Considering the increasing volume of unstructured data in the world, Information Retrieval (IR) (a sub-area of text mining) and Information Extraction (IE) are extremely important to deal efficiently with all that data. Industry, IR, companies, marketing, economics and many other sectors highly depend on the efficiency and robustness of these techniques and tools.
Developed at Aveiro University by @luminoso and @ruifpedro, this IR/IE engine deals with the overall process of gathering, indexing and searching for relevant documents from huge collections of textual data in order to extract knowledge from unstructured existing data.
Features:
- Components are developed in a modules;
- Memory adaptability to the host;
- Multi threaded.
The engine is currently adapted to process a CSV corpus collected from StackOverflow questions and answers, we include a small stack in the repository for demonstration purposes. Given the modularity of the engine it can be easily adapted to any other type of corpus. For further testing, the full sized corpus can be downloaded here.
This project uses Apache Maven for build management, and so, you can run package everything into a jar by executing:
mvn clean packageThe shade goal is included in the pom file to package a jar with every dependence needed.
The engine requires Java 8 as it minimal major java version, it is compatible with both Oracle Java 8 and OpenJDK 8 but it isn't backward compatible with older Java versions.
There are several ways to run the engine. You can import it as a Maven project using your favorite IDE and run it from there, use the provided compiled jar, or use your own jar, packaged by you from the existing source code.
- Run with -h switch for help:
$ java -jar IR-2016_17-0.0.1-SNAPSHOT.jar -h| Option | Description | Default |
|---|---|---|
| -d <arg> | Directory containing text corpus to process | ./stacksample |
| -f <arg> | Stop words to use | ./stop_processed.txt |
| -o <arg> | Output directory to store processed index | ./disk |
| -h | print the help message |
- Processing ./stacksample requires no arguments. Default stack directory is ./stacksample
$ java -jar IR-2016_17-0.0.1-SNAPSHOT.jarOutput of the progress is displayed while running.
- Query processed stack for the words buffer and color.
The interface for querying the database is shown. Example:
$ java -jar IR-2016_17-0.0.1-SNAPSHOT.jar -q
Insert query (Control+c to exit): buffer color
Number of results to query (10):
┌──────────────────────────────────────────────────────────────────────────┐
│ Information Retrieval │
├──────────────────────────────────────────────────────────────────────────┤
├───────────────────────────────┬──────────────────────────────────────────┤
│ Terms: │ │
│ • Query │ [buffer, color] │
│ • Tokenized │ [buffer, color] │
├───────────────────────────────┴──────────────────────────────────────────┤
├───────────────────────────────┬──────────────────────────────────────────┤
│ Results found │ 14 │
├───────────────────────────────┼──────────────────────────────────────────┤
│ Database size │ 958 │
├───────────────────────────────┼──────────────────────────────────────────┤
│ Token count │ 4804 │
├───────────────────────────────┼──────────────────────────────────────────┤
│ Results to retrieve │ 10 │
├───────────────────────────────┴──────────────────────────────────────────┤
├──────┬────────────────────────┬──────────┬───────────────────────────────┤
│ Rank │ Score │ Document │ Path │
├──────┼────────────────────────┼──────────┼───────────────────────────────┤
│ 1 │ 0.2792691357898761 │ 896 │ ./stacksample/Questions.csv │
│ 2 │ 0.2544781393660751 │ 781 │ ./stacksample/Questions.csv │
│ 3 │ 0.20702654309708213 │ 354 │ ./stacksample/Questions.csv │
│ 4 │ 0.18761207533221913 │ 340 │ ./stacksample/Questions.csv │
│ 5 │ 0.16297804872950658 │ 37 │ ./stacksample/Answers.csv │
│ 6 │ 0.16273914301263454 │ 12 │ ./stacksample/Answers.csv │
│ 7 │ 0.1576064181842389 │ 394 │ ./stacksample/Questions.csv │
│ 8 │ 0.15217728526150623 │ 108 │ ./stacksample/Answers.csv │
│ 9 │ 0.1287816215117765 │ 322 │ ./stacksample/Questions.csv │
│ 10 │ 0.12816593333587364 │ 6 │ ./stacksample/Answers.csv │
└──────┴────────────────────────┴──────────┴───────────────────────────────┘
The engine is designed as set of macro modules that interact with each other. Overall view is the following:
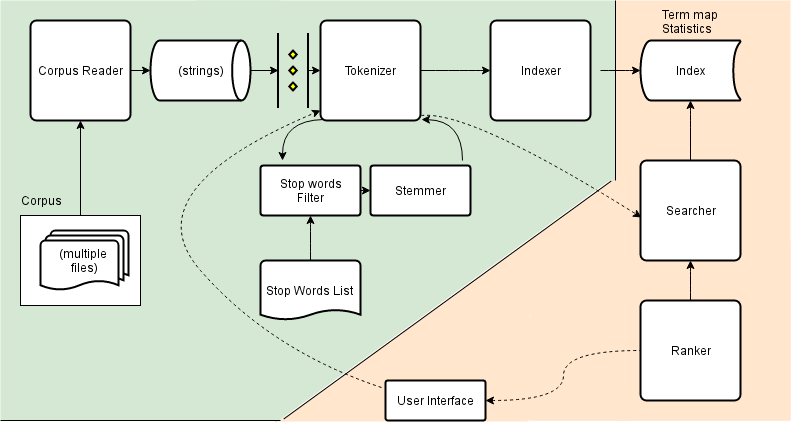
| Module | Description |
|---|---|
| Corpus Reader | Parses the input. In the given example, files in ./stacksample |
| Tokenizer | Tokenizes document (removal of stop words, stemming, etc) |
| Indexer | Processes the tokens, computes LNC and serialize the results |
| Searcher | Controls the query interface and the mechanisms to perform a query |
| Ranker | Ranks the results using LNC/TLC approach |