A generative AI based smart information retrieval system featuring Hybrid Full-Text Search, enriched with contextual meaning and relevance ranking, making it suitable practical real life use cases.

The system is based on a hybrid search architecture that is able to understand the meaning of the search term and the user's intent for searching a particular keyword or phrase. As a result, it is able to produce results that are relevant to the particular user's need and personalised.
The architecture incorporates 1) Context 2) Semantic Meaning 3) Relevance at various points throughout the process, by utilizing graph database, contextual embeddings, vector database, Filtering Services and Large Language Model. This makes the system very adept at handling a diverse range of information retrieval requirements.
An LLM layer is used as a conversational agent , which is grounded using vector db to remove all of the tradional drawbacks of an LLM based IE system , i.e. incorrect Information, not being up-to-date and loss of information producing highly accurate results.
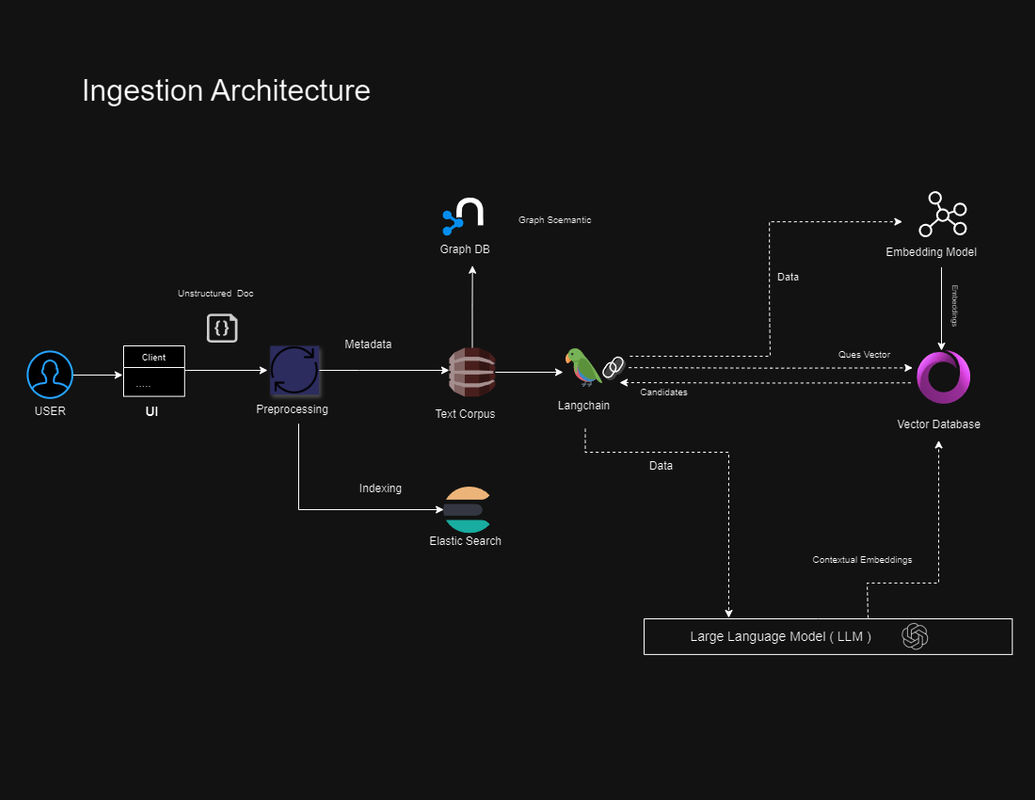
- A user enters a word, excel, pdf, text or custom data
- The pre-processing service cleans, organizes it into a document with the metadata and writes it into two data stores 1) document corpus & 2) Elastic-search - where it's indexed and used for keyword search
- Topic Models, Topic Distributions, NER and graph semantics are stored from the documents in a graph database
- The text is passed to an embedding model (bi-encoder), which then generates a embedding vector and stores it in the vector database ( knowledge base )

- Human asks a question in natural language via the UI
- A pre-filter service uses metadata to reduce the search space and also for pre-ranking of documents
- The question vector is passed to the vector DB, which returns the top-k most similar results, obtained via an ANN search. This step massively narrows down the search space for the LLM, used in the next step
- An LLM prompt is constructed, converted to an embedding, and passed to the it. The LLM searches the top-k results for the information using the context provided, and produces an answer to the question that makes the semantic similarity accounted for in the result
- A LangChain agent is used to provide generative QA chat interfaces by making composable workflows that adapt dynamically at runtime. This makes it very convenient, as the prompt can be dynamically constructed with the LLM’s native embedding module. It also acts as orchestrator between vector db , embedding model and the llm
- A keyword search through fast index lookup is performed on the elasticsearch collection, which returns exact or most likely matches
- Both the candidates are are combined by a cross-encoder service that classifies a pair of sentences by assigning them a score between 0 and 1, via a softmax layer. This is termed re-ranking, and is a very powerful approach to obtaining results that combine the best of both worlds (keyword + vector search)
- Additional context is added by graph semantic search and Topic Distributions which help to provide more relevant results and also recommendations of similar topics & documents
- The answer is sent back to the human

Because vector DBs store the data to be queried as embeddings, and the LLM also encodes the knowledge within it as embeddings, they are a natural pairing when it comes to generative QA applications. The vector DB functions as a knowledge base, and the LLM can query a subset of the data directly in the embedding space. Further, because question-answering can involve more than just information retrieval (it may require parts of the data to be analyzed, not just queried), including an agent-based framework like LangChain in between the application UI and the vector DB can be effective and useful to retrieve relavant results.
- Similarity Search
- Keyword baased Semantic Search
- Topic Modelling
- Contextual Embeddings
- Knowledge Graphs / Semantic Graph Search
- Personalized Search ( Session )
- Conversational
- Indexing
- Tokenization
- Embeddings
- Document Ranking
- Vector DB
- RAG
- LLMs
https://github.com/kaustav202/search-genie/blob/master/related-concepts.md