Deep learning framewark를 이용하는 것이 아닌 Python numpy 모듈을 이용하여 모델을 구현
Arem data를 이용해 적절한 activation, optimizer등 여러 방법을 적용시켜 정확도를 높이는 프로젝트.
Numpy 1.18.2
AReM data
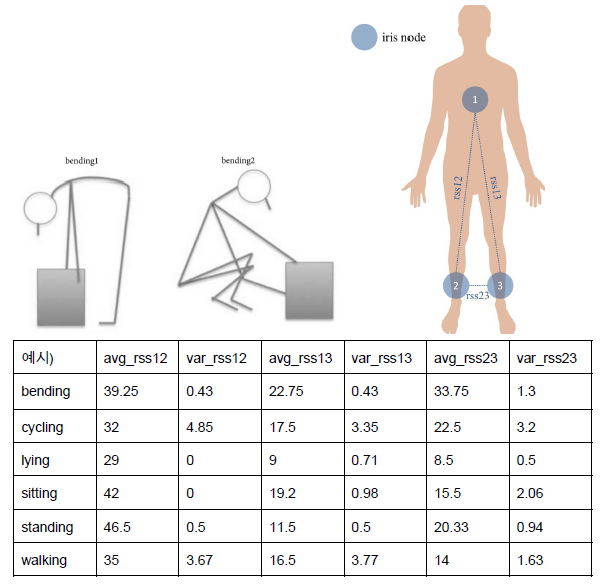
여섯가지 동작을 수행했을 때의 센서값의 평균과 분산을 나타낸다.
class별 갯수
-
walking : 4291
-
standing : 4301
-
sitting : 4311
-
lying : 4342
-
cycling : 4408
-
bending : 3402
Link: Activity Recognition system based on Multisensor data fusion (AReM) Data Set
model import
from model import *
-
Parameter
Model( <Learning rate> , <Number of Hidden Layer> , <Hidden_size> , <Activation> , <Dropout rate> ) <Scaled> , <Scale Info> )Number of Layer : Network의 Hidden Layer 수
Hidden_size : Hidden Layer의 노드수 (Python list 형태)
Activation : Activation function (default : Sigmoid)
Dropout rate : Dropout rate
Scaled : Scaling 유무 (type : Boolean ,default : False)
Scale Info : Scale시 사용한 mean, std 값
-
train
-
Without Scaling
train.py 163'th line
net = Model(lr, <Number of Hidden Layer> , <Hidden_size> , <Activation> , <Dropout rate> )Batch 단위로 scaling 수행
-
With Scaling
train.py 114~116 line (standard scaling)
data_mean = x_train.mean(axis=0) data_std = x_train.std(axis=0) x_train = (x_train-data_mean)/(data_std)train.py 163'th line
net = Model(lr, <Number of Hidden Layer> , <Hidden_size> , <Activation> , <Dropout rate> , scaled = True, scaler_info = [data_mean,data_std] )전체 data를 scaling 후 사용한 mean, std 를 이용하여 test data에 동일하게 적용
-