3.4.1 lyft #56
Closed
3.4.1 lyft #56
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…s at DataFrameNaFunctionSuite.scala ### What changes were proposed in this pull request? This PR proposes to disable ANSI mode in both `replace float with nan` and `replace double with nan` tests. ### Why are the changes needed? To recover the build https://github.com/apache/spark/actions/runs/4349682658 with ANSI mode on. Spark Connect side does not fully leverage the error framework yet .. so simply disabling it for now. ### Does this PR introduce _any_ user-facing change? No, test-only. ### How was this patch tested? Manually ran them in IDE with ANSI mode on. Closes apache#40311 from HyukjinKwon/SPARK-42559-followup. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit c3a09e2) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request? Add spark connect shell to start the spark shell with spark connect enabled. Added "-Pconnect" to build the spark connect in the distributions. Simplified the dev shell scripts with "-Pconnect" command. ### Why are the changes needed? Allow users to play with spark connect easily. ### Does this PR introduce _any_ user-facing change? Yes. Added a new shell script and "-Pconnect" build option. ### How was this patch tested? Manually tested. Closes apache#40305 from zhenlineo/connect-shell. Authored-by: Zhen Li <zhenlineo@users.noreply.github.com> Signed-off-by: Herman van Hovell <herman@databricks.com> (cherry picked from commit 2e7207f) Signed-off-by: Herman van Hovell <herman@databricks.com>
…Exception` catch to `repl.Main` for Scala 2.13 ### What changes were proposed in this pull request? This pr add the same `ClassNotFoundException` catch to `repl.Main` for Scala 2.13 as apache#40305 due `org/apache/spark/repl/Main.scala` is Scala version sensitive。 ### Why are the changes needed? Make sure Scala 2.12 and 2.13 have the same logic ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manual check Closes apache#40318 from LuciferYang/SPARK-42656-FOLLOWUP. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Herman van Hovell <herman@databricks.com> (cherry picked from commit 67328de) Signed-off-by: Herman van Hovell <herman@databricks.com>
### What changes were proposed in this pull request? This pr aims to implement Dataset.toJSON. ### Why are the changes needed? Add Spark connect jvm client api coverage. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Add new test - Manually checked Scala 2.13 Closes apache#40319 from LuciferYang/SPARK-42692. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Herman van Hovell <herman@databricks.com> (cherry picked from commit 51504e4) Signed-off-by: Herman van Hovell <herman@databricks.com>
…ssing column names ### What changes were proposed in this pull request? Fixes `createDataFrame` to autogenerate missing column names. ### Why are the changes needed? Currently the number of the column names specified to `createDataFrame` does not match the actual number of columns, it raises an error: ```py >>> spark.createDataFrame([["a", "b"]], ["col1"]) Traceback (most recent call last): ... ValueError: Length mismatch: Expected axis has 1 elements, new values have 2 elements ``` but it should auto-generate the missing column names. ### Does this PR introduce _any_ user-facing change? It will auto-generate the missing columns: ```py >>> spark.createDataFrame([["a", "b"]], ["col1"]) DataFrame[col1: string, _2: string] ``` ### How was this patch tested? Enabled the related test. Closes apache#40310 from ueshin/issues/SPARK-42022/columns. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 056ed5d) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fixes `spark.sql` to return values from the command.
### Why are the changes needed?
Currently `spark.sql` doesn't return the result from the commands.
```py
>>> spark.sql("show functions").show()
+--------+
|function|
+--------+
+--------+
```
### Does this PR introduce _any_ user-facing change?
`spark.sql` with commands will return the values.
### How was this patch tested?
Added a test.
Closes apache#40323 from ueshin/issues/SPARK-42705/sql.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Ruifeng Zheng <ruifengz@apache.org>
(cherry picked from commit 1507a52)
Signed-off-by: Ruifeng Zheng <ruifengz@apache.org>
…8s in cluster deploy mode ### What changes were proposed in this pull request? The PR fixes the authentication failure of the proxy user on driver side while accessing kerberized hdfs through spark on k8s job. It follows the similar approach as it was done for Mesos: mesosphere#26 ### Why are the changes needed? When we try to access the kerberized HDFS through a proxy user in Spark Job running in cluster deploy mode with Kubernetes resource manager, we encounter AccessControlException. This is because authentication in driver is done using tokens of the proxy user and since proxy user doesn't have any delegation tokens on driver, auth fails. Further details: https://issues.apache.org/jira/browse/SPARK-25355?focusedCommentId=17532063&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17532063 https://issues.apache.org/jira/browse/SPARK-25355?focusedCommentId=17532135&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17532135 ### Does this PR introduce _any_ user-facing change? Yes, user will now be able to use proxy-user to access kerberized hdfs with Spark on K8s. ### How was this patch tested? The patch was tested by: 1. Running job which accesses kerberized hdfs with proxy user in cluster mode and client mode with kubernetes resource manager. 2. Running job which accesses kerberized hdfs without proxy user in cluster mode and client mode with kubernetes resource manager. 3. Build and run test github action : https://github.com/shrprasa/spark/actions/runs/3051203625 Closes apache#37880 from shrprasa/proxy_user_fix. Authored-by: Shrikant Prasad <shrprasa@visa.com> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit b3b3557) Signed-off-by: Kent Yao <yao@apache.org>
…dule ### What changes were proposed in this pull request? Run the following commands ``` build/mvn clean install -DskipTests -pl connector/connect/server -am build/mvn test -pl connector/connect/server ``` then we can see the following error message due to [SPARK-42555](https://issues.apache.org/jira/browse/SPARK-42555) A adds the loading `org.h2.Driver` in `beforeAll` of `ProtoToParsedPlanTestSuite`, but ``` ProtoToParsedPlanTestSuite: *** RUN ABORTED *** java.lang.ClassNotFoundException: org.h2.Driver at java.base/java.net.URLClassLoader.findClass(URLClassLoader.java:476) at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:589) at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:522) at java.base/java.lang.Class.forName0(Native Method) at java.base/java.lang.Class.forName(Class.java:398) at org.apache.spark.util.Utils$.classForName(Utils.scala:225) at org.apache.spark.sql.connect.ProtoToParsedPlanTestSuite.beforeAll(ProtoToParsedPlanTestSuite.scala:68) at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:212) at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210) at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208) ... ``` So this pr add `h2` as test dependency of connect-server module to make maven test pass. ### Why are the changes needed? Add `h2` as test dependency of connect-server module to make maven test pass. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? manual check: ``` build/mvn clean install -DskipTests -pl connector/connect/server -am build/mvn test -pl connector/connect/server ``` with this pr, all test passed Closes apache#40317 from LuciferYang/SPARK-42700. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit aa8b41c) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
… stability warning ### What changes were proposed in this pull request? This PR updates the developer documentation by removing the warnings about API compatibility. ### Why are the changes needed? We actually are going to keep the compatibility there. Such warnings cause a misconception that we can just break the compatibility there. ### Does this PR introduce _any_ user-facing change? No, it's developer-only docs. ### How was this patch tested? Linters in CI should test it out. Closes apache#40325 from HyukjinKwon/SPARK-42707. Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org> Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com> Signed-off-by: Ruifeng Zheng <ruifengz@apache.org> (cherry picked from commit b63c11c) Signed-off-by: Ruifeng Zheng <ruifengz@apache.org>
… functions ### What changes were proposed in this pull request? Implement `spark.udf.registerJavaFunction` and `spark.udf.registerJavaUDAF`. A new proto `JavaUDF` is introduced. ### Why are the changes needed? Parity with vanilla PySpark. ### Does this PR introduce _any_ user-facing change? Yes. `spark.udf.registerJavaFunction` and `spark.udf.registerJavaUDAF` are supported now. ### How was this patch tested? Parity unit tests. Closes apache#40244 from xinrong-meng/registerJava. Authored-by: Xinrong Meng <xinrong@apache.org> Signed-off-by: Xinrong Meng <xinrong@apache.org> (cherry picked from commit 92aa087) Signed-off-by: Xinrong Meng <xinrong@apache.org>
…using PyTorch functions ### What changes were proposed in this pull request? I added a better way to show the error instead of having it be confusing for the reader. ### Why are the changes needed? User experience. ### Does this PR introduce _any_ user-facing change? Just the error that will be shown to the user. ### How was this patch tested? Tested it out locally. Closes apache#40322 from rithwik-db/torch-distributor-error-fix. Authored-by: Rithwik Ediga Lakhamsani <rithwik.ediga@databricks.com> Signed-off-by: Ruifeng Zheng <ruifengz@apache.org> (cherry picked from commit 5db84b5) Signed-off-by: Ruifeng Zheng <ruifengz@apache.org>
…Arrow ### What changes were proposed in this pull request? Improve docstring of mapInPandas and mapInArrow ### Why are the changes needed? For readability. We call out they are not scalar - the input and output of the function might be of different sizes. ### Does this PR introduce _any_ user-facing change? No. Doc change only. ### How was this patch tested? Existing tests. Closes apache#40330 from xinrong-meng/doc. Lead-authored-by: Xinrong Meng <xinrong@apache.org> Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit bacab6a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
…on when IPython is used
### What changes were proposed in this pull request?
This PR proposes to remove the parent directory in `shell.py` execution when IPython is used.
This is a general issue for PySpark shell specifically with IPython - IPython temporarily adds the parent directory of the script into the Python path (`sys.path`), which results in searching packages under `pyspark` directory. For example, `import pandas` attempts to import `pyspark.pandas`.
So far, we haven't had such cases within PySpark itself importing code path, but Spark Connect now has the case via checking dependency checking (which attempts to import pandas) which exposes the actual problem.
Running it with IPython can easily reproduce the error:
```bash
PYSPARK_PYTHON=ipython bin/pyspark --remote "local[*]"
```
### Why are the changes needed?
To make PySpark shell properly import other packages even when the names conflict with subpackages (e.g., `pyspark.pandas` vs `pandas`)
### Does this PR introduce _any_ user-facing change?
No to the end users:
- Because this path is only inserted for `shell.py` execution, and thankfully we didn't have such relative import case so far.
- It fixes the issue in the unreleased, Spark Connect.
### How was this patch tested?
Manually tested.
```bash
PYSPARK_PYTHON=ipython bin/pyspark --remote "local[*]"
```
**Before:**
```
Python 3.9.16 | packaged by conda-forge | (main, Feb 1 2023, 21:42:20)
Type 'copyright', 'credits' or 'license' for more information
IPython 8.10.0 -- An enhanced Interactive Python. Type '?' for help.
/.../spark/python/pyspark/shell.py:45: UserWarning: Failed to initialize Spark session.
warnings.warn("Failed to initialize Spark session.")
Traceback (most recent call last):
File "/.../spark/python/pyspark/shell.py", line 40, in <module>
spark = SparkSession.builder.getOrCreate()
File "/.../spark/python/pyspark/sql/session.py", line 437, in getOrCreate
from pyspark.sql.connect.session import SparkSession as RemoteSparkSession
File "/.../spark/python/pyspark/sql/connect/session.py", line 19, in <module>
check_dependencies(__name__, __file__)
File "/.../spark/python/pyspark/sql/connect/utils.py", line 33, in check_dependencies
require_minimum_pandas_version()
File "/.../spark/python/pyspark/sql/pandas/utils.py", line 27, in require_minimum_pandas_version
import pandas
File "/.../spark/python/pyspark/pandas/__init__.py", line 29, in <module>
from pyspark.pandas.missing.general_functions import MissingPandasLikeGeneralFunctions
File "/.../spark/python/pyspark/pandas/__init__.py", line 34, in <module>
require_minimum_pandas_version()
File "/.../spark/python/pyspark/sql/pandas/utils.py", line 37, in require_minimum_pandas_version
if LooseVersion(pandas.__version__) < LooseVersion(minimum_pandas_version):
AttributeError: partially initialized module 'pandas' has no attribute '__version__' (most likely due to a circular import)
...
```
**After:**
```
Python 3.9.16 | packaged by conda-forge | (main, Feb 1 2023, 21:42:20)
Type 'copyright', 'credits' or 'license' for more information
IPython 8.10.0 -- An enhanced Interactive Python. Type '?' for help.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/03/08 13:30:51 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.5.0.dev0
/_/
Using Python version 3.9.16 (main, Feb 1 2023 21:42:20)
Client connected to the Spark Connect server at localhost
SparkSession available as 'spark'.
In [1]:
```
Closes apache#40327 from HyukjinKwon/SPARK-42266.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit 8e83ab7)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
…taFrame and Column to API reference ### What changes were proposed in this pull request? Add '__getattr__' and '__getitem__' of DataFrame and Column to API reference ### Why are the changes needed? '__getattr__' and '__getitem__' are widely used, but we did not document them. ### Does this PR introduce _any_ user-facing change? yes, new doc ### How was this patch tested? added doctests Closes apache#40331 from zhengruifeng/py_doc. Authored-by: Ruifeng Zheng <ruifengz@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit e28f7f3) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
…y default ### What changes were proposed in this pull request? Following generated columns, column default value should also have a catalog capability and v2 catalogs must explicitly declare SUPPORT_COLUMN_DEFAULT_VALUE to support it. ### Why are the changes needed? column default value needs dedicated handling and if a catalog simply ignores it, then query result can be wrong. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? new tests Closes apache#40299 from cloud-fan/default. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 69dd20b) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
… remaining jdbc API ### What changes were proposed in this pull request? apache#40252 supported some jdbc API that reuse the proto msg `DataSource`. The `DataFrameReader` also have another kind jdbc API that is unrelated to load data source. ### Why are the changes needed? This PR adds the new proto msg `PartitionedJDBC` to support the remaining jdbc API. ### Does this PR introduce _any_ user-facing change? 'No'. New feature. ### How was this patch tested? New test cases. Closes apache#40277 from beliefer/SPARK-42555_followup. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Herman van Hovell <herman@databricks.com> (cherry picked from commit 39a5512) Signed-off-by: Herman van Hovell <herman@databricks.com>
…able ### What changes were proposed in this pull request? This PR proposes to add a check for `__file__` attributes. ### Why are the changes needed? `__file__` might not be available everywhere. See also scikit-learn/scikit-learn#20081 ### Does this PR introduce _any_ user-facing change? If users' Python environment does not have `__file__`, now users can use PySpark in their environment too. ### How was this patch tested? Manually tested. Closes apache#40328 from HyukjinKwon/SPARK-42709. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit f95fc19) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request? 1. Change to get matching partition names rather than partition objects when drop partitions ### Why are the changes needed? 1. Partition names are enough to drop partitions 2. It can reduce the time overhead and driver memory overhead. ### Does this PR introduce _any_ user-facing change? Yes, we have add a new sql conf to enable this feature: `spark.sql.hive.dropPartitionByName.enabled` ### How was this patch tested? Add new tests. Closes apache#40069 from wecharyu/SPARK-42480. Authored-by: wecharyu <yuwq1996@gmail.com> Signed-off-by: Chao Sun <sunchao@apple.com>
… cache the schema ### What changes were proposed in this pull request? As of now that Connect Python client cache the schema when calling `def schema()`. However this might cause stale data issue. For example: ``` 1. Create table 2. table.schema 3. drop table and recreate the table with different schema 4. table.schema // now this is incorrect ``` ### Why are the changes needed? Fix the behavior when the cached schema could be stale. ### Does this PR introduce _any_ user-facing change? This is actually a fix that users now can always see the most up-to-dated schema. ### How was this patch tested? Existing UT Closes apache#40343 from amaliujia/disable_cache. Authored-by: Rui Wang <rui.wang@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit a77bb37) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
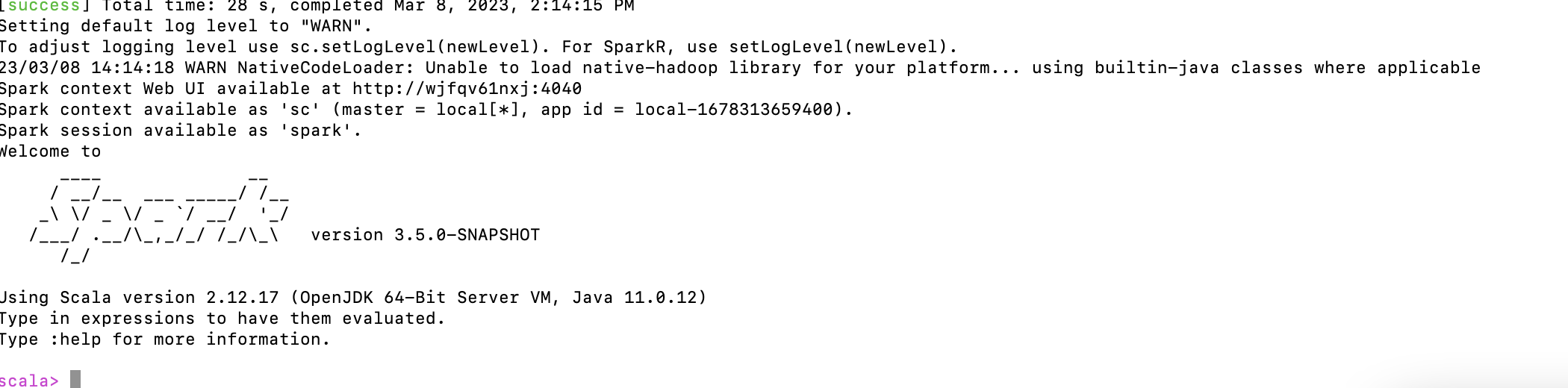
### What changes were proposed in this pull request? The spark-connect script is broken as it need a jar at the end. Also ensured when scala 2.13 is set, all commands in the scripts runs with `-PScala-2.13` Example usage: Start spark connect with default settings: * `./connector/connect/bin/spark-connect-shell` * or `./connector/connect/bin/spark-connect` (Enter "q" <new line> to exit the program) Start Scala client with default settings: `./connector/connect/bin/spark-connect-scala-client` Start spark connect with extra configs: * `./connector/connect/bin/spark-connect-shell --conf spark.connect.grpc.binding.port=8888` * or `./connector/connect/bin/spark-connect --conf spark.connect.grpc.binding.port=8888` Start Scala client with a connection string: ``` export SPARK_REMOTE="sc://localhost:8888/" ./connector/connect/bin/spark-connect-scala-client ``` ### Why are the changes needed? Bug fix ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually tested on 2.12 and 2.13 for all the scripts changed. Test example with expected results: `./connector/connect/bin/spark-connect-shell` : <img width="1050" alt="Screen Shot 2023-03-08 at 2 14 31 PM" src="https://user-images.githubusercontent.com/4190164/223863343-d5d159d9-da7c-47c7-b55a-a2854c5f5d76.png"> Verify the spark connect server is started at the correct port, e.g. ``` >Telnet localhost 15002 Trying ::1... Connected to localhost. Escape character is '^]'. ``` `./connector/connect/bin/spark-connect`: <img width="1680" alt="Screen Shot 2023-03-08 at 2 13 09 PM" src="https://user-images.githubusercontent.com/4190164/223863099-41195599-c49d-4db4-a1e2-e129a649cd81.png"> Server started successfully when seeing the last line output. `./connector/connect/bin/spark-connect-scala-client`: <img width="1658" alt="Screen Shot 2023-03-08 at 2 11 58 PM" src="https://user-images.githubusercontent.com/4190164/223862992-c8a3a36a-9f69-40b8-b82e-5dab85ed14ce.png"> Verify the client can run some simple quries. Closes apache#40344 from zhenlineo/fix-scripts. Authored-by: Zhen Li <zhenlineo@users.noreply.github.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit b5243d7) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
…imestampType ### What changes were proposed in this pull request? Support parsing `timestamp_ltz` as `TimestampType` in schema JSON string. It also add tests for both parsing JSON/DDL for "timestamp_ltz" and "timestamp_ntz" ### Why are the changes needed? `timestamp_ltz` becomes an alias for TimestampType since Spark 3.4 ### Does this PR introduce _any_ user-facing change? No, the new keyword is not released yet. ### How was this patch tested? New UT Closes apache#40345 from gengliangwang/parseJson. Authored-by: Gengliang Wang <gengliang@apache.org> Signed-off-by: Gengliang Wang <gengliang@apache.org> (cherry picked from commit c4756ed) Signed-off-by: Gengliang Wang <gengliang@apache.org>
…instead of 0 for the duration field
### What changes were proposed in this pull request?
Fix /api/v1/applications to return total uptime instead of 0 for duration
### Why are the changes needed?
Fix REST API OneApplicationResource
### Does this PR introduce _any_ user-facing change?
yes, /api/v1/applications will return the total uptime instead of 0 for the duration
### How was this patch tested?
locally build and run
```json
[ {
"id" : "local-1678183638394",
"name" : "SparkSQL::10.221.102.180",
"attempts" : [ {
"startTime" : "2023-03-07T10:07:17.754GMT",
"endTime" : "1969-12-31T23:59:59.999GMT",
"lastUpdated" : "2023-03-07T10:07:17.754GMT",
"duration" : 20317,
"sparkUser" : "kentyao",
"completed" : false,
"appSparkVersion" : "3.5.0-SNAPSHOT",
"startTimeEpoch" : 1678183637754,
"endTimeEpoch" : -1,
"lastUpdatedEpoch" : 1678183637754
} ]
} ]
```
Closes apache#40313 from yaooqinn/SPARK-42697.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
(cherry picked from commit d3d8fdc)
Signed-off-by: Kent Yao <yao@apache.org>
… client
### What changes were proposed in this pull request?
This pr add a new proto message
```
message Parse {
// (Required) Input relation to Parse. The input is expected to have single text column.
Relation input = 1;
// (Required) The expected format of the text.
ParseFormat format = 2;
// (Optional) DataType representing the schema. If not set, Spark will infer the schema.
optional DataType schema = 3;
// Options for the csv/json parser. The map key is case insensitive.
map<string, string> options = 4;
enum ParseFormat {
PARSE_FORMAT_UNSPECIFIED = 0;
PARSE_FORMAT_CSV = 1;
PARSE_FORMAT_JSON = 2;
}
}
```
and implement CSV/JSON parsing functions for Scala client.
### Why are the changes needed?
Add Spark connect jvm client api coverage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Pass Github Actions
- Manual checked Scala 2.13
Closes apache#40332 from LuciferYang/SPARK-42690.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Ruifeng Zheng <ruifengz@apache.org>
(cherry picked from commit 07f71d2)
Signed-off-by: Ruifeng Zheng <ruifengz@apache.org>
### What changes were proposed in this pull request? The pr aims to upgrade buf from 1.15.0 to 1.15.1 ### Why are the changes needed? Release Notes: https://github.com/bufbuild/buf/releases bufbuild/buf@v1.15.0...v1.15.1 Manually test: dev/connect-gen-protos.sh This upgrade will not change the generated files. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manually test and Pass GA. Closes apache#40348 from panbingkun/SPARK-42724. Authored-by: panbingkun <pbk1982@gmail.com> Signed-off-by: Ruifeng Zheng <ruifengz@apache.org> (cherry picked from commit 1d83a76) Signed-off-by: Ruifeng Zheng <ruifengz@apache.org>
### What changes were proposed in this pull request? Rename FrameMap proto to MapPartitions. ### Why are the changes needed? For readability. Frame Map API refers to mapInPandas and mapInArrow, which are equivalent to MapPartitions. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes apache#40329 from xinrong-meng/mapInArrow. Authored-by: Xinrong Meng <xinrong@apache.org> Signed-off-by: Ruifeng Zheng <ruifengz@apache.org> (cherry picked from commit 7a67be1) Signed-off-by: Ruifeng Zheng <ruifengz@apache.org>
…arsing DDL string until SparkConnectClient is available ### What changes were proposed in this pull request? Introduces `UnparsedDataType` and delays parsing DDL string for Python UDFs until `SparkConnectClient` is available. `UnparsedDataType` carries the DDL string and parse it in the server side. It should not be enclosed in other data types. Also changes `createDataFrame` to use the proto `DDLParse`. ### Why are the changes needed? Currently `parse_data_type` depends on `PySparkSession` that creates a local PySpark, but it won't be available in the client side. When `SparkConnectClient` is available, we can use the new proto `DDLParse` to parse the data types as string. ### Does this PR introduce _any_ user-facing change? The UDF's `returnType` attribute could be a string in Spark Connect if it is provided as string. ### How was this patch tested? Existing tests. Closes apache#40260 from ueshin/issues/SPARK-42630/ddl_parse. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit c0b1735) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
…ut path parameter
### What changes were proposed in this pull request?
Fixes `DataFrameWriter.save` to work without path parameter.
### Why are the changes needed?
`DataFrameWriter.save` should work without path parameter because some data sources, such as jdbc, noop, works without those parameters.
```py
>>> print(spark.range(10).write.format("noop").mode("append").save())
Traceback (most recent call last):
...
AssertionError: Invalid configuration of WriteCommand, neither path or table present.
```
### Does this PR introduce _any_ user-facing change?
The data sources that don't need path parameter will work.
```py
>>> print(spark.range(10).write.format("noop").mode("append").save())
None
```
### How was this patch tested?
Added a test.
Closes apache#40356 from ueshin/issues/SPARK-42733/save.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Ruifeng Zheng <ruifengz@apache.org>
(cherry picked from commit c2ee08b)
Signed-off-by: Ruifeng Zheng <ruifengz@apache.org>
### What changes were proposed in this pull request?
Implement `DataFrame.mapInArrow`.
### Why are the changes needed?
Parity with vanilla PySpark.
### Does this PR introduce _any_ user-facing change?
Yes. `DataFrame.mapInArrow` is supported as shown below.
```
>>> import pyarrow
>>> df = spark.createDataFrame([(1, 21), (2, 30)], ("id", "age"))
>>> def filter_func(iterator):
... for batch in iterator:
... pdf = batch.to_pandas()
... yield pyarrow.RecordBatch.from_pandas(pdf[pdf.id == 1])
...
>>> df.mapInArrow(filter_func, df.schema).show()
+---+---+
| id|age|
+---+---+
| 1| 21|
+---+---+
```
### How was this patch tested?
Unit tests.
Closes apache#40350 from xinrong-meng/mapInArrowImpl.
Authored-by: Xinrong Meng <xinrong@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit f35c2cb)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
…ry and CTE ### What changes were proposed in this pull request? This PR fixes a few issues of parameterized query: 1. replace placeholders in CTE/subqueries 2. don't replace placeholders in non-DML commands as it may store the original SQL text with placeholders and we can't resolve it later (e.g. CREATE VIEW). ### Why are the changes needed? make the parameterized query feature complete ### Does this PR introduce _any_ user-facing change? yes, bug fix ### How was this patch tested? new tests Closes apache#40333 from cloud-fan/parameter. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit a780703) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…n subquery and CTE" This reverts commit 8012728.
…ing QueryTerminatedEvent constructor ### What changes were proposed in this pull request? This is a follow-up of apache#41468 to fix `branch-3.4`'s compilation issue. ### Why are the changes needed? To recover the compilation. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs. Closes apache#41484 from dongjoon-hyun/SPARK-43973. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
This PR moves `ResolveDefaultColumnsSuite` from `catalyst/analysis` package to `sql` package. To fix the code layout. No. Pass the CI Closes apache#41520 from dongjoon-hyun/move. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 07cc04d) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
When we use spark shell to submit job like this:
```scala
$ spark-shell --conf spark.driver.memory=1g
val df = spark.range(5000000).withColumn("str", lit("abcdabcdabcdabcdabasgasdfsadfasdfasdfasfasfsadfasdfsadfasdf"))
val df2 = spark.range(10).join(broadcast(df), Seq("id"), "left_outer")
df2.collect
```
This will cause the driver to hang indefinitely.
When we disable AQE, the `java.lang.OutOfMemoryError` will be throws.
After I check the code, the reason are wrong way to use `Throwable::initCause`. It happened when OOM be throw on https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/BroadcastExchangeExec.scala#L184 . Then https://github.com/apache/spark/blob/master/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala#L2401 will be executed.
It use `new SparkException(..., case=oe).initCause(oe.getCause)`.
The doc in `Throwable::initCause` say
```
This method can be called at most once. It is generally called from within the constructor,
or immediately after creating the throwable. If this throwable was created with Throwable(Throwable)
or Throwable(String, Throwable), this method cannot be called even once.
```
So when we call it, the `IllegalStateException` will be throw. Finally, the `promise.tryFailure(ex)` never be called. The driver will be blocked.
### Why are the changes needed?
Fix the OOM never be reported bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Add new test
Closes apache#41517 from Hisoka-X/SPARK-42290_OOM_AQE_On.
Authored-by: Jia Fan <fanjiaeminem@qq.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit 4168e1a)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…sDB state store to avoid id mismatch error NOTE: This ports back the commit apache@d3b9f4e (PR apache#41089) to branch-3.4. This is a clean cherry-pick. ### What changes were proposed in this pull request? Skip reusing sst file for same version of RocksDB state store to avoid id mismatch error ### Why are the changes needed? In case of task retry on the same executor, its possible that the original task completed the phase of creating the SST files and uploading them to the object store. In this case, we also might have added an entry to the in-memory map for `versionToRocksDBFiles` for the given version. When the retry task creates the local checkpoint, its possible the file name and size is the same, but the metadata ID embedded within the file may be different. So, when we try to load this version on successful commit, the metadata zip file points to the old SST file which results in a RocksDB mismatch id error. ``` Mismatch in unique ID on table file 24220. Expected: {9692563551998415634,4655083329411385714} Actual: {9692563551998415639,10299185534092933087} in file /local_disk0/spark-f58a741d-576f-400c-9b56-53497745ac01/executor-18e08e59-20e8-4a00-bd7e-94ad4599150b/spark-5d980399-3425-4951-894a-808b943054ea/StateStoreId(opId=2147483648,partId=53,name=default)-d89e082e-4e33-4371-8efd-78d927ad3ba3/workingDir-9928750e-f648-4013-a300-ac96cb6ec139/MANIFEST-024212 ``` This change avoids reusing files for the same version on the same host based on the map entries to reduce the chance of running into the error above. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test RocksDBSuite ``` [info] Run completed in 35 seconds, 995 milliseconds. [info] Total number of tests run: 33 [info] Suites: completed 1, aborted 0 [info] Tests: succeeded 33, failed 0, canceled 0, ignored 0, pending 0 [info] All tests passed. ``` Closes apache#41530 from HeartSaVioR/SPARK-43404-3.4. Authored-by: Anish Shrigondekar <anish.shrigondekar@databricks.com> Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
…d rdd timeout ### What changes were proposed in this pull request? Executor timeout should be max of idle, shuffle and rdd timeout ### Why are the changes needed? Wrong timeout value when combining idle, shuffle and rdd timeout ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added test in `ExecutorMonitorSuite` Closes apache#41082 from warrenzhu25/max-timeout. Authored-by: Warren Zhu <warren.zhu25@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 7107742) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…acters correctly ### What changes were proposed in this pull request? The trim logic in Cast expression introduced in apache#29375 trim ASCII control characters unexpectly. Before this patch  And hive  ### Why are the changes needed? The behavior described above doesn't consistent with the behavior of Hive ### Does this PR introduce _any_ user-facing change? Yes ### How was this patch tested? add ut Closes apache#41535 from Kwafoor/trim_bugfix. Lead-authored-by: wangjunbo <wangjunbo@qiyi.com> Co-authored-by: Junbo wang <1042815068@qq.com> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit 80588e4) Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request? This PR aims to upgrade `silencer` to 1.7.13. ### Why are the changes needed? `silencer` 1.7.13 supports `Scala 2.12.18 & 2.13.11`. - https://github.com/ghik/silencer/releases/tag/v1.7.13 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs. Closes apache#41560 from dongjoon-hyun/silencer_1.7.13. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 04d84df) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
This reverts commit b04232c.
### What changes were proposed in this pull request? This PR aims to update `Apache YuniKorn` batch scheduler docs with v1.3.0 to recommend it in Apache Spark 3.4.1 and 3.5.0 users. ### Why are the changes needed? Apache YuniKorn v1.3.0 was released on 2023-06-12 with 160 resolved JIRAs. https://yunikorn.apache.org/release-announce/1.3.0 I installed YuniKorn v1.3.0 and tested manually. ``` $ helm list -n yunikorn NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION yunikorn yunikorn 1 2023-06-13 01:56:32.784863 -0700 PDT deployed yunikorn-1.3.0 ``` ``` $ build/sbt -Pkubernetes -Pkubernetes-integration-tests -Dspark.kubernetes.test.deployMode=docker-desktop "kubernetes-integration-tests/testOnly *.YuniKornSuite" -Dtest.exclude.tags=minikube,local,decom,r -Dtest.default.exclude.tags= ... [info] YuniKornSuite: [info] - SPARK-42190: Run SparkPi with local[*] (12 seconds, 49 milliseconds) [info] - Run SparkPi with no resources (20 seconds, 378 milliseconds) [info] - Run SparkPi with no resources & statefulset allocation (20 seconds, 583 milliseconds) [info] - Run SparkPi with a very long application name. (20 seconds, 606 milliseconds) [info] - Use SparkLauncher.NO_RESOURCE (19 seconds, 676 milliseconds) [info] - Run SparkPi with a master URL without a scheme. (20 seconds, 631 milliseconds) [info] - Run SparkPi with an argument. (22 seconds, 320 milliseconds) [info] - Run SparkPi with custom labels, annotations, and environment variables. (20 seconds, 469 milliseconds) [info] - All pods have the same service account by default (22 seconds, 537 milliseconds) [info] - Run extraJVMOptions check on driver (12 seconds, 268 milliseconds) ... ``` ``` $ k describe pod spark-test-app-33ec515e453e4301a90f626812db1153-driver -n spark-dbe522106eac40d4a17447bfa2947c45 ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduling 82s yunikorn spark-dbe522106eac40d4a17447bfa2947c45/spark-test-app-33ec515e453e4301a90f626812db1153-driver is queued and waiting for allocation Normal Scheduled 82s yunikorn Successfully assigned spark-dbe522106eac40d4a17447bfa2947c45/spark-test-app-33ec515e453e4301a90f626812db1153-driver to node docker-desktop Normal PodBindSuccessful 82s yunikorn Pod spark-dbe522106eac40d4a17447bfa2947c45/spark-test-app-33ec515e453e4301a90f626812db1153-driver is successfully bound to node docker-desktop Normal Pulled 82s kubelet Container image "docker.io/kubespark/spark:dev" already present on machine Normal Created 82s kubelet Created container spark-kubernetes-driver Normal Started 82s kubelet Started container spark-kubernetes-driver ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual review. Closes apache#41571 from dongjoon-hyun/SPARK-44038. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 223c196) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request? This PR aims to update ORC to 1.8.4. ### Why are the changes needed? This will bring the following bug fixes. - https://issues.apache.org/jira/projects/ORC/versions/12353041 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs. Closes apache#41592 from guiyanakuang/ORC-1.8.4. Authored-by: Yiqun Zhang <guiyanakuang@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…eryStageExec ### What changes were proposed in this pull request? This PR fixes compute stats when `BaseAggregateExec` nodes above `QueryStageExec`. For aggregation, when the number of shuffle output rows is 0, the final result may be 1. For example: ```sql SELECT count(*) FROM tbl WHERE false; ``` The number of shuffle output rows is 0, and the final result is 1. Please see the [UI](https://github.com/apache/spark/assets/5399861/9d9ad999-b3a9-433e-9caf-c0b931423891). ### Why are the changes needed? Fix data issue. `OptimizeOneRowPlan` will use stats to remove `Aggregate`: ``` === Applying Rule org.apache.spark.sql.catalyst.optimizer.OptimizeOneRowPlan === !Aggregate [id#5L], [id#5L] Project [id#5L] +- Union false, false +- Union false, false :- LogicalQueryStage Aggregate [sum(id#0L) AS id#5L], HashAggregate(keys=[], functions=[sum(id#0L)]) :- LogicalQueryStage Aggregate [sum(id#0L) AS id#5L], HashAggregate(keys=[], functions=[sum(id#0L)]) +- LogicalQueryStage Aggregate [sum(id#18L) AS id#12L], HashAggregate(keys=[], functions=[sum(id#18L)]) +- LogicalQueryStage Aggregate [sum(id#18L) AS id#12L], HashAggregate(keys=[], functions=[sum(id#18L)]) ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test. Closes apache#41576 from wangyum/SPARK-44040. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 55ba63c) Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request? Bump snappy-java from 1.1.10.0 to 1.1.10.1. ### Why are the changes needed? This mostly is a security version, the notable changes are CVE fixing. - CVE-2023-34453 Integer overflow in shuffle - CVE-2023-34454 Integer overflow in compress - CVE-2023-34455 Unchecked chunk length Full changelog: https://github.com/xerial/snappy-java/releases/tag/v1.1.10.1 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass GA. Closes apache#41616 from pan3793/SPARK-44070. Authored-by: Cheng Pan <chengpan@apache.org> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 0502a42) Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request? This PR fixes all dead links for K8s doc. ### Why are the changes needed? <img width="797" alt="image" src="https://github.com/apache/spark/assets/5399861/3ba3f048-776c-42e6-b455-86e90b6ef22f"> ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual test. Closes apache#41635 from wangyum/kubernetes. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 1ff6704) Signed-off-by: Yuming Wang <yumwang@ebay.com>
…xpression ### What changes were proposed in this pull request? The `hashCode() `of `UserDefinedScalarFunc` and `GeneralScalarExpression` is not good enough. Take for example, `GeneralScalarExpression` uses `Objects.hash(name, children)`, it adopt the hash code of `name` and `children`'s reference and then combine them together as the `GeneralScalarExpression`'s hash code. In fact, we should adopt the hash code for each element in `children`. Because `UserDefinedAggregateFunc` and `GeneralAggregateFunc` missing `hashCode()`, this PR also want add them. This PR also improve the toString for `UserDefinedAggregateFunc` and `GeneralAggregateFunc` by using bool primitive comparison instead `Objects.equals`. Because the performance of bool primitive comparison better than `Objects.equals`. ### Why are the changes needed? Improve the hash code for some DS V2 Expression. ### Does this PR introduce _any_ user-facing change? 'Yes'. ### How was this patch tested? N/A Closes apache#41543 from beliefer/SPARK-44018. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 8c84d2c) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
This is the PR for the 3.4.1 version of spark