Substitution cipher tool - Gui program (javaFx)
치환 암호 해석을 도와주는 프로그램
단어와 알파벳의 빈도수를 제공해주고 지정한 알파펫을 다른 알파벳으로 치환하면 암호문에서 해당 알파벳의 치환 결과를 보여준다.
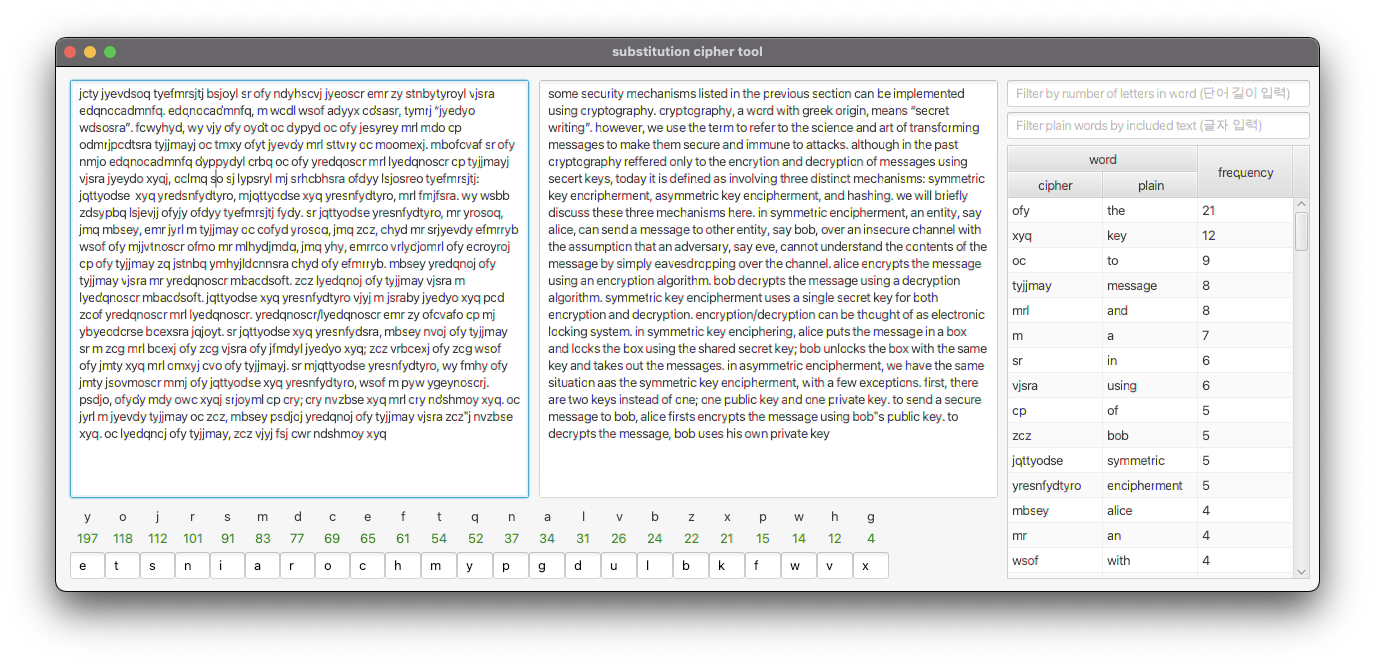
단어 빈도수의 정보는 해당 링크로 남겨두겠다. (https://www.wordfrequency.info/free.asp?s=y&fbclid=IwAR26zG455Kygsb5YQZYl3JsnI9eylgLhTgPlkzb3lIYOiqt-0k3juIafRLs)
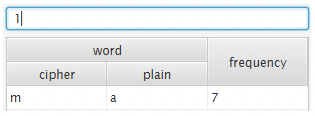
o = t, f = h, y = e 이다.
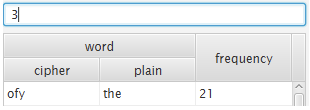
3. the를 찾았기 때문에 to 나 of 그리고 the로 시작하는 단어를 찾는다. (ex : there, they 등). 영어 단어 빈도수 중에서 to의 빈도수가 높기 oc가 to라고 유추할 수 있다. 이후 cp의 빈도수도 높기 때문에 cp도 of라고 유추할 수 있다.
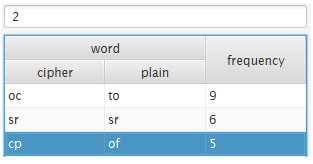
이후 the와 유사한 단어를 찾아보면 ofyt, ofydy, ofdyy, ofyjy가 있다. 먼저 ofydy와 ofdyy를 보면 the_e, th_ee이므로 d는 r을 유추할 수 있다. 그리고 ofyjy는 these이므로 j는 s을 유추할 수 있다.

ofyt는 the_이므로 t는 n, m, y가 올 수 있기 때문에 나중에 다시 보겠다.

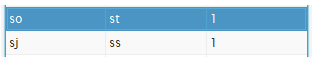
_t 와 _s로 끝나는 단어는 it와 is라는 것을 유추 할 수 있으며 현재 암호문에서 s의 빈도수가 높다. 알파벳에서 i의 빈도수 또한 높기 때문에 s가 i라고 유추 할 수 있다.
we vse the 다른 문장을 보고 v는 u라는 것을 알 수 있다.
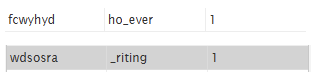
fcwyhyd가 howehed인것을 보고 however인 것을 알 수 있다.

맨 첫 단어 jcty는 so_e이므로 some, 즉 t는 m이라는 것을 알 수 있다.
some 다음 단어인 jyevdsoq 는 se_uritq, security이므로 e = c, q = y, v = u

이후 zy와 zq을 보고 _e, _y이므로 z가 b인 것을 알 수 있다.

vjsra 는 usin_ 이다. a 는 g라는 것을 유추 할 수 있다.

oclmq는 to_ay이다. l 은 d라는 것을 유추 할 수 있다.

jqjoyt는 syste_이다. t는 m이라는 것을 유추 할 수 있다.

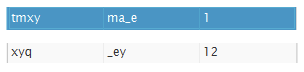
tmxy가 ma_e이고 xyq가 _ey이다. x가 k라는 것을 유추 할 수 있다.
efmrryb는 channe_이다. b가 l이라는 것을 유추 할 수 있다.

fcwyhyd가 ho_ever이고 wdsosra가 _riting이므로 w는 w라는 것을 유추 할 수 있다.
nvzbse가 _ublic이고 ndshmoy가 _rivate이므로 n는 p라는 것을 유추 할 수 있다.

ygeynoscrj가 e_ceptions이므로 g는 x라는것을 유추 할 수 있다.

위 과정을 모두 수행하면

해당 하는 키를 찾을 수 있다.