适配,配合群晖的cloud sync的转存目录进行下载到对应的目录
解决方案:
通过nastools的api接口:/api/v1/rss/update进行新增或修改自定义订阅
触发条件:
通过豆瓣订阅触发后没有订阅到返回结果,从而返回一个tag变量传到触发
细节:
- 需要自建的rsshub的订阅(前端页面上需要新增一个输入,后端在config.yaml中加)
- 需要考虑rss订阅domain后缀需要域名是否能访问通