Several machine learning and deep learning methods were developed to classify texts in Korean involved with 'voice phishing' [1][2]. This fork is derived from the original repository organized as below:
- Attention : contains source codes for investigating the performance of an attention-based detection model compared to others such as CNN-BiSLTM, BiLSTM, LSTM, and CNN models.
- Data_Collection_Preprocessing : contains source codes for preprocessing raw data and create the datasets.
- KoBERT : contains a source code and a related dataset for implementing a pretrained KoBERT based model.
- ML_DL_models : contains source codes for implementing a shadow(?) ML and DL models
- 2,927 entries of texts transcribed from the actual phone conversation resulting in a transcript dataset called KorCCVi (or KorCCViD)
- 2,232 entries from non fraudulent call texts whose topics range from travel, food, movies, pet care, etc. Just ordinary daily conversation but rather long (repsonses and length data not shown).
- 695 entries from supposedly fraudulent call texts whose topics range from calls about illegal or criminal financial transactions, bank loans, suspected involvement of criminal activities etc.
- No special characters were present in the transcripts but some duplicates were removed. Non fraudulent 2,232 vs. Fraudulent 692 transcripts
- Preprocessed to remove stop words such as ["을", "를", "이", "가", "은", "는", "ㅡ", "의", "에","에서", "로", "으로", "에요", "예요", "으시","XXX", "xxx"], extra characters, etc (more detailed description may be needed).
- From the fraudulent transcripts, 42,415 counts of unique vocabulary and 222,943 counts of words were prepared.
- From the non fraudulent transcripts, 255,394 counts of unique vocabulary counts and 3,453,048 counts of words were prepared.
The model has been implemented in a script named 'Att-Based CNN-BiLSTM for Detecting Korean Vishing.ipynb' available at https://github.com/selfcontrol7/Korean_Voice_Phishing_Detection/tree/main/Attention (the original repository created by the first author[1][2])
Several minor things to mind before a fully blown execution of the script:
-
Two text input files are required (that are NOT provided at the repo: One contains non vishing tokens and the other contains vishing tokens.
For this step, outfile_space_20230117.npz needs to be loaded and is available at https://github.com/kimdesok/Korean_Voice_Phishing_Detection/tree/main/Attention. -
To evaluate the performance of a trained model, the model needs to be (re)compiled just before 'model.evaluate()' command.
model = load_model(model_path, custom_objects=create_custom_objects())
model.compile(loss = "categorical_crossentropy", optimizer = Adam(learning_rate=learning_rate, decay=learning_decay), metrics = ['accuracy'])
model.evaluate(X_test, y_test)
- Tensorflow version 2.4 and python 3.7 were installed (See the updated 'requirement.txt' for more installation).
The figures below show the loss, accuracy, and the classification report of the attention based CNN-BiLSTM model. Training, validation, test sets were divided into 6.4:1.6:2. The training was performed by having epochs and patience set by 50 and 20, respectively.
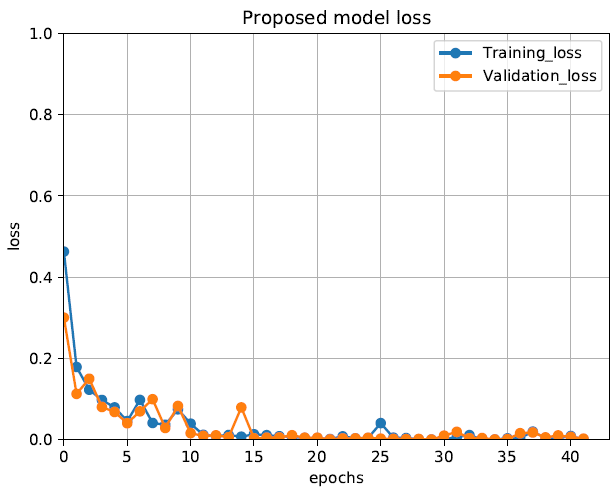
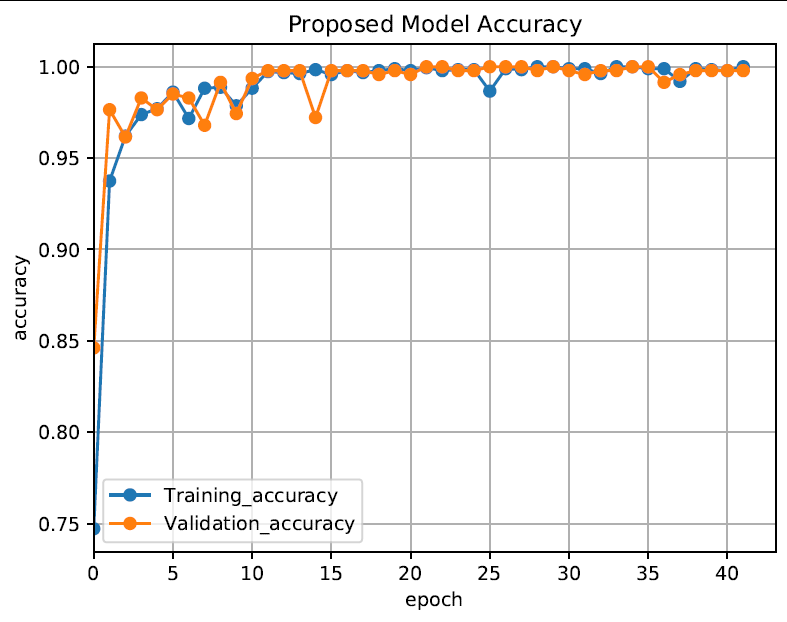
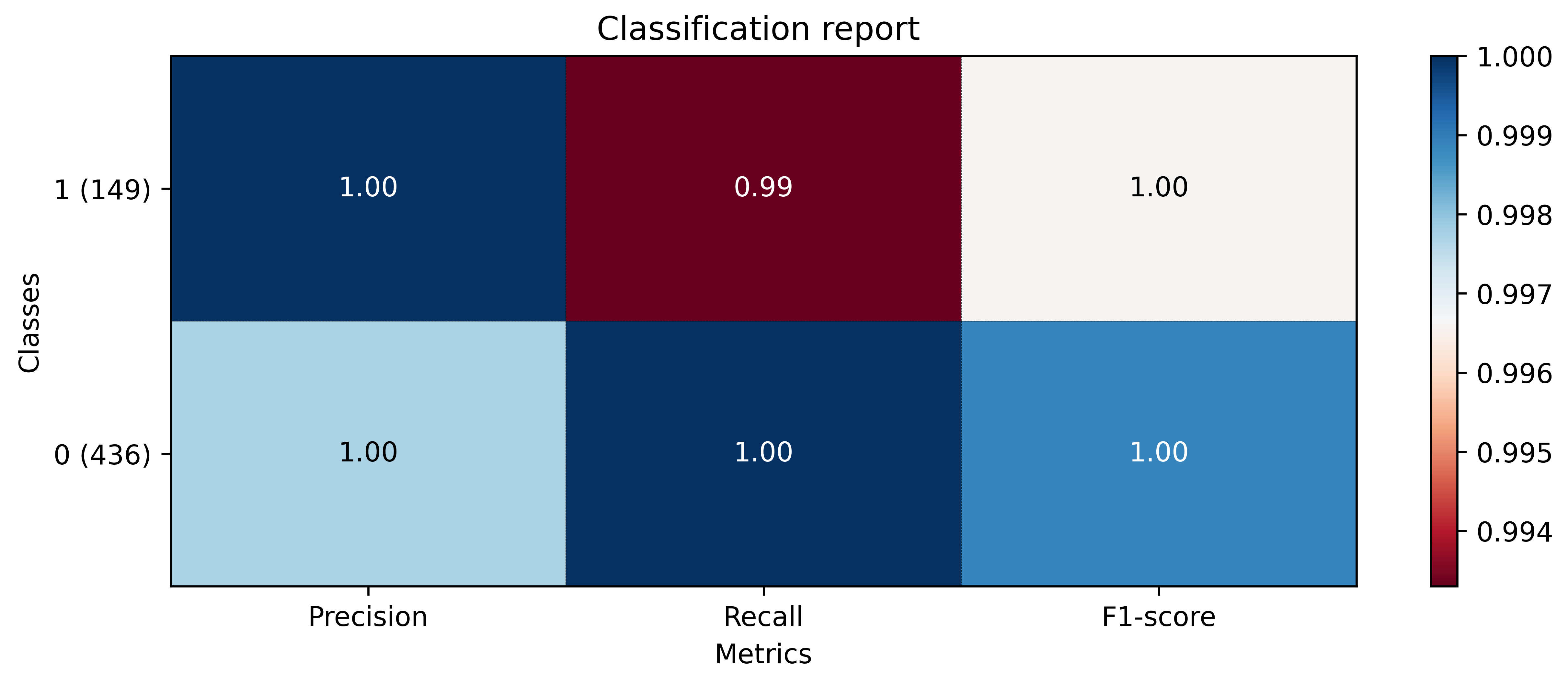
To compare the performance of the attention based model to other models such as CNN-BiLSTM, CNN, BiLSTM, and LSTM. By training and testing the rest of the methods, a performance comparison table could be prepared:
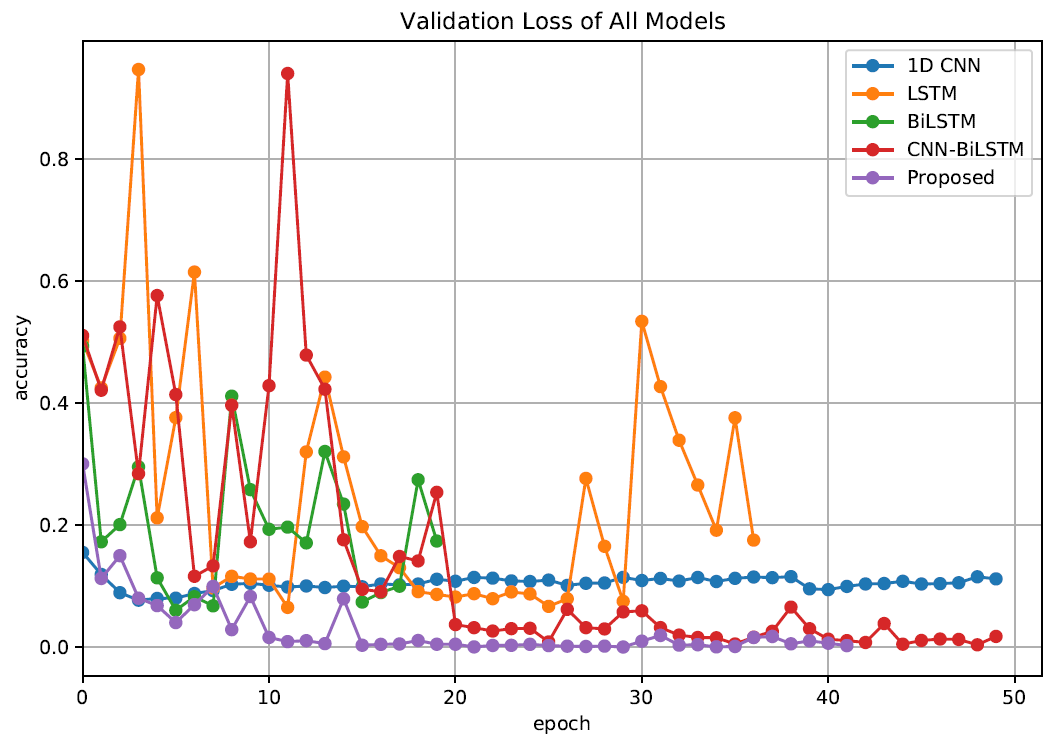

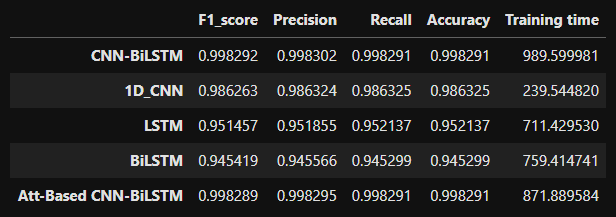
The proposed attention based CNN-BiLSTM model and CNN-BiLSTM resulted in the same accuracy but the former converged slightly faster. CNN-BiLSTM seems to fluctuate a quite bit at the beginning of training in terms of accuracy and loss but eventually converged at about 25 epochs.
Later on CNN, BiLSTM, and LSTM....
-Dataset used: KorCCViDv1.3_fullcleansed.csv
-Train:Validation:Test ratio set to 0.64:0.16:0.2
-Epochs of 20, learning rate of 0.00001, batch size of 32, max_len = 64
-Performance metrics at training at test
acc 0.9955 0.9961
recall 0.9892 1.0000
precision 1.0000 0.9914
f1 0.9946 0.9957
- Inference time per transcript less than 10 ms.
- Open an account at Google Cloud
- Create a project
- Create a bucket (named 'example-bucket-for-audio2texts' in this case)
- Create a billing and link that to the project
- Give IAM a role for 'Storage Admin' or something equivalent.
- Enable the Cloud Speech-to-Text API for the project
- At the terminal, execute 'gcloud auth application-default login' and enter the key (by following the procedure).
- Edit gcloud.ini as below:
[CREDENTIALS]
BUCKET_NAME = example-bucket-for-audio2texts
JSON = /home/ubuntu/.config/gcloud/application_default_credentials.json
- Run 'transcribe_audio.py' available in the repository 'Data_Collection_Preprocessing'
https://drive.google.com/file/d/1LjYVrZwafKPAxwUElChQmM9_YyawpUo3/view?usp=share_link
"Confidence: 0.8026149868965149 이은경 vacation 무엇입니까? 가방입니다. 학생이니까네 학생입니다 누구예요 친구예요 고향이 어디예요?"
https://drive.google.com/file/d/1v238dOzTYk1icx5nGOUWW3aItODAoBBk/view?usp=share_link
"Confidence: 0.8690810799598694 두 개가 의자 위에 있어요. 개가 의자 위에 있습니다. 우리 집이 신촌에 있어요. 우리 집이 신촌에 있습니다. 남자 친구가 있어요 남자 친구가 있으니 야."
[1] M. K. M. Boussougou, S. Jin, D. Chang, and D.-J. Park, “Korean Voice Phishing Text Classification Performance Analysis Using Machine Learning Techniques,” Proceedings of the Korea Information Processing Society Conference, pp. 297–299, Nov. 2021.
[2] M. K. M. Boussougou and D.-J. Park, “Exploiting Korean Language Model to Improve Korean Voice Phishing Detection,” KIPS Transactions on Software and Data Engineering, vol. 11, no. 10, pp. 437–446, Oct. 2022.