
Capstone Project
Can an image be used to accurately describe itself?
-
Visual Question Answering (VQA)
-
Audience: Computer vision enthusiasts, dog lovers, security services, and the visually impaired
-
Image data is a rich source of information. This project will aims to automate the task of extracting image descriptions.
Questions to be explored:
- Is the dog inside or outside?
- Does it have a friend?
- What breed is it?
- What layers need to be pre-trained?
- What is a reasonable 'optical cue'?
--- ### Overview
This DSI module covers:
- Machine Learning for Deep Neural Networks (TensorFlow, Keras API)
- Binary Classification Predictive Modeling
- Computer Vision ( RGB image processing, image formation, feature detection, computational photography)
- Convolutional Neural Networks(CNN)- regularization, automated pattern recognition, ...
- Transfer Learning with a pre-trained deep learning image classifier (VGG-16 CNN from Visual Geometry Group in 2014)
- Automatic photo captioning, Visual Question Answering (VQA)
- Background
- Data Aquisition & Cleaning
- Exploratory Analysis
- Findings and Recommendations
- Next Steps
- Software Requirements
- Acknowledgements and Contact
Here is some background info:
- Transfer learning: pre-existing model, trained on millions of images over the period of several weeks.
- Eliminates the need to afford cost of training deep learning models from scratch
- Deep CNN model training short-cut, re-use model weights from pre-trained models previously developed for benchmark tests in comupter vision
- VGG, Inception, ResNet:
- Weight initialization: weights in re-used layers used as starting point in training and adapted in response to new problem
- Use model as-is to classify new photographs
- Use as feature extraction model, output of pre-trained from a layer prior to output layer used as input to new classifier model
- Tasks more similar to the original training might rely on output from layers deep in the model such as the 2nd to last fully connected layer
- Layers learn:
- Layers closer to the input layer of the model: Learn low-level features such as lines, etc.
- Layers in the middle of the network of layers: Learn complex abstract features that combine the extracted lower-level features from the input
- Layers closer to the output: Interpret the extracted features in the context of a classification task
- Fine-tuning learning rate of pre-trained model
- Transfer Learning Tasks
- Architectures:
- Consistent and repeating structures (VGG)
- Inception modules (GoogLeNet)
- Residual modules (ResNet)
NOTE: Make sure you cross-reference your data with your data sources to eliminate any data collection or data entry issues.
See Acknowledgements and Contact section for starter code resources
| Feature | Type | Dataset | Category | Description |
|---|---|---|---|---|
| variable1 | dtype | Origin of Data | Category | Description |
| variable2 | dtype | Origin of Data | Category | Description |
| IMAGE_HEIGHT | int | utils.py | Global Variable | 224(pixels) |
| IMAGE_WIDTH | int | utils.py | Global Variable | 224(pixels) |
| IMAGE_CHANNELS | int | utils.py | Global Variable | 3-RGB Channels |
| variable2 | dtype | Origin of Data | Category | Description |
| variable1 | dtype | Origin of Data | Category | Description |
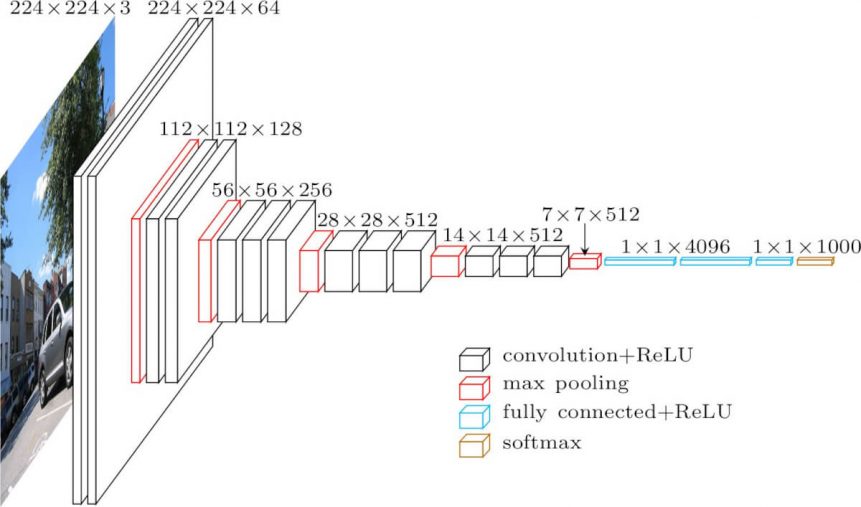
| VGG-16 Block | Name (Type) | Kernel Size | Nodes | Params # | Stride/Pool | Output ( h x w x depth ) |
|---|---|---|---|---|---|---|
| 00-First | input1 (Input) | No Filter | None | 0 | None | ( Batch, 224, 224, 3-RGB ) |
| 01-Block 01 | conv1 (Conv2D) | ( 3 x 3 ) | 64 | 1,792 | ( 1 x 1 ) | ( Batch, 224, 224, 64 ) |
| 02-Block 01 | conv2 (Conv2D) | ( 3 x 3 ) | 64 | 36,928 | ( 1 x 1 ) | ( Batch, 224, 224, 64 ) |
| 03-Block 01 | pool1 (MaxPooling2D) | ( 2 x 2 ) | None | 0 | ( 2 x 2 ) | ( Batch, 112, 112, 64 ) |
| 04-Block 02 | conv1 (Conv2D) | ( 3 x 3 ) | 128 | 73,856 | ( 1 x 1 ) | ( Batch, 112, 112, 128 ) |
| 05-Block 02 | conv2 (Conv2D) | ( 3 x 3 ) | 128 | 147,584 | ( 1 x 1 ) | ( Batch, 112, 112, 128 ) |
| 06-Block 02 | pool2 (MaxPooling2D) | ( 2 x 2 ) | None | 0 | ( 2 x 2 ) | ( Batch, 56, 56, 128 ) |
| 07-Block 03 | conv1 (Conv2D) | ( 3 x 3 ) | 256 | 295,168 | ( 1 x 1 ) | ( Batch, 56, 56, 256 ) |
| 08-Block 03 | conv2 (Conv2D) | ( 3 x 3 ) | 256 | 590,080 | ( 1 x 1 ) | ( Batch, 56, 56, 256 ) |
| 09-Block 03 | conv3 (Conv2D) | ( 3 x 3 ) | 256 | 590,080 | ( 1 x 1 ) | ( Batch, 56, 56, 256 ) |
| 10-Block 03 | pool3 (MaxPooling2D) | ( 2 x 2 ) | None | 0 | ( 2 x 2 ) | ( Batch, 28, 28, 256 ) |
| 11-Block 04 | conv1 (Conv2D) | ( 3 x 3 ) | 512 | 1,180,160 | ( 1 x 1 ) | ( Batch, 28, 28, 512 ) |
| 12-Block 04 | conv2 (Conv2D) | ( 3 x 3 ) | 512 | 2,359,808 | ( 1 x 1 ) | ( Batch, 28, 28, 512 ) |
| 13-Block 04 | conv3 (Conv2D) | ( 3 x 3 ) | 512 | 2,359,808 | ( 1 x 1 ) | ( Batch, 28, 28, 512 ) |
| 14-Block 04 | pool4 (MaxPooling2D) | ( 2 x 2 ) | None | 0 | ( 2 x 2 ) | ( Batch, 14, 14, 512 ) |
| 15-Block 05 | conv1 (Conv2D) | ( 3 x 3 ) | 512 | 2,359,808 | ( 1 x 1 ) | ( Batch, 14, 14, 512 ) |
| 16-Block 05 | conv2 (Conv2D) | ( 3 x 3 ) | 512 | 2,359,808 | ( 1 x 1 ) | ( Batch, 14, 14, 512 ) |
| 17-Block 05 | conv3 (Conv2D) | ( 3 x 3 ) | 512 | 2,359,808 | ( 1 x 1 ) | ( Batch, 14, 14, 512 ) |
| 18-Block 05 | pool5 (MaxPooling2D) | ( 2 x 2 ) | None | 0 | ( 2 x 2 ) | ( Batch, 7, 7, 512 ) |
| 19 4D --> 2D | flatten (Flatten) | No Filter | None | 0 | None | ( Batch, 25,088 ) |
| 20-Fully Connected | fcon1 (Dense) | No Filter | 4,096 | 102,764,544 | None | ( Batch, 4,096 ) |
| 21-Fully Connected | fcon2 (Dense) | No Filter | 4,096 | 16,781,312 | None | ( Batch, 4,096 ) |
| 22-Last Layer | Output (Dense) | No Filter | 1,000 | 4,097,000 | None | ( Batch, 1,000 ) |
- NOTE :
CONV2D: # Param = [ (Kernel-Size x Channel-Depth)+1 ] x Filters-Nodes
DENSE : # Param = [ ( Input Size/Shape ) + 1 ] x Output Size/Shape
- Total params: 138,357,544
- Trainable params: 138,357,544
- Non-trainable params: 0
| CNN Model | Split | Epoch | Loss | Accuracy |
|---|---|---|---|---|
| Bseline MSE | Training | 01 | 0.0316 | 0.3251 |
| Bseline MSE | Validation | 01 | 0.0191 | 0.8220 |
| Bseline MSE | Training | 02 | 0.0266 | 0.3248 |
| Bseline MSE | Validation | 02 | 0.0205 | 0.8240 |
- Google CoLab Pro High-RAM(27.4 GB RAM available in runtime memory) plus GPU had to be used to fit the transfer model without a batch generator(cost $10 for the month). Even with the High-RAM I had to be very careful with order of loading variables into memory. Colab Kernels crashed many times and everytime had to start over from scratch with data loading.
- Network architecture: X layers, X convolution layers, X fully connected layers
- model_vgg16_flatten.h5
- Insert EDA details...
- 108,077 images total in Visual Genome(VG), 3,235 images with dogs (or hot dogs, see below), 1,995 dog pics in training dataset (part 1), 1,240 dog pics in
- Hot dogs, I saw like anywhere between 6-10 in the images that were supposed to be dogs. This is a problem, because they are randomly labeled improperly. It makes me have to ask the question, what other common words are introducing bias in the AI due to language?
Answer the problem statement:
- YES, with an accuracy of 97.5% the model can identify a dog in an image it has never seen before. With an accuracy about half a percentage point above the baseline score of 97% which would result if the model predicted every single image had no dog, we can say that the model is better than no model lol. Important to consider, moving forward, would be a batch generator to reduce memory demands by moving old batches of data out of memory and new batches of data into RAM iteratively as the model is training. This allows for a number of benefits such as: A.) Data Augmentation, I actually have written a batch generator to perform image augmentation which will act as a regularization technique by preventing overfitting. By augmenting training data the model never sees the exact same image twice and this is ok because a dog is still a dog even if it flipped, reduced in size, enlarged, rotated, etc. B.) Batch size is given more freedom to choose larger BASE-2 values, because we no longer need load the entire image dataset into memory.
- Consider the similarity of images, specifically ImageNet images vs Visual Genome data. Visual Genome images are very random with dog objects as the minor object in many. Images have on average up to 35 objects identified, but I did not look at any ImageNet data. Maybe I could have extracted features from a layer lower in the network near the input and obtained less error.
- Predicting breeds would be pretty cool. All I would need to do is ID the breed of dog in over 3K images lol. Ideally an app hosted on Heroku that allows users to upload a dog pic and in return they get the top 5 breed predictions from the model. Top 5 because if someone wants to know the breed of their dog it probably isn't a purebreed. It probably is a mut and multiple breed labels are more apropriate.
https://www.quora.com/What-is-the-VGG-neural-network
External Resources:
- [
High quality images of dogs] (Unsplash): (source) - [
VQA labeled images of dogs] (Visual Genome): (source) - [
Google Open Source: Dog Detection] (Open Images): (source) - [
Google Open Source: Dog Segmentation] (Open Images): (source) - [
VGG-19] (Keras API): (source) - [
ImageNet ILSVRC Competition] (Machine Learning Mastery): (source)
Photo by jesse orrico on Unsplash
<span>Photo by <a href="https://unsplash.com/@wildmooncreative?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Kasey McCoy</a> on <a href="https://unsplash.com/s/photos/dogs?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a></span>
Papers:
VisualBackProp: efficient visualization of CNNs(arXiv): (source)Very Deep Convolutional Networks For Large-Scale Image Recognition(arXiv): (source)Transfer Learning in Keras with Computer Vision Models(Machine Learning Mastery): (source)
Project Link: (source)
Materials must be submitted by 4:59 PST on Friday, December 11, 2020.
- CONV2D: # Param = [ (Kernel-Size x Channel-Depth)+1 ] x Filters-Nodes
- DENSE : # Param = [ ( Input Size/Shape ) + 1 ] x Output Size/Shape
- ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
- evaluates algorithms for object localization/detection from images/videos at scale
- Visual Geometry Group from Oxford 2014