In this machine learning project, we will recognize handwritten characters, i.e, English alphabets from A-Z. This we are going to achieve by modeling a neural network that will have to be trained over a dataset containing images of alphabets.
With the help of a multilayer Feed Forward neural network, handwritten English alphabet characters are tried to be recognised. The neural network is trained using a dataset made up of English alphabets.. The dataset for this project contains 372450 images of alphabets of 28×2, all present in the form of a CSV file.The feature extraction technique is obtained by normalizing the pixel values. Pixel values will range from 0 to 255 which represents the intensity of each pixel in the image and they are normalized to represent value between 0 and 1. Convolutional neural network is used as a classifier which trains the dataset. The prediction for the given input image is obtained from the trained classifier.

- Python (3.7.4 used)
- IDE (Jupyter Notebook Used)
- NumPy (version 1.16.5)
- cv2 (openCV) (version 3.4.2)
- Keras (version 2.3.1)
- Tensorflow (Keras uses TensorFlow in backend and for some image preprocessing) (version 2.0.0)
- Matplotlib (version 3.1.1)
- Pandas (version 0.25.1)
The dataset for this project contains 372450 images of alphabets of 28×2, all present in the form of a CSV file.
Handwritten character recognition dataset
- First of all, we do all the necessary imports as stated above. We will see the use of all the imports as we use them.

-
Reading the dataset:
-
Now we are reading the dataset using the pd.read_csv() and printing the first 10 images using data.head(10)

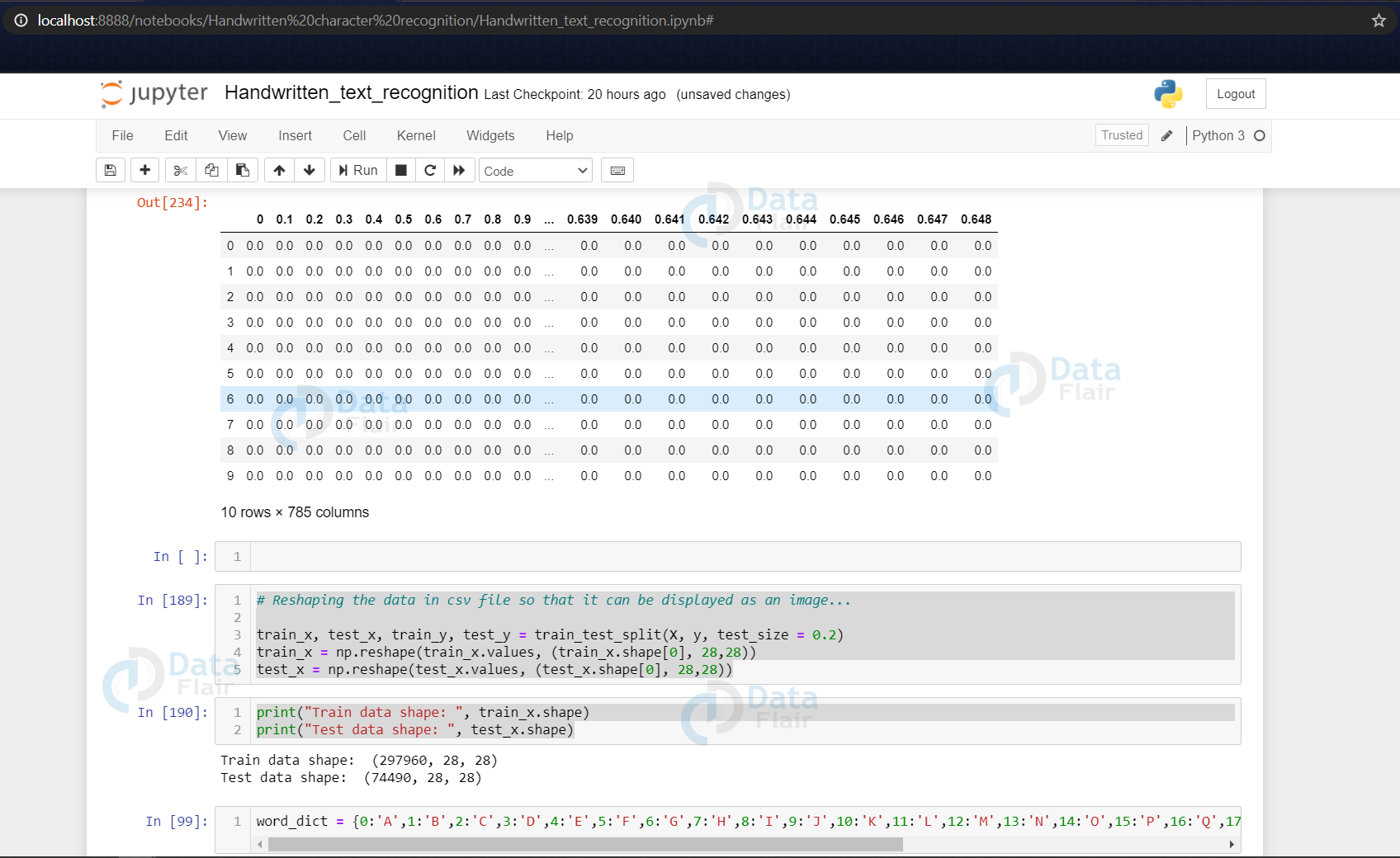
(The above image shows some of the rows of the dataframe data using the head() function of dataframe)
- Split data into images and their labels:

Splitting the data read into the images & their corresponding labels. The ‘0’ contains the labels, & so we drop the ‘0’ column from the data dataframe read & use it in the y to form the labels.
Reshaping the data in the csv file so that it can be displayed as an image

-
In the above segment, we are splitting the data into training & testing dataset using train_test_split().
-
Also, we are reshaping the train & test image data so that they can be displayed as an image, as initially in the CSV file they were present as 784 columns of pixel data. So we convert it to 28×28 pixels.

- All the labels are present in the form of floating point values, that we convert to integer values, & so we create a dictionary word_dict to map the integer values with the characters.
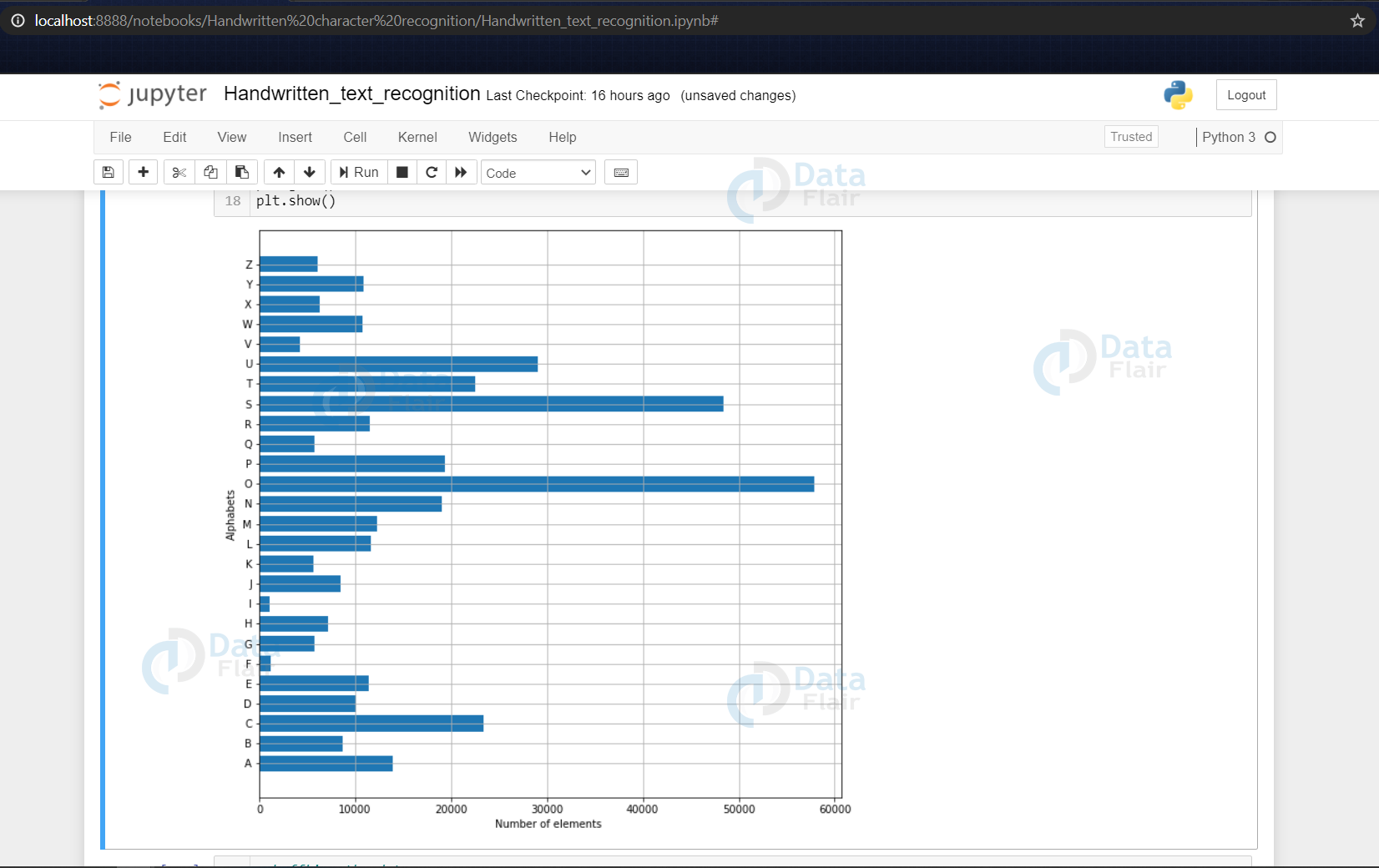
Plotting the number of alphabets in the dataset

-
Here we are only describing the distribution of the alphabets.
-
Firstly we convert the labels into integer values and append into the count list according to the label. This count list has the number of images present in the dataset belonging to each alphabet.
-
Now we create a list – alphabets containing all the characters using the values() function of the dictionary.
-
Now using the count & alphabets lists we draw the horizontal bar plot.
Shuffling the data

-
Now we shuffle some of the images of the train set.
-
The shuffling is done using the shuffle() function so that we can display some random images.
-
We then create 9 plots in 3×3 shape & display the thresholded images of 9 alphabets.

(The above image depicts the grayscale images that we got from the dataset)
Reshaping the training & test dataset so that it can be put in the model

Now we reshape the train & test image dataset so that they can be put in the model.
New shape of train data: (297960, 28, 28, 1)
New shape of train data: (74490, 28, 28, 1)

Here we convert the single float values to categorical values. This is done as the CNN model takes input of labels & generates the output as a vector of probabilities.
Now we define the CNN.
What is CNN?
CNN stands for Convolutional Neural Networks that are used to extract the features of the images using several layers of filters.
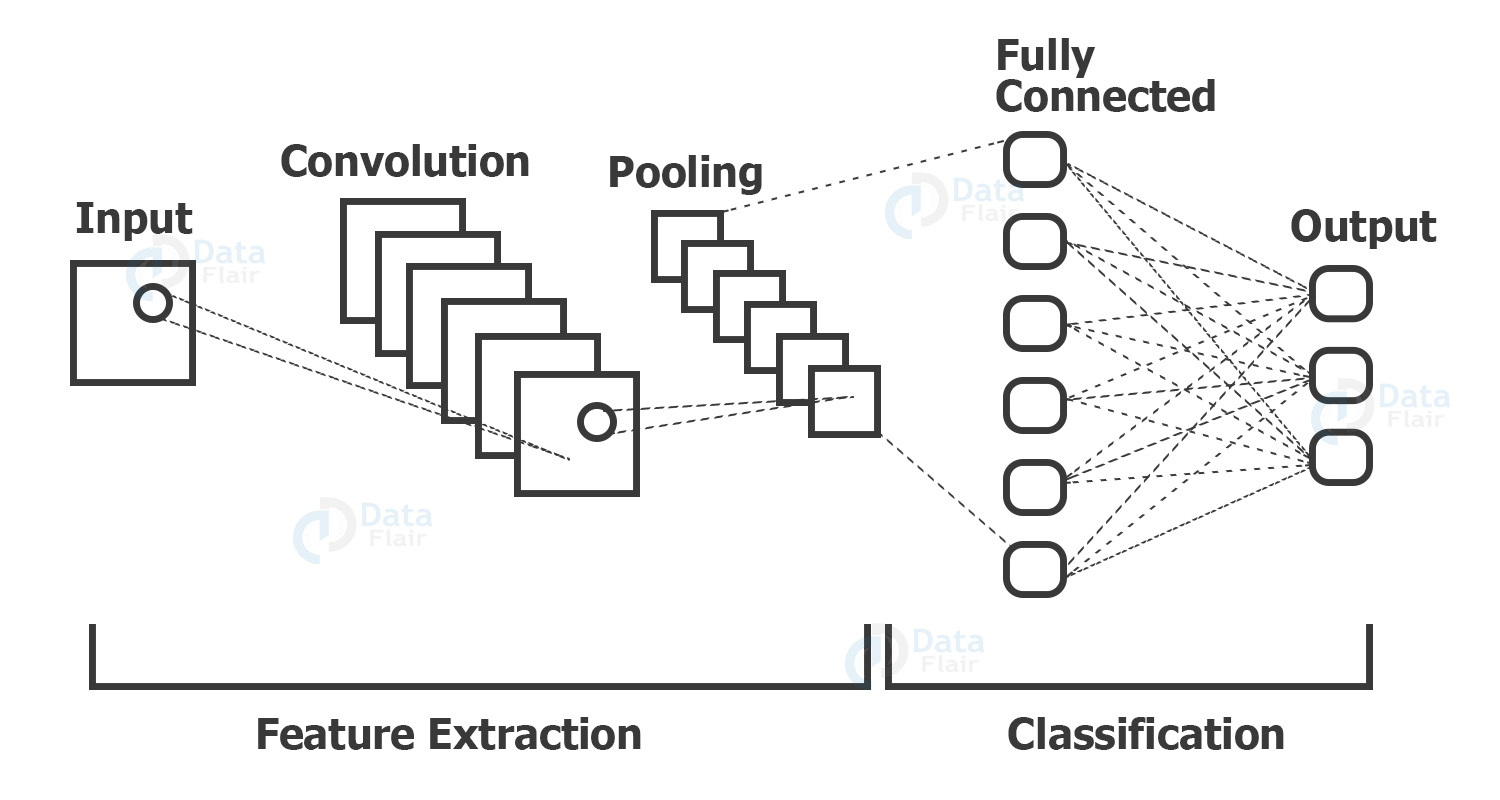
(Example of how a CNN looks logically)
The convolution layers are generally followed by maxpool layers that are used to reduce the number of features extracted and ultimately the output of the maxpool and layers and convolution layers are flattened into a vector of single dimension and are given as an input to the Dense layer (The fully connected network).
The model created is as follows:

Above we have the CNN model that we designed for training the model over the training dataset.
Compiling & Fitting Model

-
Here we are compiling the model, where we define the optimizing function & the loss function to be used for fitting.
-
The optimizing function used is Adam, that is a combination of RMSprop & Adagram optimizing algorithms.
-
The dataset is very large so we are training for only a single epoch, however, as required we can even train it for multiple epochs (which is recommended for character recognition for better accuracy).

Now we are getting the model summary that tells us what were the different layers defined in the model & also we save the model using model.save() function.

(Summary of the defined model)
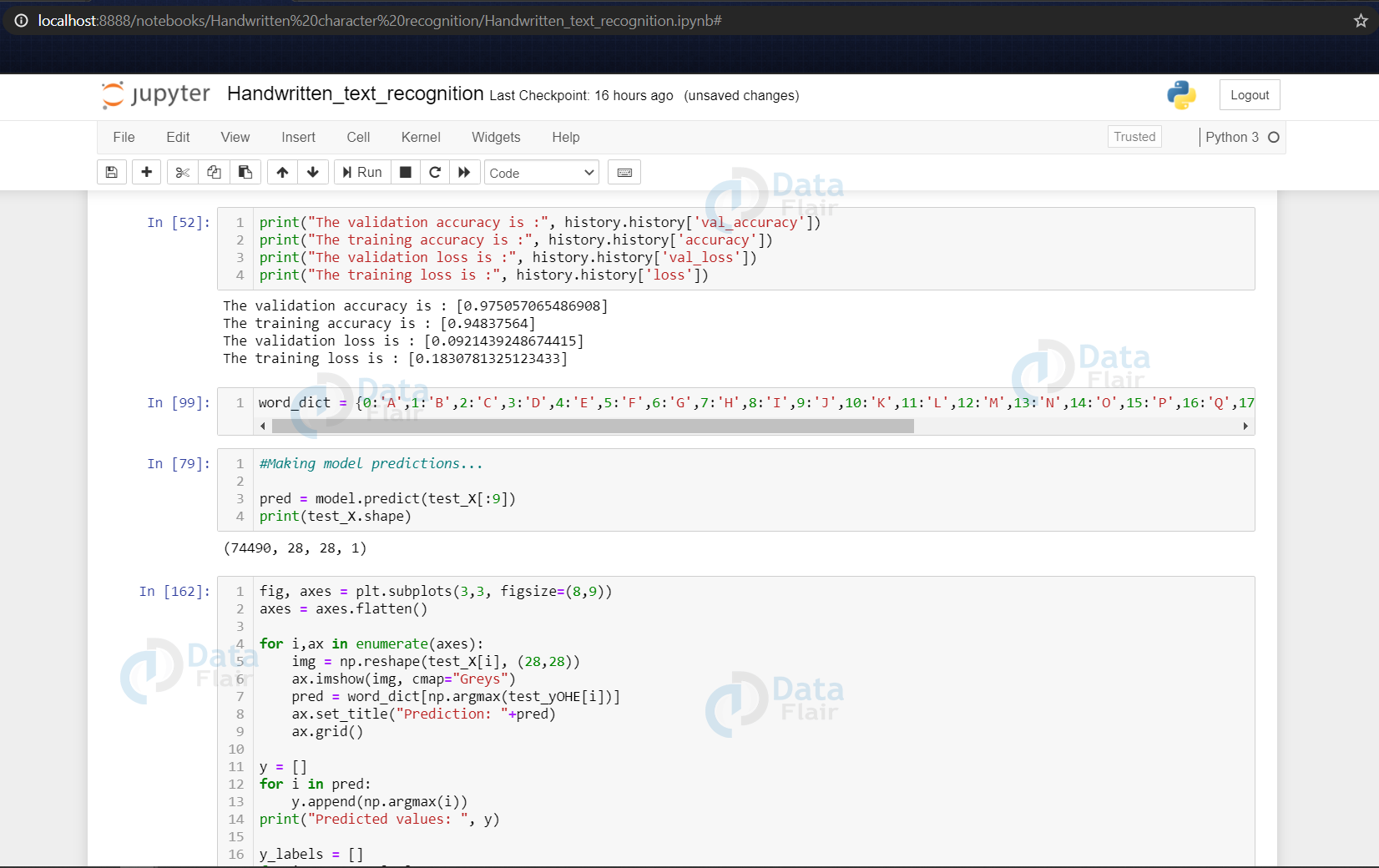
Getting the Train & Validation Accuracies & Losses

In the above code segment, we print out the training & validation accuracies along with the training & validation losses for character recognition.
Doing Some Predictions on Test Data

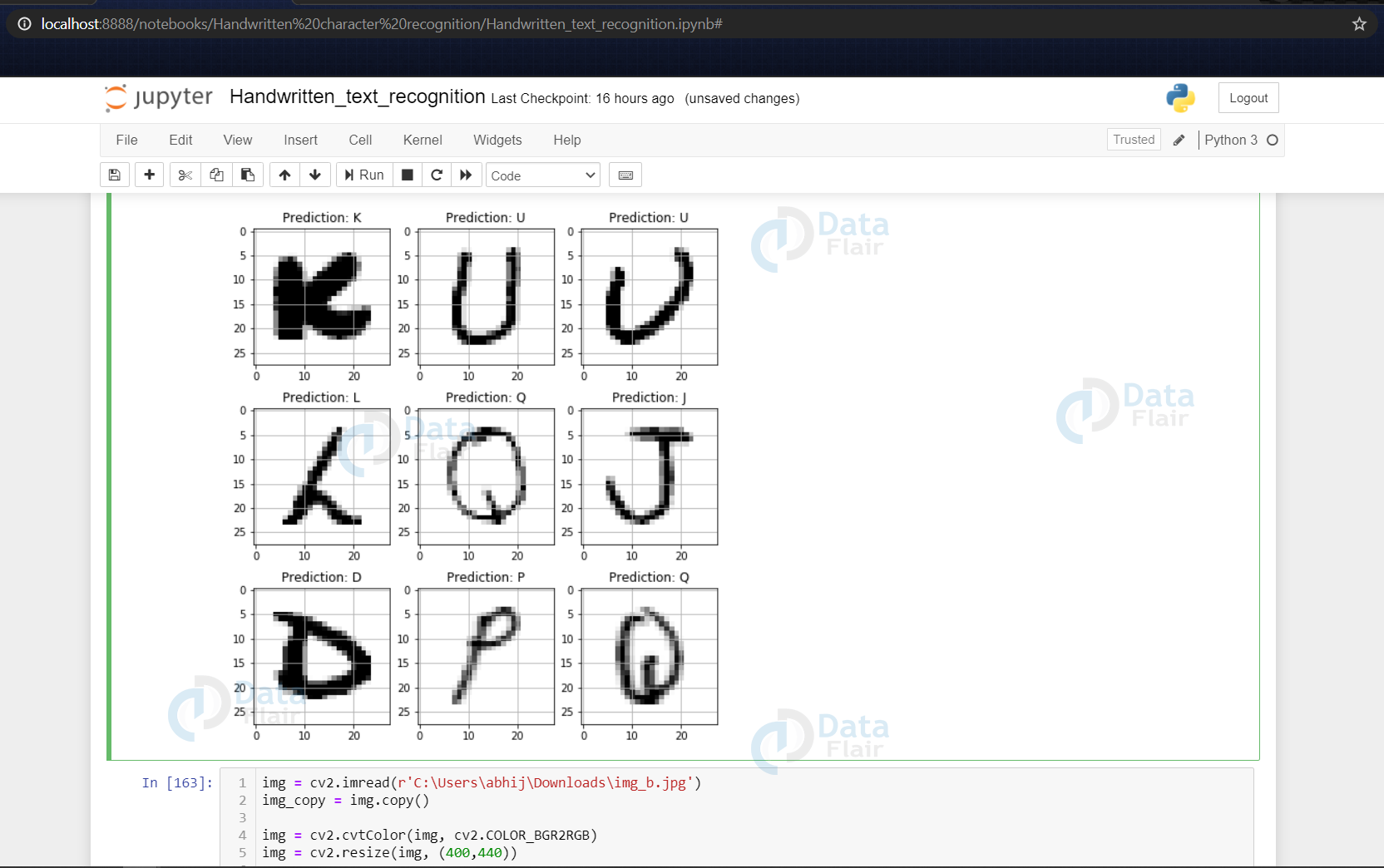
- Here we are creating 9 subplots of (3,3) shape & visualize some of the test dataset alphabets along with their predictions, that are made using the model.predict() function for text recognition.
Doing Prediction on External Image

-
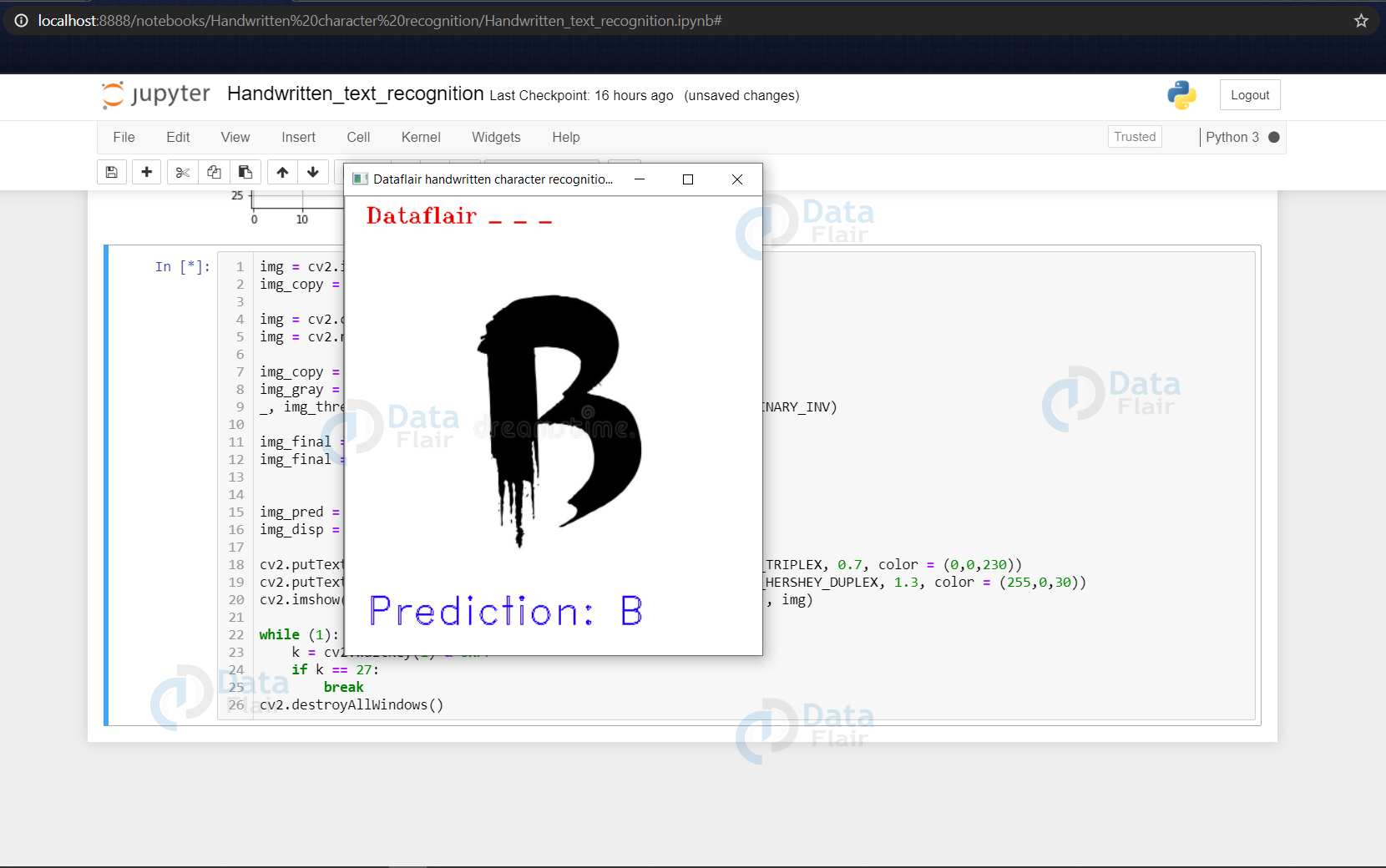
Here we have read an external image that is originally an image of alphabet ‘B’ and made a copy of it that is to go through some processing to be fed to the model for the prediction that we will see in a while.
-
The img read is then converted from BGR representation (as OpenCV reads the image in BGR format) to RGB for displaying the image, & is resized to our required dimensions that we want to display the image in.

-
Now we do some processing on the copied image (img_copy).
-
We convert the image from BGR to grayscale and apply thresholding to it. We don’t need to apply a threshold we could use the grayscale to predict, but we do it to keep the image smooth without any sort of hazy gray colors in the image that could lead to wrong predictions.
-
The image is to be then resized using cv2.resize() function into the dimensions that the model takes as input, along with reshaping the image using np.reshape() so that it can be used as model input.

-
Now we make a prediction using the processed image & use the np.argmax() function to get the index of the class with the highest predicted probability. Using this we get to know the exact character through the word_dict dictionary.
-
This predicted character is then displayed on the frame.

- Here we are setting up a waitKey in a while loop that will be stuck in loop until Esc is pressed, & when it gets out of loop using cv2.destroyAllWindows() we destroy any active windows created to stop displaying the frame.
{kind=link}
{kind=link}
We have successfully developed Handwritten character recognition (Text Recognition) with Python, Tensorflow, and Machine Learning libraries.
Handwritten characters have been recognized with more than 97% test accuracy. This can be also further extended to identifying the handwritten characters of other languages too.