{kind=link}
{kind=link}
{kind=link}
This is the source coude for the paper Using Synthetic Data to Enhance the Accuracy of Fingerprint-based Localization: A Deep Learning Approach, IEEE Sensors Letters, vol. 4, no. 4, pp. 1-4, April 2020, doi: 10.1109/LSENS.2020.2971555.
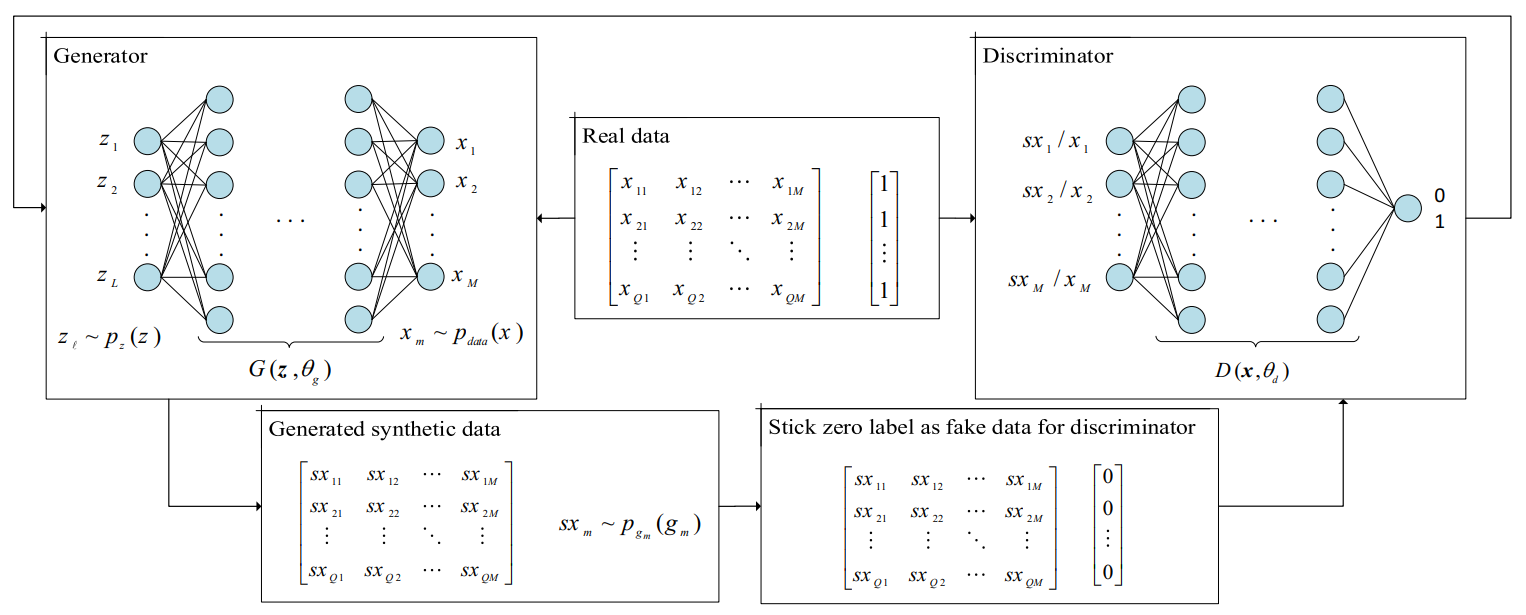
The goal is to utilize Generative Adversarial Networks (GANs) to enhance the accuracy of Wi-Fi Received Signal Strength (RSS) fingerprint-based localization methods.
The benchmark dataset is taken from UCI Machine Learning Repository and is collected by Rajen Bhatt. This dataset consists of 2000 RSS samples collected from 7 Access Points (APs) inside four different rooms.
- Jupyter Notebooks
- Tensorflow 1.1x
- Keras
- numpy
- sklearn
- tqdm
- pandas
- matplotlib
Initially, the dataset is separated into training and test data equally so that both datasets contain 250 data samples of each class. By reducing the problem of indoor localization to a common classification task, we can use a Multilayer Perceptron (MLP) with six densely connected layers as our base model. The inputs and outputs of this model are RSS samples and the probability of the presence in each class, respectively.
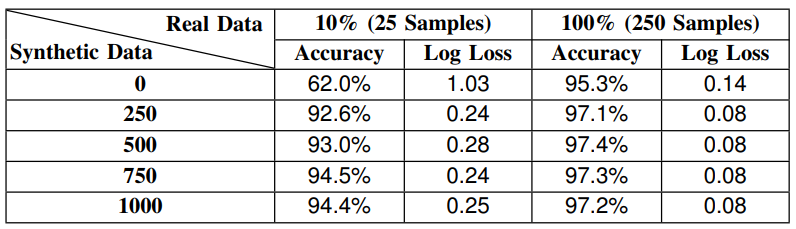
Next, a GAN is trained once with 10% of the training data (25 samples per class) and another time with full training data to generate various numbers of synthetic data. This generated data is shuffled with the real data and is fed to the MLP classification model to compare the performance. To mitigate the effect of randomness, this process is done 100 times with different initial random seeds, and the results are averaged over these runs. The results are as follows:
Furthermore, a fraction of the real data is randomly selected to generate synthetic data, in a way that the total number of data after adding and shuffling the synthetic data will be equal to the total number of the original data in each class (which is 250). The results, as depicted below, suggest that adding synthetic data to the real data will increase the accuracy significantly.
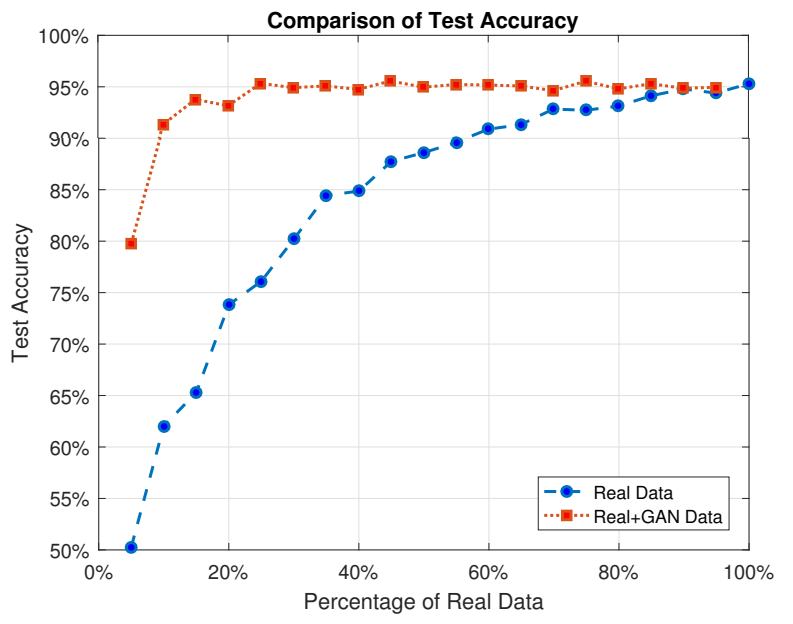
Data collection is costly and imposes privacy issues. Many solutions are proposed in the literature to reduce this cost, such as crowd-sourcing methods in data collection or using semi-supervised algorithms to enhance the positioning accuracy. However, semi-supervised algorithms need unlabeled data, and crowd-sourcing based methods need many participants. Fingerprint-based localization methods use received signal strength (RSS) or channel state information (CSI) in wireless sensor networks to localize the users in indoor or harsh outdoor environments. In this paper, we introduce a new method to reduce the data collection costs by using synthetic data in fingerprint-based localization. We use generative adversarial networks (GANs) to learn the distribution of a limited collected data and further, produce synthetic data and feed them to the system in addition to the real collected data in order to increase the positioning accuracy. Experimental results on a benchmark dataset show that by applying the proposed method and using a combination of 10% collected data and 90% synthetic data, we can get completely close to the accuracy as if we would use the whole collected data. It means that we can use 90% less real data and reduce the data collection costs while reaching the acceptable accuracy, using GAN generated synthetic data.
If you find this code useful in your research, please consider citing:
@article{nabatiUsingSyntheticData,
author={Nabati, Mohammad and Navidan, Hojjat and Shahbazian, Reza and Ghorashi, Seyed Ali and Windridge, David},
journal={IEEE Sensors Letters},
title={Using Synthetic Data to Enhance the Accuracy of Fingerprint-Based Localization: A Deep Learning Approach},
year={2020},
volume={4},
number={4},
pages={1-4},
doi={10.1109/LSENS.2020.2971555}}