The motivation behind this project is to reduce question duplicates on knowledge-sharing platforms like Stackoverflow, Google, Quora and Reddit.
Duplicate questions negatively affects user experience as discussion for the same question is segmented into different posts. Hence, the aim of our project is to minimise the duplicated (False Positive) instances within the dataset.
Machine Learning Techniques:
- Exploratory Data Analysis
- Feature Engineering
- Support Vector Machine
- Logistic Regression
- Random Forest Classifier
- XGBoost
- Recurrent Neural Networks (RNN)
- Siamese Recurrent Neural Networks (Siamese RNN)
- Natural Language Processing (NLP)
| Models | F1 | Recall | Precision | Accuracy |
|---|---|---|---|---|
| SVM | 69.0% | 90.3% | 55.9% | 70.2% |
| Logistic Regression | 53.6% | 50.0% | 57.6% | 68.0% |
| RFC | 66.0% | 76.0% | 58.0% | 71.0% |
| XGBoost | 70.8% | 86.7% | 59.7% | 73.7% |
| RNN | 77.0% | 78.1% | 75.9% | 82.8% |
| Siamese RNN | 77.0% (+0.034) | 78.1% (+0.061) | 75.9% (+0.008) | 82.8% (+0.019) |
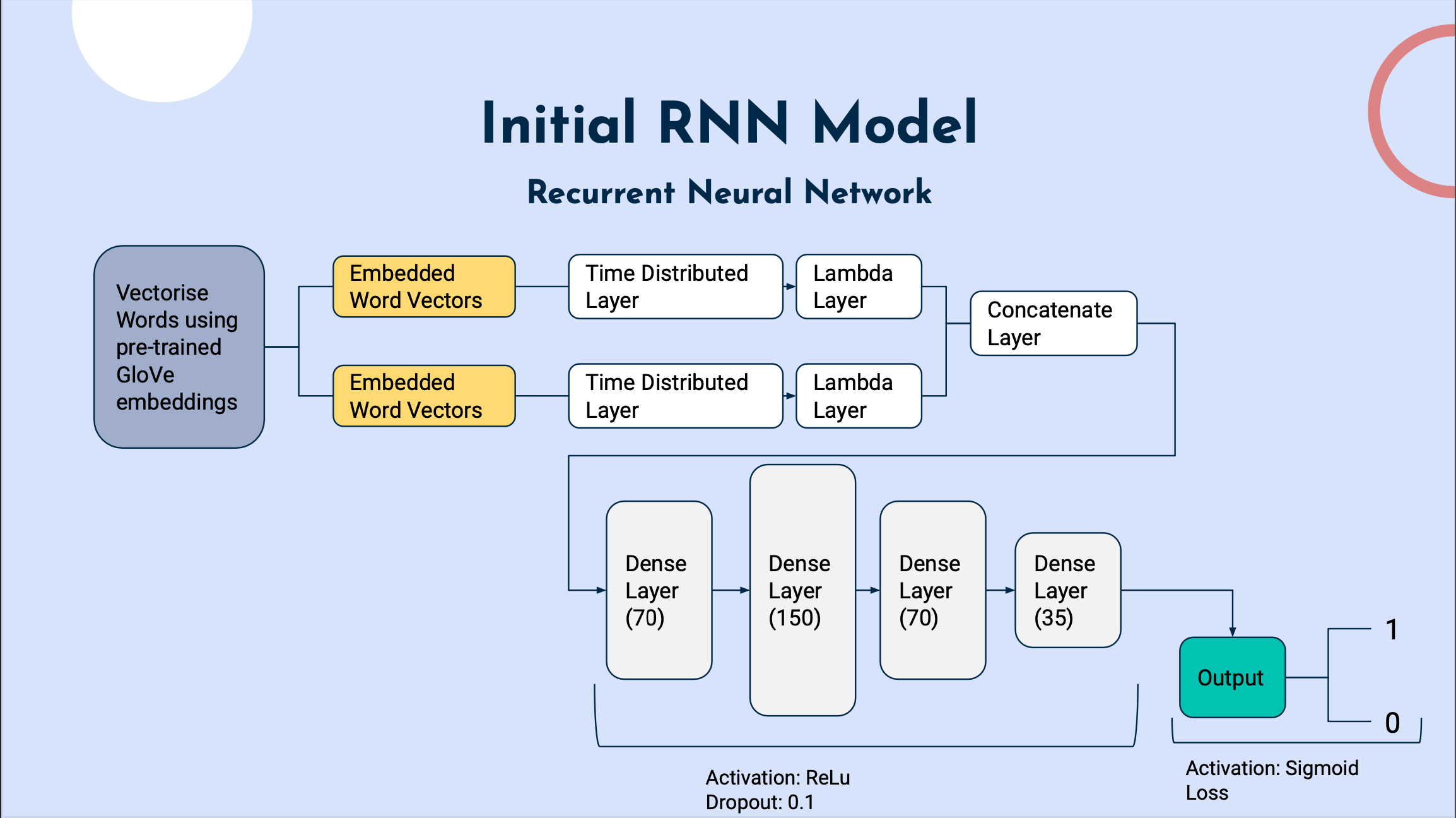
Even though the improvements were minor, we regarded it as significant due to the large dataset it was trained over (~400,000 rows). Hence, the final model chosen was the Siamese Recurrent Neural Networks with Engineered Features.
- Cheong Siu Hong
- https://keras.io/api/
- https://towardsdatascience.com/quora-question-pairs-similarity-tackling-a-real-life-nlp-problem-ab55c5da2e84
- https://towardsdatascience.com/dont-overfit-how-to-prevent-overfitting-in-your-deep-learning-models-63274e552323
- https://machinelearningmastery.com/diagnose-overfitting-underfitting-lstm-models/ https://github.com/bradleypallen/keras-quora-question-pairs
- https://blog.mlreview.com/implementing-malstm-on-kaggles-quora-question-pairs-competition-8b31b0b16a07
- https://github.com/MikeXydas/SiameseLSTM
- https://stackabuse.com/python-for-nlp-creating-multi-data-type-classification-models-with-keras/#creatingamodelwithmultipleinputs
- https://mlwhiz.com/blog/2019/02/08/deeplearning_nlp_conventional_methods/ https://machinelearningmastery.com/avoid-overfitting-by-early-stopping-with-xgboost-in-python/
- https://kevinvecmanis.io/machine%20learning/hyperparameter%20tuning/dataviz/python/2019/05/11/XGBoost-Tuning-Visual-Guide.html
- https://blog.cambridgespark.com/hyperparameter-tuning-in-xgboost-4ff9100a3b2f
- https://towardsdatascience.com/fine-tuning-xgboost-in-python-like-a-boss-b4543ed8b1e
- https://towardsdatascience.com/xgboost-fine-tune-and-optimize-your-model-23d996fab663
- https://www.vebuso.com/2020/03/svm-hyperparameter-tuning-using-gridsearchcv/
- https://towardsdatascience.com/an-implementation-and-explanation-of-the-random-forest-in-python-77bf308a9b76
- https://www.vox.com/recode/2019/5/16/18627157/quora-value-billion-question-answer
- https://www.vox.com/recode/2019/5/16/18627157/quora-value-billion-question-answer
- https://stackoverflow.blog/2019/01/18/state-of-the-stack-2019-a-year-in-review/
- https://www.theverge.com/2020/12/1/21754984/reddit-dau-daily-users-revealed
- https://www.kaggle.com/c/quora-question-pairs/discussion/34355
- https://arxiv.org/abs/1606.01933
- https://github.com/ashwin4glory/Quora-Question-Pair-Similarity/blob/master/4.ML_models.ipynb
- https://blog.mlreview.com/implementing-malstm-on-kaggles-quora-question-pairs-competition-8b31b0b16a07
- https://arxiv.org/abs/1908.10084
- https://towardsdatascience.com/boosting-in-machine-learning-and-the-implementation-of-xgboost-in-python-fb5365e9f2a0