基于海明距离的相似图像识别 #63
基于海明距离的相似图像识别 #63
Conversation
|
|
https://tieba.baidu.com/p/6144593813 |
|
jpeg压缩一下就发现一堆像素数值都变了,或者说只要全部像素的值+1,就会让这个方法也完全失效。 如果只是判断两张图的相似度高不高的话,用SSIM确实是好办法。 |
您是说aiotibea用的这个phash算法无法对抗jpeg压缩(以及其带来的经典8x8px marcoblock artifact)? |
|
需要实际测试看看 |
|
土澳数据科学家文科生转应用统计学带手子cn神名人名言:
http://www.xinhuanet.com/politics/2018-06/28/c_1123047504.htm 进一步指出:
而 http://dangjian.people.com.cn/n1/2018/0613/c117092-30054206.html 早已道明:
http://www.nopss.gov.cn/GB/230165/243957/17977176.html 对此也有所预言:
|
|
我现在浑身酸痛,等26号我再来处理 |
#py版贴吧管理器皇帝圣starry神将于耶稣降生日后一天复活
圣starry神的降生,早在几百小时前就有
|
图片在贴吧图床的40位16进制编号,代码里叫raw_hash |
https://github.com/Starry-OvO/aiotieba/blob/bce0d8d04d05a4dbf7759581c244a8341d97f9ca/aiotieba/client.py#L2966 回顾经典之 我想我会叫他
在userscript maxurl中可以找到更多的域: https://raw.githubusercontent.com/qsniyg/maxurl/master/src/userscript.ts (ctrl+f搜索
|



curl 'https://tiebapic.baidu.com/forum/w%3D580/sign=85a89eefd816fdfad86cc6e6848e8cea/64380cd7912397dd491993c01c82b2b7d1a28796.jpg?tbpicau=2022-12-25-05_d5f6950a598068243dbbab4e7fa8c5c3' \
-H 'Referer: https://tieba.baidu.com/' \
-H 'User-Agent: Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' | identify -
curl 'https://imgsrc.baidu.com/forum/w%3D580/sign=85a89eefd816fdfad86cc6e6848e8cea/64380cd7912397dd491993c01c82b2b7d1a28796.jpg?tbpicau=2022-12-25-05_d5f6950a598068243dbbab4e7fa8c5c3' \
-H 'Referer: https://tieba.baidu.com/' \
-H 'User-Agent: Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' | identify -同样是图片缩略处理服务endpoint,imgsrc域不会验证sign参数值是否有效(对于每个图片文件名贴吧客户端返回图片处理服务url中的sign值是相同的,因此可以假定sign参数值与图片文件名满射),而tiebapic域会验证 两个域目前都不会对任何http request header进行验证,因此删掉referer和ua header也无妨: parallel "curl -s -w '%{stderr}%{time_total}s\n' 'https://{}.baidu.com/forum/w%3D580/sign=e4aee93e3ecb0a4685228b315b62f63e/4ba6b7fd5266d016e17995ecd22bd40734fa350b.jpg' | identify -" ::: imgsrc tiebapic
parallel "curl -s -w '%{stderr}%{time_total}s\n' 'https://{}.baidu.com/forum/pic/item/4ba6b7fd5266d016e17995ecd22bd40734fa350b.jpg?tbpicau=2022-12-25-05_2ae0f8dbe307e91d5228fb7b90bdc060' | identify -" ::: imgsrc tiebapic
parallel "curl -s -w '%{stderr}%{time_total}s\n' 'https://{}.baidu.com/forum/pic/item/4ba6b7fd5266d016e17995ecd22bd40734fa350b.jpg' | identify -" ::: imgsrc tiebapicimgsrc域必须不能提供tbpicau参数(除非访问的是图片处理服务而非原图endpoint),tiebapic域对于两个endpoint都必须提供 parallel "curl -s -w '%{stderr}%{time_total}s\n' 'https://{}.baidu.com/forum/w%3D580/sign=e4aee93e3ecb0a4685228b315b62f63e/4ba6b7fd5266d016e17995ecd22bd40734fa350b.jpg?tbpicau=2022-12-25-05_2ae0f8dbe307e91d5228fb7b90bdc060' | md5sum" ::: imgsrc tiebapic
parallel "curl -s -w '%{stderr}%{time_total}s\n' 'https://{}.baidu.com/forum/w%3D580/sign=e4aee93e3ecb0a4685228b315b62f63e/4ba6b7fd5266d016e17995ecd22bd40734fa350b.jpg?tbpicau=2022-12-25-05_2ae0f8dbe307e91d5228fb7b90bdc060' | identify -" ::: imgsrc tiebapicimgsrc域和tiebapic域对于图片处理服务返回的图片文件hash都是一致的 curl -s -w '%{stderr}%{time_total}s\n' 'https://tiebapic.baidu.com/forum/pic/item/4ba6b7fd5266d016e17995ecd22bd40734fa350b.jpg?tbpicau=2022-12-25-05_2ae0f8dbe307e91d5228fb7b90bdc060' | identify -
curl -s -w '%{stderr}%{time_total}s\n' 'https://tiebapic.baidu.com/forum/pic/item/4ba6b7fd5266d016e17995ecd22bd40734fa350b.jpg' | identify -tiebapic域目前无法返回原图,不论是否提供了tbpicau 最后两个域所部署cdn节点也不同,从上述截图中的curl输出的 |







|
@n0099 在 #63 (comment) 中您 mention 到我了。请不要无端 mention 我,也请不要将一些我从未说过也不了解的言论署名给我。 |
|
不知道这个所谓的贴吧phash的对于图片的不变性是否稳定。简单的说,就是如果一个图片进行缩放,旋转,或者是改变亮度,对比度,颜色,这个phash能否保持相似。 如果发现phash不适合做这个,那就只能去另找别的方法去表示图片了。 |
是本repo aiotieba这个py库所使用的phash算法实现,我没去彻查到底是哪个实现
什么线代 |
前面有提到,“细微差异”的图片的 phash 也会接近(“接近”表现为更可能有比较多的 bit 是相等的,具有比较短的海明距离)。不知道这个 细微差异 包括哪些差异,是否包括 缩放,旋转,或者是改变亮度,对比度,颜色 。这些全都取决于这个 phash 算法本身的设计。通用哈希算法是不会(而且要有意避免)表现出“相似的输入产生相似的输出”的特性的,只有专为匹配相似信息设计的哈希算法才会有这样的特性,而且 哈希值以何种形式相似 也是跟哈希算法本身的设计相耦合的。 比对图片像素本身的海明距离应该是一种很差的判断相似图片的方式——有理由相信只能检测水印,对于上面说的几种变换应该全都不适用。但本pr说的是比对 phash 的海明距离。只有出于 相似比对 的目的有意设计出的哈希算法会表现出相似的输入对应海明距离较短的输出的特性。那么至于 对原图片的到底哪些变换,不会让 phash 具有不短的海明距离,还是取决于这个 phash 算法的设计。 |
|
phash当然是指perceptual hashing,除非starry神只是借用了这个词来描述某个他亲自指挥亲自部署亲自设计亲自研发的神必算法,但问题是phash本身也只是对一系列具有相似特征的hash算法设计的笼统统称
enwiki早已指出: TL;DR:截止2022年12月24号,我们仍未能知晓圣starry神在py库aiotieba中所使用的phash算法具体是什么,我怀疑本质就是调opencv的某个函数 |
所以这个算法不是百度选的,而是本项目作者选的吗? |
百度没有hash: #63 (comment)
#63 (comment) 早已指出:
|
| @@ -558,7 +558,7 @@ async def _create_table_imghash(self) -> None: | |||
| async with conn.cursor() as cursor: | |||
| await cursor.execute( | |||
| f"CREATE TABLE IF NOT EXISTS `imghash_{self.fname}` \ | |||
| (`img_hash` CHAR(16) PRIMARY KEY, `raw_hash` CHAR(40) UNIQUE NOT NULL, `permission` TINYINT NOT NULL DEFAULT 0, `note` VARCHAR(64) NOT NULL DEFAULT '', `record_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, \ | |||
| (`img_hash` CHAR(16) PRIMARY KEY, `img_hash_uint64` BIGINT UNSIGNED UNIQUE NOT NULL, `raw_hash` CHAR(40) UNIQUE NOT NULL, `permission` TINYINT NOT NULL DEFAULT 0, `note` VARCHAR(64) NOT NULL DEFAULT '', `record_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, \ | |||
There was a problem hiding this comment.
使用定长blob(max_length_of_phash)或定长uint16/32/64存储bytes array不是常识?
只有前端给用户看的bytes才需要给他看bin2hex后的字符串
|
刚刚merge好像出现了一些状况,commit已经能看到了但merge又没成功? |
1b7c732 本pr现状: 我的建议是:立即在branch |

| ) | ||
| if hamming_distance > 0: | ||
| await cursor.execute( | ||
| f"SELECT `permission`, BIT_COUNT(`img_hash_uint64` ^ CONV(%s,16,10)) AS hd FROM `imghash_{self.fname}` HAVING hd <= %s ORDER BY hd ASC", (img_hash, hamming_distance) |
There was a problem hiding this comment.
so人对性能问题早有预言: 而在菲利普·欧布雷丹对此answer的comment中指向的另一个so question的answer中 https://stackoverflow.com/questions/9606492/hamming-distance-similarity-searches-in-a-database/47487949#47487949 进一步指出:
|
好聪明! |
|
在 #63 (comment) 中引用的 https://stackoverflow.com/a/21058895 指出对于两个二进制(或者说byte array)输入a和b, 重新回顾xor与or运算的真值表: 这说明了 |


对逻辑和/或语言学不感兴趣的请跳过本comment请注意尽量不要使用自然语言中的 https://en.wiktionary.org/wiki/soit#Conjunction_2 中的给出的例子:
而如果您省略了不定冠词并使用中文的
如果使用英文
当然对于这个句子的语义更合理的表达是
enwiki对此也早有总结: https://en.wikipedia.org/wiki/Exclusive_or#Exclusive_or_in_natural_language https://en.wikipedia.org/wiki/Logical_disjunction#Natural_language
您也可以使用 |


|
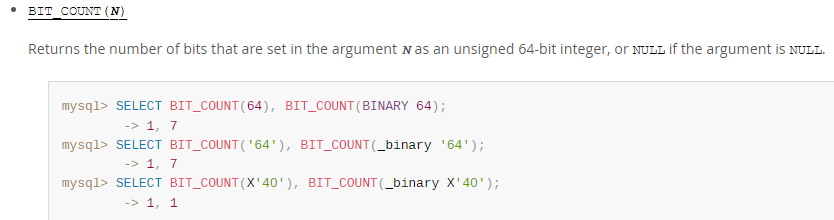
而mysql函数 uint
字符串 |
对数学不感兴趣的请跳过本comment而 https://en.wikipedia.org/wiki/Hamming_distance 指出:
原文中的
所以当定义域是二进制时 https://en.wikipedia.org/wiki/Hamming_weight#Language_support 又指出
而推广到任何字符串定义域时,hamming weight是输入字符串与该字符串可用值的全 注意这实际上与上文中hamming距离的定义构成了循环论证( 为了避免循环论证就需要引入额外的 https://en.wikipedia.org/wiki/Hamming_space 概念
可以构造一个对于3位长的二进制(也就是说 我们不难看出图中每个顶点的值都是他的坐标的
众所周知立方体有8个顶点,这8个顶点代表着3位二进制序列的 然后我们只需要给任意每两个顶点(也就是输入a, b)之间画线找出最短的路径也就是曼哈顿距离,那么这个路径经过的 而当输入二进制是4位长时,其hamming space就是一个四维超立方体:
但我们仍然可以对这个超立方体的两个顶点找出曼哈顿距离:
建议回顾经典之世界名画:在三维空间中对四维超立方体的Schlegel diagram透视投影线框二维图片: https://www.software3d.com/Stella.php 因此 https://en.wikipedia.org/wiki/Hamming_distance#Properties 对hamming距离给出的替代定义是
以下是错误的假想:
除此之外我们也可以额外再将hamming weight定义为 对
|







|
所以phash的意思是两个图片之间的不相似度决定了他们对应的hash值的差异程度,然后用哈明距离来测,比如说这两个hash之间的相似度是多少个9……这样嘛 |
如果您非要做统计学意义上的normalization以展示给前端用户带领导看,您可以简单的做 |
|
确实 |
对hamming distance的输入做什么进制/编码转换(或者不转换)有着重要的区别:这是一个基于 #63 (comment) 中指出的
用ts/js实现的 $$ 对两个输入集合进行逐成员异或后对所有不同的成员出现次数求和(也就是 const weight = (s: ReturnType<typeof sequenceDiff>) =>
s.reduce<number>((acc: number, cur: 0|1) => acc + Number(cur), 0);
const sequenceDiff = (a: string[], b: string[]): Array<0|1> =>
a.map((x, i) => b[i] === x ? 0 : 1);
const distance = (a: string, b: string) => weight(sequenceDiff(a.split(''), b.split('')));demo: jsfiddle, ts playground
所以pr author在最开始提到的
如果您直接比较字符串形式的这两个hash,那么d和c之间只会有1个距离,而作为bin表达时就是3bit 因此您需要根据您的实际需求来决定是否转换hamming距离的两个输入值,以及转换成什么
hamming距离的泛用性如果对 const sequenceDiff = (a: string[], b: string[]): Array<0|1> =>
a.map((x, i) => b[i] === x ? 0 : 1);中的 当然当您不需要这种泛性时,例如您只需要对两个int(或者说 // https://stackoverflow.com/questions/43122082/efficiently-count-the-number-of-bits-in-an-integer-in-javascript/43122214#43122214
function bitCount (n) {
n = n - ((n >> 1) & 0x55555555)
n = (n & 0x33333333) + ((n >> 2) & 0x33333333)
return ((n + (n >> 4) & 0xF0F0F0F) * 0x1010101) >> 24
}
const distance = (a, b) => bitCount(a ^ b);
console.log(distance(1, 2)); // 0b01, 0b10 = 2
console.log(distance(64, 65)); // 0b1000000, 0b1000001 = 1 |





|
#63 (comment) 中曾经提出:
https://en.wikipedia.org/wiki/Edit_distance#Types_of_edit_distance 指出
https://en.wikipedia.org/wiki/Levenshtein_distance#Upper_and_lower_bounds 进一步指出了对于相同的输入,levenshtein距离有可能比hamming距离更小
为什么hamming距离要求两个输入字符串的长度必须相同
|
回顾经典之 |


|
莱文斯坦距离的计算效率比哈明距离的计算效率要低得多,而且您也提到了莱文斯坦距离除了替换外还允许其他操作,在hash这个场景里我会怀疑这个算法的适用性,或者某种程度上的overkill。 |
#63 (comment) 指出对于纯
hash是定长的,除非您在比较不同长度的SHA-2/3,如SHA-256和SHA-512,但那也没有意义因为对于相同输入不同长度的SHA-2/3输出完全不同(雪崩效应) |
|
对于不同算法的hash出来的结果进行字面上的比较没有意义。 至于莱文斯坦和哈明距离的选用问题,sof上有过评价:
也许您应该考虑一下,对于两个字符串,如果他们的输出值一致时,这意味着什么。 https://stackoverflow.com/questions/4588541/hamming-distance-vs-levenshtein-distance |
然而我并不知道phash算法对于两张肉眼看起来相似的图片是否会产生相似但具有位移的phash(就像 事实核查:截止2022年12月26号,我们仍未能知晓 #63 (comment)
so问题的第二个回答 https://stackoverflow.com/questions/4588541/hamming-distance-vs-levenshtein-distance/54811897#54811897 进一步指出:
这也就是 #63 (comment) 中的
TL;DR
|
|
例子
|

ef8a8c3#r94765151 进一步指出:
|
libphash本身就提供了3种算法:分别基于
这篇币圈部落格直观的将多个图片hash算法的每步骤进行了可视化: https://content-blockchain.org/research/testing-different-image-hash-functions/ 其所测试的算法实现来自 https://github.com/JohannesBuchner/imagehash 这个py库重新实现并封装了多个传统算法和基于CNN的 而十年前的某位数字取证学家 FotoForensics.com 站长Neal Krawetz(其发明了 https://en.wikipedia.org/wiki/Error_level_analysis )早已研究出了ahash dhash phash等算法的早期朴素实现: https://www.hackerfactor.com/blog/index.php?/archives/432-Looks-Like-It.html 建议回顾21年时时任四叶ipad头子 @BANKA2017 所抵制的苹果为了与邪恶组织NCMEC合作共同对抗 以及10年前MSFT出于类似目的发明专利PhotoDNA https://github.com/jankais3r/jPhotoDNA https://github.com/gabedwrds/photodna-matcher |


|
居然不是indoor post或者post in post |
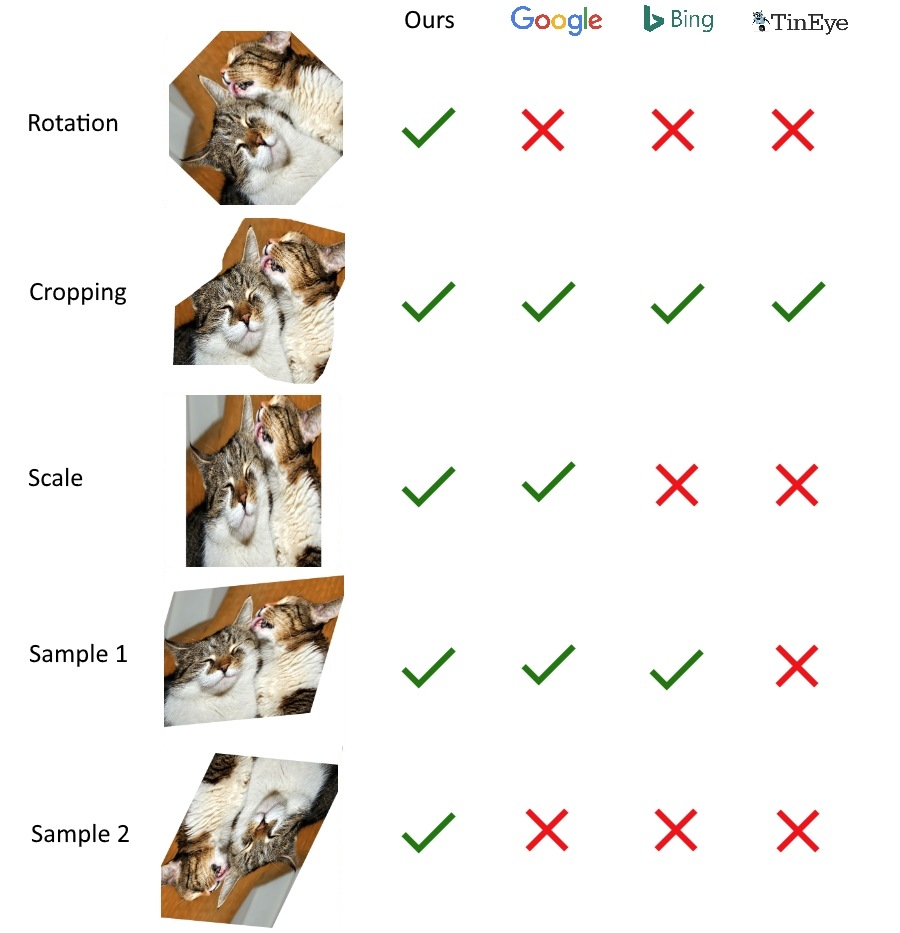
https://docs.opencv.org/4.x/d4/d93/group__img__hash.html 某国人 @stereomatchingkiss 早已于16年重复造了上述图片hash算法的实现并pr至opencv: opencv/opencv_contrib#688 19年有人指责重新实现算法违反了libphash的GPL: opencv/opencv_contrib#2183 |
|
lumina37/aiotieba-reviewer@2b07113 所以阁下又换opencv_contrib img_hash的ahash了? 我的建议是直接用上所有opencv_contrib img_hash的可用hash算法,然而即便如此都比我用paddleocr+tesseract扫一遍图片要快 |
|
本来就是ahash,之前忘了改注释而已 |
shitianshiwa/baidu-tieba-userscript#11 (comment) 现在 curl -s https://imgsrc.baidu.com/forum/pic/item/ced3a70f4bfbfbedad90125e3ef0f736aec31f45.jpg | tee >(shasum -a 512) | identify -
实际上只是需要加request header之 https://en.wikipedia.org/wiki/HTTP_referer curl -sH 'Referer: https://tieba.baidu.com' https://imgsrc.baidu.com/forum/pic/item/ced3a70f4bfbfbedad90125e3ef0f736aec31f45.jpg | tee >(shasum -a 512) | identify -
|


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
imgsrc还能用就行 |
原代码检测违规图像是基于图像phash的完全匹配,这导致同一幅违规图像可能因为某些细微的差异(例如右下角水印,原图与缩略图,二次压缩)而计算得到不同的phash,从而无法被检测出。例如,这是我曾遇到的两幅图像的phash值:
0600300d00040000
0600380c08040000
这两幅图片是同一张图,贴吧的raw_hash都一样,但计算得到的phash有3bit的差异,导致没有识别出违规图片。针对这种情况,可以检测图像phash的海明距离,而不是匹配完全相同的phash。通常,当两幅图像的64位phash的海明距离小于等于5位时,即可认为这两幅图像非常相似,大概率是同一张图。
我在函数
get_imghash中添加了参数hamming_distance,当值不为0时,将筛选所有海明距离小于等于此值的图片;当值为0时,将匹配完全相同的phash(即原逻辑)。