-
Notifications
You must be signed in to change notification settings - Fork 254
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Co-authored-by: Merve Noyan <merveenoyan@gmail.com> Co-authored-by: Omar Sanseviero <osanseviero@gmail.com>
- Loading branch information
3 people
authored
Nov 19, 2023
1 parent
c4dd775
commit ea92c74
Showing
82 changed files
with
5,791 additions
and
5 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,51 @@ | ||
| name: Tasks - Version and Release | ||
|
|
||
| on: | ||
| workflow_dispatch: | ||
| inputs: | ||
| newversion: | ||
| description: "Semantic Version Bump Type (major minor patch)" | ||
| default: patch | ||
|
|
||
| defaults: | ||
| run: | ||
| working-directory: packages/tasks | ||
|
|
||
| jobs: | ||
| version_and_release: | ||
| runs-on: ubuntu-latest | ||
| steps: | ||
| - uses: actions/checkout@v3 | ||
| with: | ||
| token: ${{ secrets.BOT_ACCESS_TOKEN }} | ||
| - run: corepack enable | ||
| - uses: actions/setup-node@v3 | ||
| with: | ||
| node-version: "18" | ||
| cache: "pnpm" | ||
| cache-dependency-path: | | ||
| packages/tasks/pnpm-lock.yaml | ||
| # setting a registry enables the NODE_AUTH_TOKEN env variable where we can set an npm token. REQUIRED | ||
| registry-url: "https://registry.npmjs.org" | ||
| - run: pnpm install | ||
| - run: git config --global user.name machineuser | ||
| - run: git config --global user.email infra+machineuser@huggingface.co | ||
| - run: | | ||
| PACKAGE_VERSION=$(node -p "require('./package.json').version") | ||
| BUMPED_VERSION=$(node -p "require('semver').inc('$PACKAGE_VERSION', '${{ github.event.inputs.newversion }}')") | ||
| # Update package.json with the new version | ||
| node -e "const fs = require('fs'); const package = JSON.parse(fs.readFileSync('./package.json')); package.version = '$BUMPED_VERSION'; fs.writeFileSync('./package.json', JSON.stringify(package, null, '\t') + '\n');" | ||
| git commit -m "🔖 @hugginface/tasks $BUMPED_VERSION" | ||
| git tag "tasks-v$BUMPED_VERSION" | ||
| - run: pnpm publish --no-git-checks . | ||
| env: | ||
| NODE_AUTH_TOKEN: ${{ secrets.NPM_TOKEN }} | ||
| - run: git push --follow-tags | ||
| # hack - reuse actions/setup-node@v3 just to set a new registry | ||
| - uses: actions/setup-node@v3 | ||
| with: | ||
| node-version: "18" | ||
| registry-url: "https://npm.pkg.github.com" | ||
| - run: pnpm publish --no-git-checks . | ||
| env: | ||
| NODE_AUTH_TOKEN: ${{ secrets.GITHUB_TOKEN }} |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -30,7 +30,7 @@ | |
| }, | ||
| "files": [ | ||
| "dist", | ||
| "index.ts", | ||
| "src", | ||
| "tsconfig.json" | ||
| ], | ||
| "keywords": [ | ||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,4 @@ | ||
| pnpm-lock.yaml | ||
| # In order to avoid code samples to have tabs, they don't display well on npm | ||
| README.md | ||
| dist |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,20 @@ | ||
| # Tasks | ||
|
|
||
| This package contains data used for https://huggingface.co/tasks. | ||
|
|
||
| ## Philosophy behind Tasks | ||
|
|
||
| The Task pages are made to lower the barrier of entry to understand a task that can be solved with machine learning and use or train a model to accomplish it. It's a collaborative documentation effort made to help out software developers, social scientists, or anyone with no background in machine learning that is interested in understanding how machine learning models can be used to solve a problem. | ||
|
|
||
| The task pages avoid jargon to let everyone understand the documentation, and if specific terminology is needed, it is explained on the most basic level possible. This is important to understand before contributing to Tasks: at the end of every task page, the user is expected to be able to find and pull a model from the Hub and use it on their data and see if it works for their use case to come up with a proof of concept. | ||
|
|
||
| ## How to Contribute | ||
| You can open a pull request to contribute a new documentation about a new task. Under `src` we have a folder for every task that contains two files, `about.md` and `data.ts`. `about.md` contains the markdown part of the page, use cases, resources and minimal code block to infer a model that belongs to the task. `data.ts` contains redirections to canonical models and datasets, metrics, the schema of the task and the information the inference widget needs. | ||
|
|
||
| 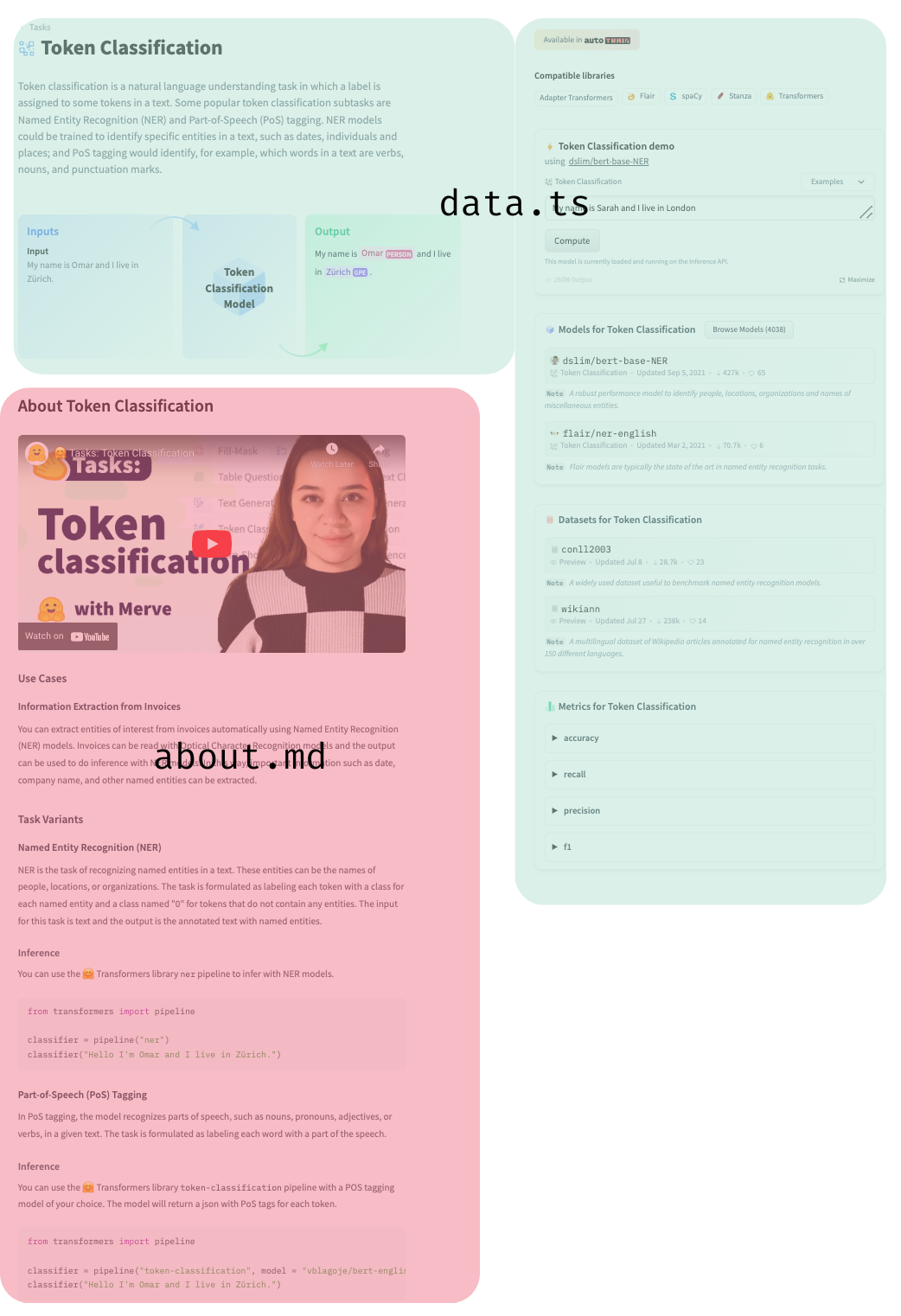 | ||
|
|
||
| We have a [`dataset`](https://huggingface.co/datasets/huggingfacejs/tasks) that contains data used in the inference widget. The last file is `const.ts`, which has the task to library mapping (e.g. spacy to token-classification) where you can add a library. They will look in the top right corner like below. | ||
|
|
||
|  | ||
|
|
||
| This might seem overwhelming, but you don't necessarily need to add all of these in one pull request or on your own, you can simply contribute one section. Feel free to ask for help whenever you need. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,45 @@ | ||
| { | ||
| "name": "@huggingface/tasks", | ||
| "packageManager": "pnpm@8.3.1", | ||
| "version": "0.0.3", | ||
| "description": "List of ISO-639 languages used in the Hub", | ||
| "repository": "https://github.com/huggingface/huggingface.js.git", | ||
| "publishConfig": { | ||
| "access": "public" | ||
| }, | ||
| "main": "./dist/index.js", | ||
| "module": "./dist/index.mjs", | ||
| "types": "./dist/index.d.ts", | ||
| "exports": { | ||
| ".": { | ||
| "types": "./dist/index.d.ts", | ||
| "require": "./dist/index.js", | ||
| "import": "./dist/index.mjs" | ||
| } | ||
| }, | ||
| "source": "src/index.ts", | ||
| "scripts": { | ||
| "lint": "eslint --quiet --fix --ext .cjs,.ts .", | ||
| "lint:check": "eslint --ext .cjs,.ts .", | ||
| "format": "prettier --write .", | ||
| "format:check": "prettier --check .", | ||
| "prepublishOnly": "pnpm run build", | ||
| "build": "tsup src/index.ts --format cjs,esm --clean --dts", | ||
| "type-check": "tsc" | ||
| }, | ||
| "files": [ | ||
| "dist", | ||
| "src", | ||
| "tsconfig.json" | ||
| ], | ||
| "keywords": [ | ||
| "huggingface", | ||
| "hub", | ||
| "languages" | ||
| ], | ||
| "author": "Hugging Face", | ||
| "license": "MIT", | ||
| "devDependencies": { | ||
| "typescript": "^5.0.4" | ||
| } | ||
| } |
Some generated files are not rendered by default. Learn more about how customized files appear on GitHub.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,64 @@ | ||
| import type { ModelLibraryKey } from "./modelLibraries"; | ||
| import type { PipelineType } from "./pipelines"; | ||
|
|
||
| export interface ExampleRepo { | ||
| description: string; | ||
| id: string; | ||
| } | ||
|
|
||
| export type TaskDemoEntry = | ||
| | { | ||
| filename: string; | ||
| type: "audio"; | ||
| } | ||
| | { | ||
| data: Array<{ | ||
| label: string; | ||
| score: number; | ||
| }>; | ||
| type: "chart"; | ||
| } | ||
| | { | ||
| filename: string; | ||
| type: "img"; | ||
| } | ||
| | { | ||
| table: string[][]; | ||
| type: "tabular"; | ||
| } | ||
| | { | ||
| content: string; | ||
| label: string; | ||
| type: "text"; | ||
| } | ||
| | { | ||
| text: string; | ||
| tokens: Array<{ | ||
| end: number; | ||
| start: number; | ||
| type: string; | ||
| }>; | ||
| type: "text-with-tokens"; | ||
| }; | ||
|
|
||
| export interface TaskDemo { | ||
| inputs: TaskDemoEntry[]; | ||
| outputs: TaskDemoEntry[]; | ||
| } | ||
|
|
||
| export interface TaskData { | ||
| datasets: ExampleRepo[]; | ||
| demo: TaskDemo; | ||
| id: PipelineType; | ||
| isPlaceholder?: boolean; | ||
| label: string; | ||
| libraries: ModelLibraryKey[]; | ||
| metrics: ExampleRepo[]; | ||
| models: ExampleRepo[]; | ||
| spaces: ExampleRepo[]; | ||
| summary: string; | ||
| widgetModels: string[]; | ||
| youtubeId?: string; | ||
| } | ||
|
|
||
| export type TaskDataCustom = Omit<TaskData, "id" | "label" | "libraries">; |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,85 @@ | ||
| ## Use Cases | ||
|
|
||
| ### Command Recognition | ||
|
|
||
| Command recognition or keyword spotting classifies utterances into a predefined set of commands. This is often done on-device for fast response time. | ||
|
|
||
| As an example, using the Google Speech Commands dataset, given an input, a model can classify which of the following commands the user is typing: | ||
|
|
||
| ``` | ||
| 'yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go', 'unknown', 'silence' | ||
| ``` | ||
|
|
||
| Speechbrain models can easily perform this task with just a couple of lines of code! | ||
|
|
||
| ```python | ||
| from speechbrain.pretrained import EncoderClassifier | ||
| model = EncoderClassifier.from_hparams( | ||
| "speechbrain/google_speech_command_xvector" | ||
| ) | ||
| model.classify_file("file.wav") | ||
| ``` | ||
|
|
||
| ### Language Identification | ||
|
|
||
| Datasets such as VoxLingua107 allow anyone to train language identification models for up to 107 languages! This can be extremely useful as a preprocessing step for other systems. Here's an example [model](https://huggingface.co/TalTechNLP/voxlingua107-epaca-tdnn)trained on VoxLingua107. | ||
|
|
||
| ### Emotion recognition | ||
|
|
||
| Emotion recognition is self explanatory. In addition to trying the widgets, you can use the Inference API to perform audio classification. Here is a simple example that uses a [HuBERT](https://huggingface.co/superb/hubert-large-superb-er) model fine-tuned for this task. | ||
|
|
||
| ```python | ||
| import json | ||
| import requests | ||
|
|
||
| headers = {"Authorization": f"Bearer {API_TOKEN}"} | ||
| API_URL = "https://api-inference.huggingface.co/models/superb/hubert-large-superb-er" | ||
|
|
||
| def query(filename): | ||
| with open(filename, "rb") as f: | ||
| data = f.read() | ||
| response = requests.request("POST", API_URL, headers=headers, data=data) | ||
| return json.loads(response.content.decode("utf-8")) | ||
|
|
||
| data = query("sample1.flac") | ||
| # [{'label': 'neu', 'score': 0.60}, | ||
| # {'label': 'hap', 'score': 0.20}, | ||
| # {'label': 'ang', 'score': 0.13}, | ||
| # {'label': 'sad', 'score': 0.07}] | ||
| ``` | ||
|
|
||
| You can use [huggingface.js](https://github.com/huggingface/huggingface.js) to infer with audio classification models on Hugging Face Hub. | ||
|
|
||
| ```javascript | ||
| import { HfInference } from "@huggingface/inference"; | ||
|
|
||
| const inference = new HfInference(HF_ACCESS_TOKEN); | ||
| await inference.audioClassification({ | ||
| data: await (await fetch("sample.flac")).blob(), | ||
| model: "facebook/mms-lid-126", | ||
| }); | ||
| ``` | ||
|
|
||
| ### Speaker Identification | ||
|
|
||
| Speaker Identification is classifying the audio of the person speaking. Speakers are usually predefined. You can try out this task with [this model](https://huggingface.co/superb/wav2vec2-base-superb-sid). A useful dataset for this task is VoxCeleb1. | ||
|
|
||
| ## Solving audio classification for your own data | ||
|
|
||
| We have some great news! You can do fine-tuning (transfer learning) to train a well-performing model without requiring as much data. Pretrained models such as Wav2Vec2 and HuBERT exist. [Facebook's Wav2Vec2 XLS-R model](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) is a large multilingual model trained on 128 languages and with 436K hours of speech. | ||
|
|
||
| ## Useful Resources | ||
|
|
||
| Would you like to learn more about the topic? Awesome! Here you can find some curated resources that you may find helpful! | ||
|
|
||
| ### Notebooks | ||
|
|
||
| - [PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/audio_classification.ipynb) | ||
|
|
||
| ### Scripts for training | ||
|
|
||
| - [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification) | ||
|
|
||
| ### Documentation | ||
|
|
||
| - [Audio classification task guide](https://huggingface.co/docs/transformers/tasks/audio_classification) |
Oops, something went wrong.