Align Your Prompts: Test-Time Prompting with Distribution Alignment for Zero-Shot Generalization [NeurIPS 2023]
Jameel Hassan *, Hanan Gani *, Noor Hussein, Uzair Khattak, Muzammal Naseer, Fahad Khan, Salman Khan
Official implementation of the paper "Align Your Prompts: Test-Time Prompting with Distribution Alignment for Zero-Shot Generalization".
- Updates
- Highlights
- Main Contributions
- Installation
- Datasets
- Run PromptAlign
- Results
- Citation
- Contact
- Acknowledgements
- Code for PrompAlign is released. [November 3, 2023]
- Our paper is accepted at NeurIPS 2023 [September 22, 2023]
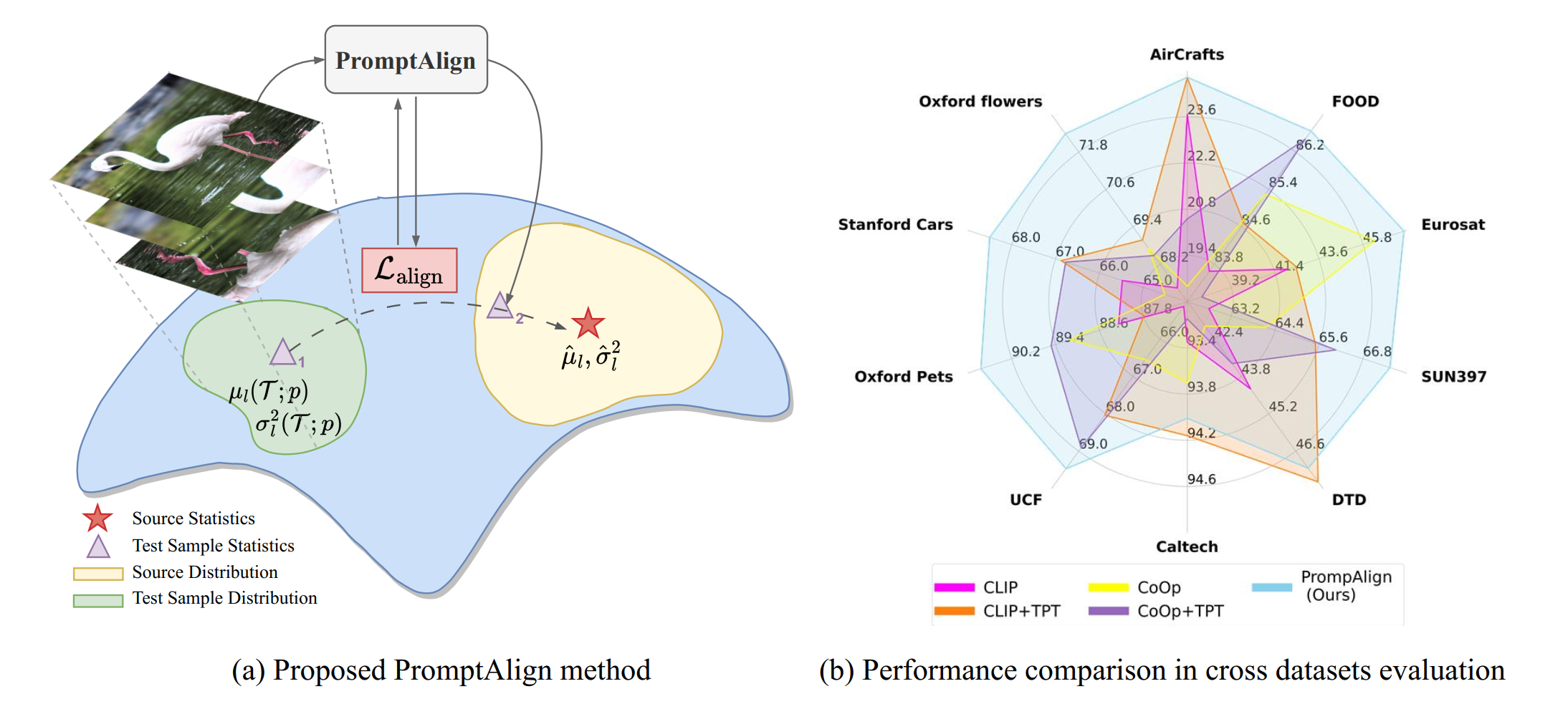
Abstract: The promising zero-shot generalization of vision-language models such as CLIP has led to their adoption using prompt learning for numerous downstream tasks. Previous works have shown test-time prompt tuning using entropy minimization to adapt text prompts for unseen domains. While effective, this overlooks the key cause for performance degradation to unseen domains – distribution shift. In this work, we explicitly handle this problem by aligning the out-of-distribution (OOD) test sample statistics to those of the source data using prompt tuning. We use a single test sample to adapt multi-modal prompts at test time by minimizing the feature distribution shift to bridge the gap in the test domain. Evaluating against the domain generalization benchmark, our method improves zero-shot top-1 accuracy beyond existing prompt-learning techniques, with a 3.08% improvement over the baseline MaPLe. In cross-dataset generalization with unseen categories across 10 datasets, our method improves by 1.82% compared to the existing state-of-the-art.
- Distribution alignment using a single sample: Given only a single test sample, we introduce a distribution alignment strategy for V-L models to improve test-time adaptation using lightweight prompt learning strategy.
- Offline statistics for distribution alignment: The proposed strategy formulates a distribution alignment loss that utilizes offline computed source data statistics to encourage the test sample token distributions to be aligned with the source data token distributions. This harmonically combines token distribution alignment with entropy minimization using multi-modal prompt learning.
- Proxy Source dataset: Since CLIP-pre-training data is not publicly released, we study the statistics of ImageNet as a possible candidate for the source distribution, and our empirical results show that ImageNet is an effective proxy source dataset for large-scale V-L models such as CLIP.
For installation and other package requirements, please follow the instructions detailed in INSTALL.md
Please follow the instructions at DATASETS.md to prepare all datasets.
Please refer to the RUN.md for detailed instructions on training, evaluating and reproducing the results using our pre-trained models.
| Method | IN-V2 | IN-Sketch | IN-A | IN-R | OOD Average |
|---|---|---|---|---|---|
| CLIP | 60.86 | 46.06 | 47.87 | 73.98 | 57.20 |
| CoOp | 64.20 | 47.99 | 49.71 | 75.21 | 59.28 |
| CoCoOp | 64.07 | 48.75 | 50.63 | 76.18 | 59.91 |
| MaPLe | 64.07 | 49.15 | 50.90 | 76.98 | 60.28 |
| TPT + CLIP | 64.35 | 47.94 | 54.77 | 77.06 | 60.81 |
| TPT + CoOp | 66.83 | 49.29 | 57.95 | 77.27 | 62.84 |
| TPT + CoCoOp | 64.85 | 48.27 | 58.47 | 78.65 | 62.61 |
| TPT + MaPLe | 64.87 | 48.16 | 58.08 | 78.12 | 62.31 |
| PromptAlign | 65.29 | 56.23 | 59.37 | 79.33 | 63.55 |
If you use our work, please consider citing:
@inproceedings{samadh2023align,
title={Align Your Prompts: Test-Time Prompting with Distribution Alignment for Zero-Shot Generalization},
author={Samadh, Jameel Hassan Abdul and Gani, Hanan and Hussein, Noor Hazim and Khattak, Muhammad Uzair and Naseer, Muzammal and Khan, Fahad and Khan, Salman},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
Should you have any questions, please create an issue in this repository or contact at jameel.hassan@mbzuai.ac.ae or hanan.ghani@mbzuai.ac.ae
We thank the authors of MaPLe, TPT, and CoOp and CoCoOp for their open-source implementation and instructions on data preparation.