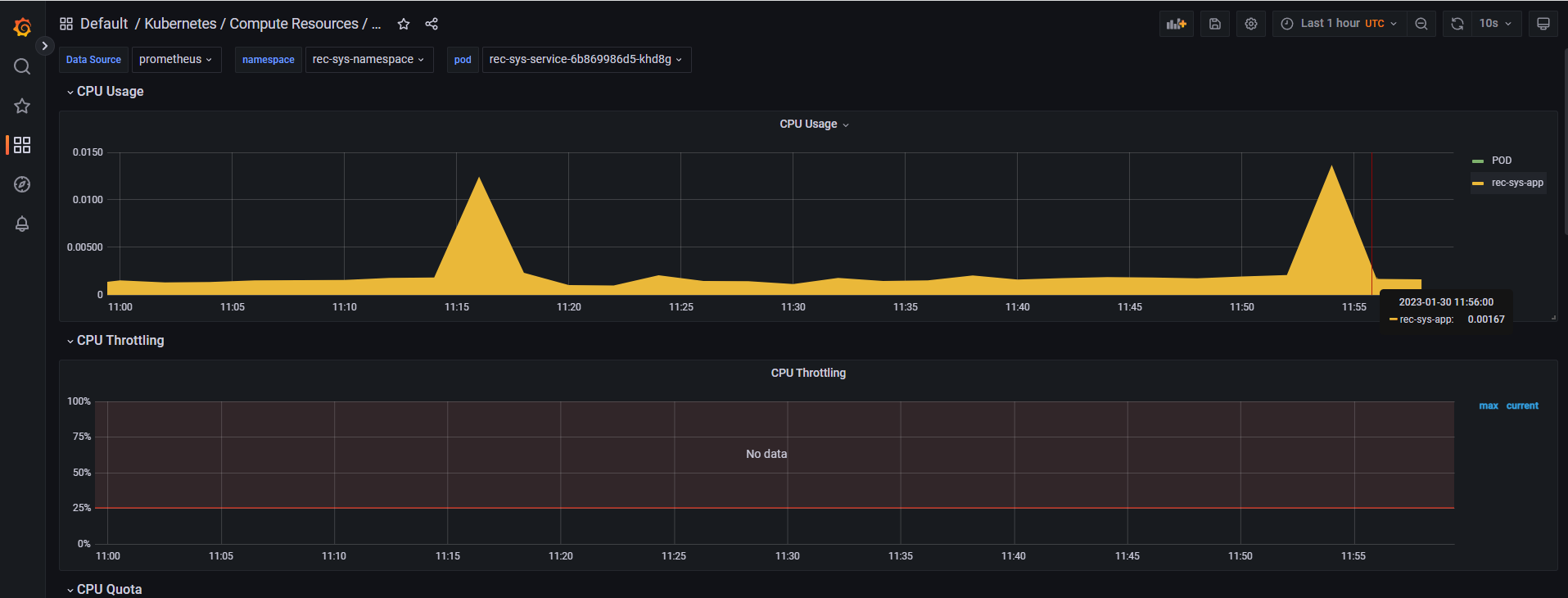
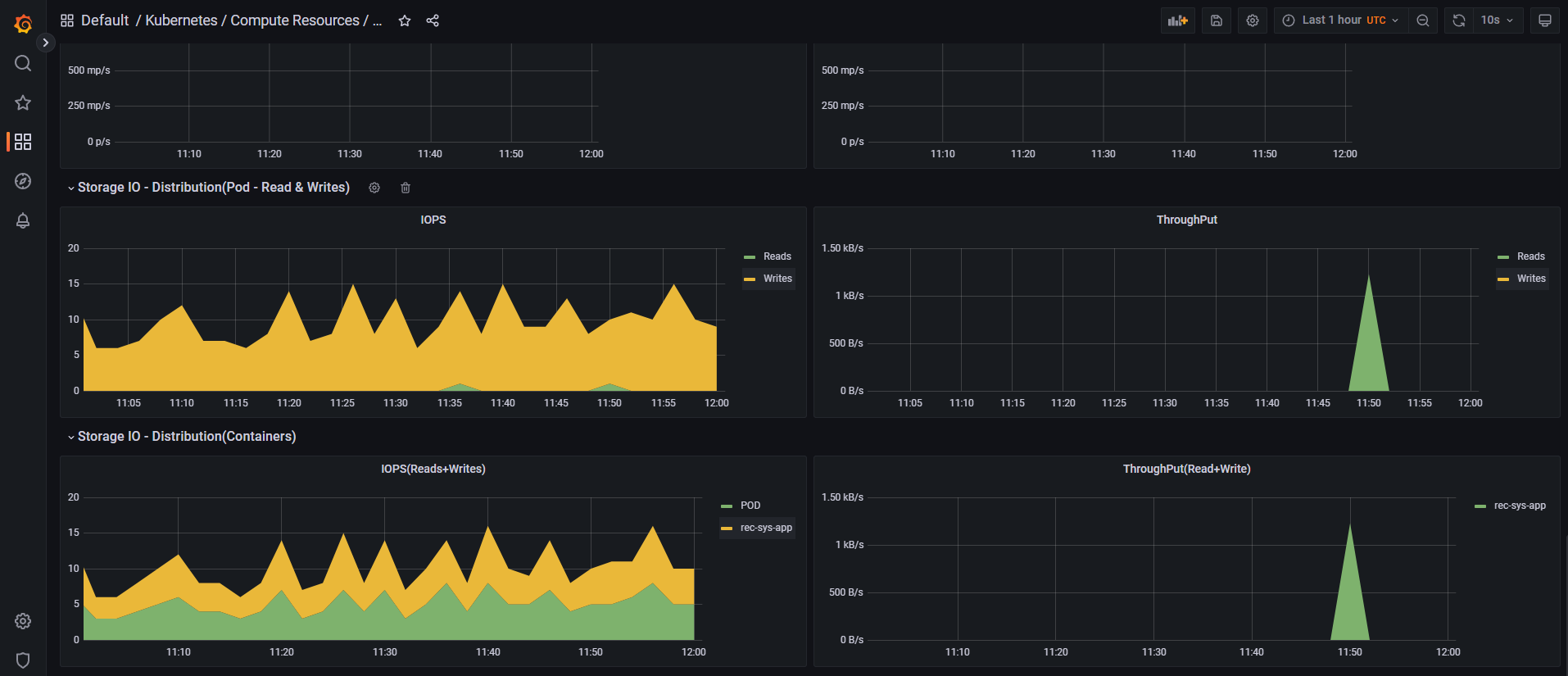
This anime recommender engine aka My Otaku Friend uses a hybrid ML model and complex DevOps infrastructure to give you recommendations based on the anime you like or have already watched and rated, or your genre preferences. This concise doc is meant to give you an idea of its basic modules and ways of using.
You can either run the service locally using Docker or deploy it on your own Kubernetes cluster and send API requests.
To run locally, you would need to install Docker first:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo usermod -aG docker $USER
Then use the following commands to pull the image from the Docker registry and run the container locally:
sudo docker pull horacehub/rec-sys-app:latest
sudo docker run --name rec-sys-container -p 80:80 rec-sys-app
To deploy the app on your Kubernetes cluster, you can use the manifests in the k8s-manifests folder. You might want to introduce some changes to fit your infrastructure. Below are the commands used to deploy the service:
kubectl create namespace rec-sys-namespace
kubectl apply -f rec-sys-app.yaml
kubectl apply -f rec-sys-app-balancer.yaml
To check if the pods and the deployment are running:
kubectl get pod -o wide -n rec-sys-namespace
kubectl get deployment -n rec-sys-namespace -o wide
To delete the deployment:
kubectl delete deployment rec-sys-service -n rec-sys-namespace
kubectl delete pod [name_of_pod] -n rec-sys-namespace
To restart the deployment:
kubectl rollout restart deployment/rec-sys-service --namespace=rec-sys-namespace
When the service is running, you can use the post method of the Python requests library to get recommendations via API. You need to specify the IP address of your k8s load balancer (alternatively, use 0.0.0.0 if you're running the Docker container locally). Below are sample requests to the service deployed on my k8s cluster:
- Sample request for an existing user:

- Sample request for a new user without preferences:

- Sample request for a new user with preferences:

- Sample request for a specific anime:

This is a brief explanation of the ML stack used by the service to give you high-quality recommendations. The system consists of the following components:
- Pre-trained LightFM item embeddings using a hybrid approach (https://github.com/horacemtb/Anime-recommender-engine/blob/main/research/baseline-light-FM-with-cross-val-and-hyperparam-tuning-50e.ipynb)
- Bert embeddings of item descriptions (https://github.com/horacemtb/Anime-recommender-engine/blob/main/research/anime-synopsis-prep-bert-emb.ipynb)
- User features based on user preferences
- LightGBM regressor for item ranking (https://github.com/horacemtb/Anime-recommender-engine/blob/main/research/lightgbm-regression-with-lightfm-emb-50e%2Bbert-features.ipynb)
- Cosine similarity for final selection (https://github.com/horacemtb/Anime-recommender-engine/blob/main/research/predict.ipynb)
The first step is to generate anime embeddings based on user and item features. The user features are made from data containing their preferences and mean rating:

There a total of 45 user features.
The item features are made from data containing a lot of information about the anime, such as average score, type, number of episodes, genres, number of ratings, etc.:
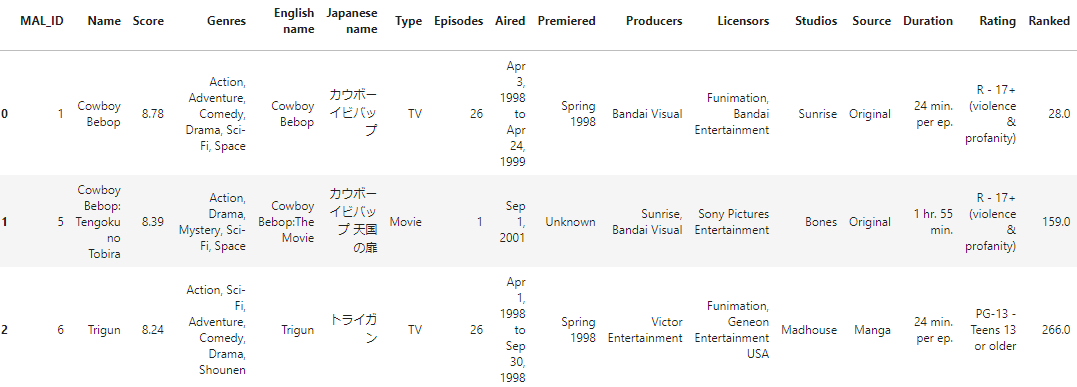
The categorical features are preprocessed using one-hot encoding and numerical features are scaled with MinMaxScaler(). There are a total of 98 item features.
The resulting user matrix dimensions are:
<13102x13147 sparse matrix of type '<class 'numpy.float32'>'
with 602692 stored elements in Compressed Sparse Row format>
13102 unique users x (13102 unique users + 45 user features).
The resulting item matrix dimensions are:
<14353x14451 sparse matrix of type '<class 'numpy.float32'>'
with 1420947 stored elements in Compressed Sparse Row format>
14353 unique anime x (14353 unique anime + 98 item features).
The interaction and weight matrix dimensions are:
<13102x14353 sparse matrix of type '<class 'numpy.int32'>'
with 2435913 stored elements in COOrdinate format>
13102 unique users x 14353 unique anime.
The dataset is split into train and test data with 0.2 proportion. The model is trained for 50 epochs with the following params: no_components = 64, loss = "warp", k = 15. The resulting metrics on the test set are: test precision@k: 0.13045670092105865, test recall@k10: 0.09071833029967415.

N.B. This process is used to only generate item embeddings that incorporate data about the item and user features and users' ratings. The resulting item matrix has dimensions of 14353x65 (anime_id + 64 features) and is saved to a separate file.
Next, BERT embeddings of anime synopses are generated using the all-MiniLM-L12-v2 sentence transformer and taking mean of all sentence embeddings along 0 axis for those synopses that contain more than one sentence. The embedding length is 384.
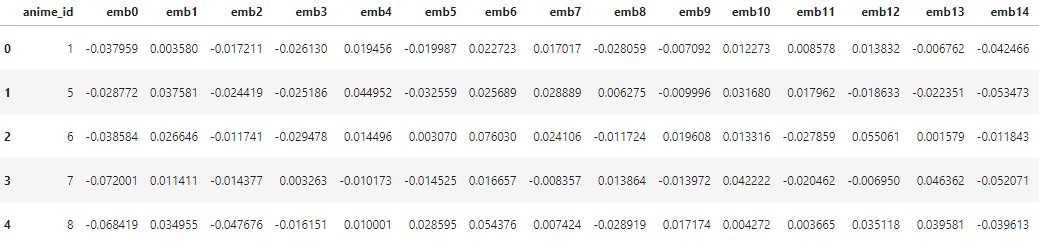
The final anime embeddings are made by concatenating LightFM and BERT embeddings.
The next step involves training a LightGBM regression model to predict the ratings for each user-anime pair, a total of 2435913 unique pairs. The dataset is made by concatenating user vectors (i.e. user genre preferences) with the anime embeddings. The dataset is then split into train, test and validation, having 8908, 2621 and 1573 unique user ids respectively. The model uses the following params: {'objective': 'regression', 'max_depth': 8, 'n_estimators': 2000, 'num_leaves': 2**8-1, 'learning_rate': 0.01, 'colsample_bytree': 0.8, 'subsample': 0.8, 'early_stopping_rounds': 20, 'random_state': 42, 'n_jobs': 8}, and is trained for 2000 iterations. The median absolute error on the test set is 0.72.
The final recommendations for a single existing user are generated using the following algorithm:
- The user's rating is predicted for each of the 14353 anime.
- The LightGBM regressor is applied to rank the predictions, of which top 1000 are selected.
If the user's watch history has any anime rated 7 or higher:
- All the anime with the highest rating are selected from the watch history.
- A mean embedding of the user's top rated anime is generated based on LightFM and BERT embeddings to represent the user's ideal preference.
- Cosine similarity is used to find the top 10 similar anime among the rest of the anime.
- The selected top 10 anime are ranked based on the predicted LightGBM ratings.
If the user's watch history has anime with ratings lower than 7, i.e. the user didn't like anything they've watched:
- The top 10 anime are selected and ranked based on the LightGBM predicted ratings exclusively.
This approach is used to estimate the performance of the algorithm on the test set, i.e. the 2621 unique user ids mentioned above. The resulting metrics are as follows: precision@10 is 0.4449, recall@10 is 0.1856, which I personally consider a solid score.
Okay, but what shall we do with a new user not found in our database? This depends on whether the user has specified their preferences or not. If not, the recommedation algorithm works the same as in the case with a user's watch history containing only the anime ranked below 7. If a dictionary with user's preferences is provided, the algorithms selects the anime of those genres that fall into the user's preferences. After that, the LightGBM regressor is applied to select and rank the top 10 recommendations.
The final implementation of the recommender engine also includes anime similarity search in case the user has provided a string with the name of the anime they like. This algorithm works based on cosine similarity between anime embeddings. The Jaro-Winkler method is applied to correct possible typos.
The application module is located in the app folder. The ML stack is implemented in the predict.py script: https://github.com/horacemtb/Anime-recommender-engine/blob/main/app/predict.py The data and models folder contain the files with embeddings plus user data and a LightGBM regressor model respectively.
The web-ui folder contains a script to launch a simple streamlit-based web UI. When deployed on a Kubernetes cluster, you can specify the IP address in the code to send requests to the server via API. Below are a few sample screens.
The type of request is selected via the Navigation menu:
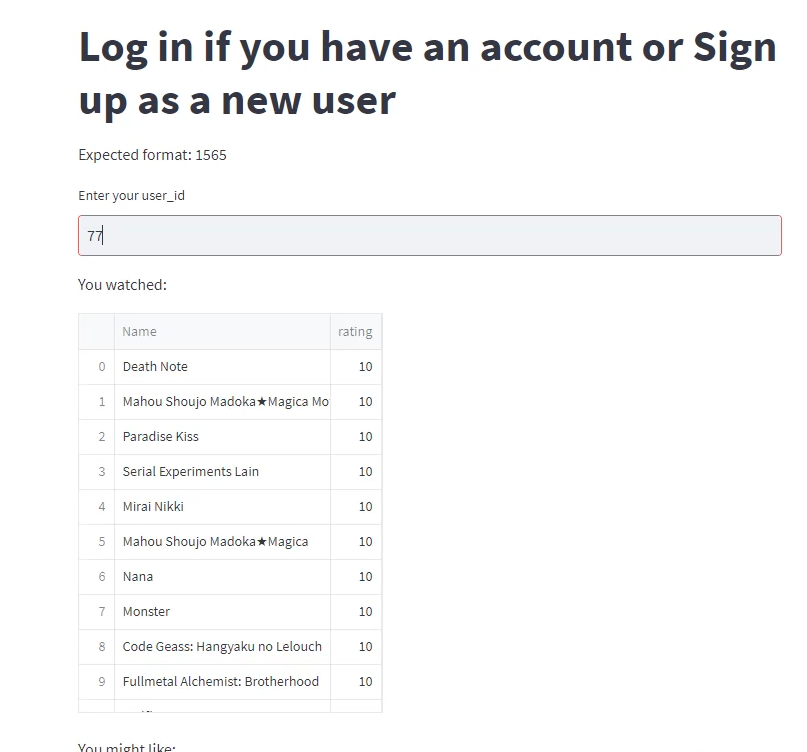
- Recommend anime for an existing user or new user without preferences:
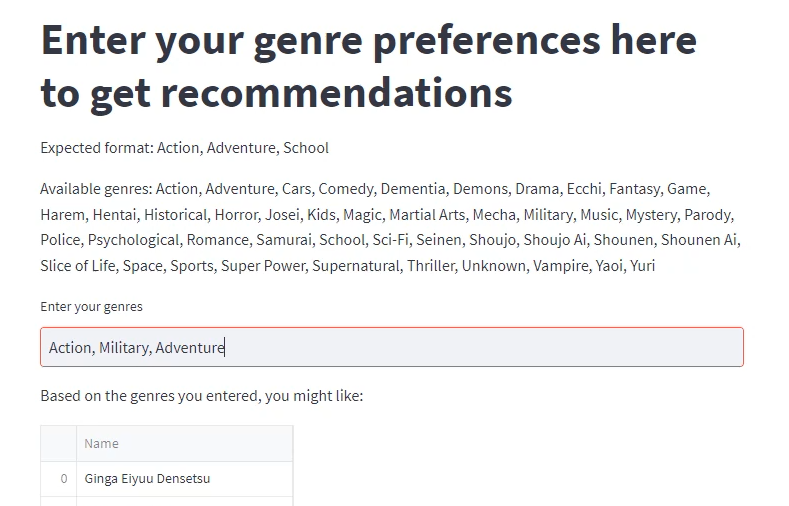
- Recommend anime for a new user with preferences:
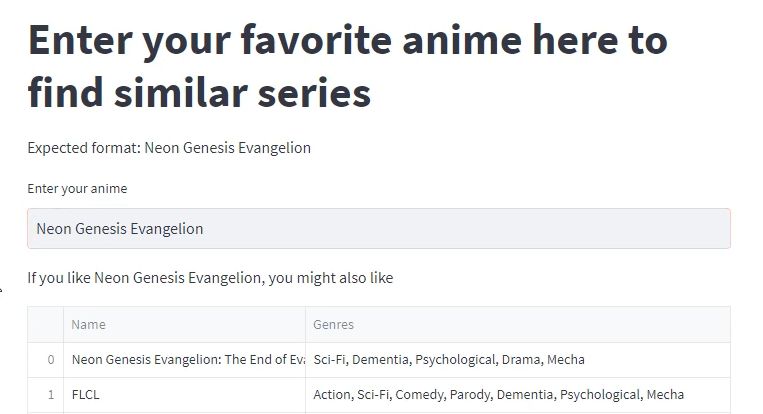
- Recommend similar anime:
The simulate-new-users folder contains .py and sh. scripts to simulate arrival of new users on a daily basis and write the data to PostgreSQL database. The process is automated using Airflow: https://github.com/horacemtb/Anime-recommender-engine/blob/main/airflow-dags/add_new_users.py
The retrain-model contains .py and sh. scripts to retrain a LightGBM regressor model on a weekly basis, considering that new users arrive daily. All the artifacts, including updated user data files and the pickled model, are logged via mlflow and saved to s3 storage. A t-test is performed to determine a possible statistically significant difference in the MAE metric on the test set. If there's no difference, the current prod model is overwritten with the new model and served to the Production stage via mlflow because it now knows more users. If the performances demonstrated by the two models are different and the new model performs better, it is also served to the Production stage. If the performances demonstrated by the two models are different and the new model performs worse, the current prod model is kept. After that an engineer can push the updated data and model to the GitHub repo and make a new release. Then they can restart the deployment on Kubernetes for the new image to be pulled and applied. The process is automated using Airflow: https://github.com/horacemtb/Anime-recommender-engine/blob/main/airflow-dags/retrain-model.py
This project makes an active use of Yandex Cloud services. Below is the architecture scheme.

The following infrastructure stack is used:
- Airflow to automate the simulate-new-users and retrain-model pipelines:
- PostgreSQL database to store user data:
- s3 storage to store anime data and log mlflow artifacts:

- mlflow to log the results of the retrain-model pipeline:
- Docker to serve the app as a container:
https://github.com/horacemtb/Anime-recommender-engine/blob/main/Dockerfile
- GitHub CI/CD pipeline to build a Docker image and push it to Dockerhub:
https://github.com/horacemtb/Anime-recommender-engine/blob/main/.github/workflows/docker-image.yml
- Kubernetes to deploy the My Otaku Friend service:

- Prometheus and Grafana stack to monitor the service, including a system of alerts: