1.時間割通知(old)
更新日: 23/02/07
- Schedule.ymlでバージョンを指定することでバグが発生しないようにしています。
- PEP8に基づいて並び替え
# 標準ライブラリ
import ast # 文字列→JSON
import datetime # 日付
import json # jsonファイルを扱う
import os # 環境変数用
import subprocess # GitHubActionsの環境変数追加
import time # 時間取得
import urllib.request # URLから画像取得
from logging import DEBUG, Formatter, StreamHandler, getLogger # デバッグ用
# サードパーティ製ライブラリ
import cv2u # 画像比較(URL版)
import gspread # Googleスプレッドシート情報収集
import requests # LINE、Discord通知
import tweepy # Twitter投稿
from oauth2client.service_account import ServiceAccountCredentials # Googleスプレッドシート接続
from selenium import webdriver # サイトから画像取得(以下同様)
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait- 実行したタイミングを記録(ログ用)
- [2022年04月1日(金) 10:30:45]という風に表示
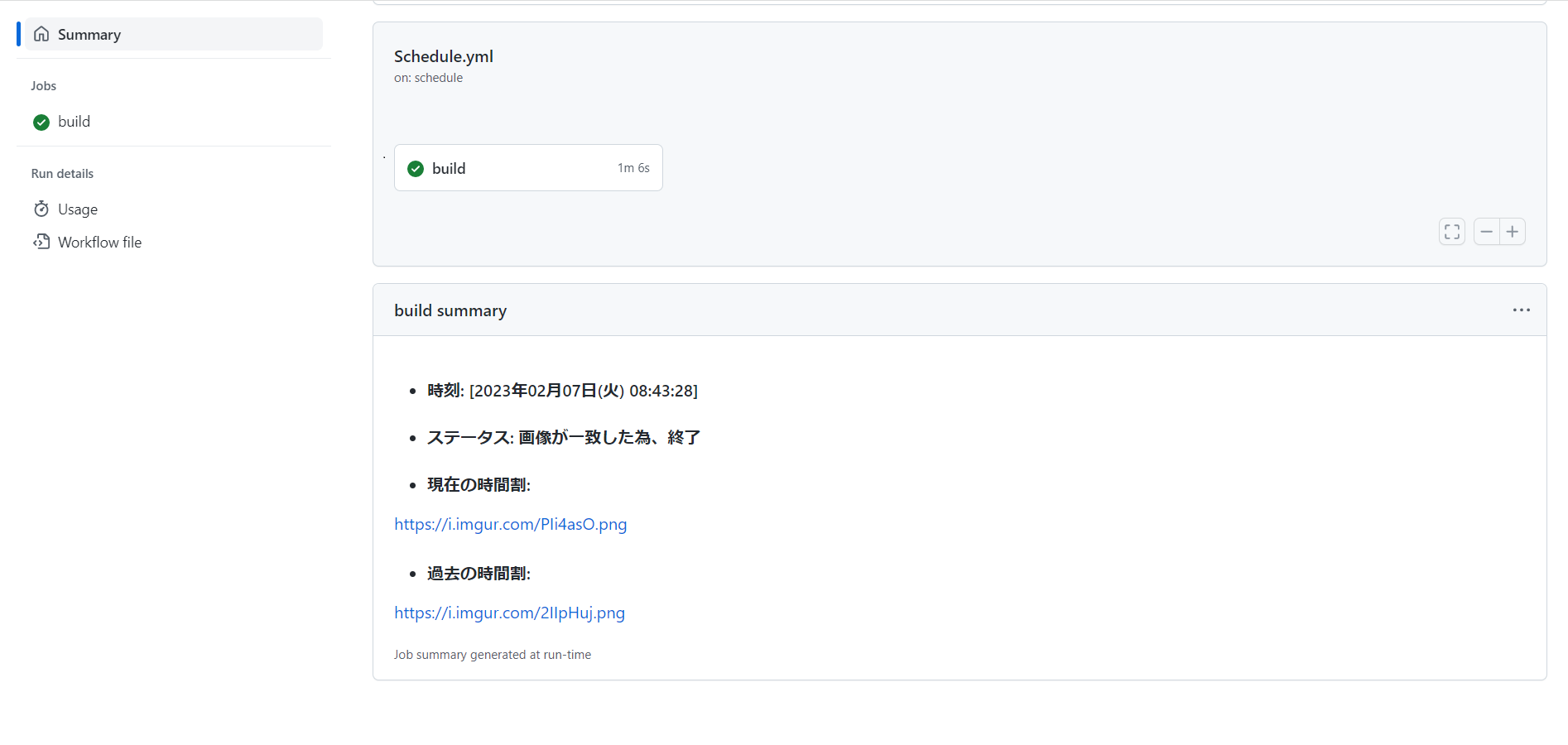
- Job Summaryについて
- ワークフロー内で、GITHUB_STEP_SUMMARY 環境変数を用いてワークフロー実行中の情報を出力できる
- 出力内容はワークフロー実行のサマリーページに表示(↓画像)
- 今回は
TIMEにtime_nowを代入
- 参考URL
# 日付取得
date = datetime.datetime.utcnow() + datetime.timedelta(hours=9) # 標準時+9時間
weekdays = ['月', '火', '水', '木', '金', '土', '日']
time_now = date.strftime('[%Y年%m月%d日(' + weekdays[date.weekday()] + ') %H:%M:%S]') # 表記変更
subprocess.run([f'echo "TIME={time_now}" >> $GITHUB_OUTPUT'], shell=True) # Job Summary用
# ログ設定
logger = getLogger(__name__)
logger.setLevel(DEBUG)
handler = StreamHandler()
format = Formatter('[%(asctime)s] [%(levelname)s] %(message)s')
handler.setFormatter(format)
logger.addHandler(handler)- Googleスプレッドシート
- Googleスプレッドシートにログインするためのファイルの準備
-
os.environ['JSON']=sercrets.- 変数の中身は○参照
# jsonファイル準備(SpreadSheetログイン用)
dic = ast.literal_eval(os.environ['JSON']) # 「JSON」という環境変数から値取得
with open('gss.json', mode='wt', encoding='utf-8') as file: # Googleログイン用JSONファイル作成
json.dump(dic, file, ensure_ascii=False, indent=2)
# keyの指定(情報漏えいを防ぐため伏せています)
consumer_key = os.environ['CONSUMER_KEY'] # TwitterAPI識別キー
consumer_secret = os.environ['CONSUMER_SECRET'] # TwitterAPI識別シークレットキー
access_token = os.environ['ACCESS_TOKEN'] # Twitterアカウントに対するアクセストークン
access_token_secret = os.environ['ACCESS_TOKEN_SECRET'] # Twitterアカウントに対するアクセストークンシークレット
# LINE,Discordのtoken設定(伏せています)
notify_group = os.environ['LINE_NOTIFY'] # 時間割LINEグループのトークン
notify_27 = os.environ['LINE_NOTIFY_27'] # 自分のクラスのライングループのトークン
notify_13 = os.environ['LINE_NOTIFY_13'] # 13組のライングループのトークン
webhook_url = os.environ['WEBHOOK'] # Discordの時間割サーバーのWebhookのURL
imgur = os.environ['IMGUR'] # 画像URL取得用- LINEの設定
- 複数のLINEグループに送信するため関数定義
-
line_access_token: LINE Notifyのトークン -
image: 送信したい画像のパス
- 終了時用
- デバッグメッセージ出力用
-
exit_message: 表示させたい文字列
- blob形式のURLの対策
- 一時期Googleスプレッドシート上にある画像のURLがBlob形式になっていた為用意
-
driver: ChromeDriver -
url: Blob形式のURL
- 参考URL
# LINEの設定
def line_notify(line_access_token, image):
line_url = 'https://notify-api.line.me/api/notify'
headers = {'Authorization': 'Bearer ' + line_access_token}
payload = {'message': '時間割が更新されました。'}
files = {'imageFile': open(image, 'rb')}
r = requests.post(line_url, headers=headers, params=payload, files=files)
return str(r.status_code) # ステータスコードを表示=>送信成功したか確認
# 終了時用
def finish(exit_message):
logger.info(f'{exit_message}\n')
subprocess.run([f'echo STATUS={exit_message} >> $GITHUB_OUTPUT'], shell=True)
exit()
# Imgurアップロード
def upload_imgur(image):
headers = {'authorization': f'Client-ID {imgur}'}
if 'http' in image:
with urllib.request.urlopen(image) as web_file:
time.sleep(3)
data = web_file.read()
with open('imgur.png', mode='wb') as local_file:
local_file.write(data)
image = 'imgur.png'
files = {'image': (open(image, 'rb'))}
time.sleep(2)
r = requests.post('https://api.imgur.com/3/upload', headers=headers, files=files)
r.raise_for_status()
return json.loads(r.text)['data']['link']
# blob形式のURLの対策
def get_blob_file(driver, url):
js = """
var getBinaryResourceText = function(url) {
var req = new XMLHttpRequest();
req.open('GET', url, false);
req.overrideMimeType('text/plain; charset=x-user-defined');
req.send(null);
if (req.status != 200) return '';
var filestream = req.responseText;
var bytes = [];
for (var i = 0; i < filestream.length; i++){
bytes[i] = filestream.charCodeAt(i) & 0xff;
}
return bytes;
}
"""
js += "return getBinaryResourceText(\"{url}\");".format(url=url)
data_bytes = driver.execute_script(js)
with open('blob.png', 'wb') as bin_out:
bin_out.write(bytes(data_bytes))
image = upload_imgur('blob.png')
return image- Seleniumを使ってChromeを起動してGoogleスプレッドシートに移動後、スプレッドシート上の画像を全て取得
- Selenium: Web ブラウザの操作を自動化するためのフレームワーク
- xpath指定やID指定で画像を直接取り出したかったがスプレッドシートは動的サイトなので諦め
- 代わりにタグで検索して画像を全て取得し、その後時間割の画像のみ抽出するように
- 参考URL
# Chromeヘッドレスモード起動
options = webdriver.ChromeOptions()
options.add_argument('--headless') # ヘッドレスモード(バックグラウンド)で起動
options.add_argument('--no-sandbox') # sandboxモード解除(クラッシュ防止)
options.add_argument('--disable-dev-shm-usage') # /dev/shmパーティションの使用を禁止=>パーティションが小さすぎることによるクラッシュ回避
driver = webdriver.Chrome('chromedriver', options=options) # ↑のオプションを設定し、Chrome起動
driver.implicitly_wait(5) # 処理待機
logger.info('セットアップ完了')
# Googleスプレッドシートへ移動(URLは伏せています)
driver.get(os.environ['GOOGLE_URL']) # 時間割の画像があるGoogleスプレッドシートへ移動(正直URL伏せる意味無い)
WebDriverWait(driver, 30).until(EC.presence_of_all_elements_located) # サイトを読み込み終わるまで待機
time.sleep(10)
# imgタグを含むものを抽出
imgs_tag = driver.find_elements(By.TAG_NAME, 'img') #「img」というタグの名前のものを全て抽出、リストへぶちこむ
if imgs_tag == []:
finish('画像が発見できなかったため終了(img無)') # リストが空(画像を発見できなかった)場合は終了
logger.info('imgタグ抽出\n')- 時間割の画像以外も取り出している場合があるため時間割の画像のみ抽出
- GoogleSpreadSheet上の画像は画像URLの末尾が「alr=yes」
# 時間割の画像のみ抽出
imgs_cv2u_now = [] # cv2u用リスト(現在)
imgs_url_now = [] # URLリスト(現在)
for index, e in enumerate(imgs_tag, 1):
img_url = e.get_attribute('src')
logger.info(f'{index}枚目: {img_url}')
# URLがBlob形式又は「alr=yes」が含まれる場合はImgurに画像アップロード
if ('blob:' in img_url) or ('alr=yes' in img_url):
if 'blob:' in img_url:
img_url = get_blob_file(driver, img_url)
else:
img_url = upload_imgur(img_url)
logger.info(f' → {img_url}')
if bool(str(cv2u.urlread(img_url)) in imgs_cv2u_now) == False:
logger.info(' → append')
imgs_cv2u_now.append(str(cv2u.urlread(img_url)))
imgs_url_now.append(img_url)
# 時間割の画像が見つからなかった場合は終了
if imgs_url_now == []:
finish('画像が発見できなかったため終了(alr=yes無)')
logger.info(f'現在の画像:{imgs_url_now}')
# $GITHUB_OUTPUTに追加
now = ','.join(imgs_url_now)
subprocess.run([f'echo NOW={now} >> $GITHUB_OUTPUT'], shell=True)- 最後に投稿した画像のURLがとあるスプレッドシートに保管されているため、そのURLの文字列を取得
# Google SpreadSheetsにアクセス
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
gc = gspread.authorize(ServiceAccountCredentials.from_json_keyfile_name('gss.json', scope))
ws = gc.open_by_key(os.environ['SHEET_ID']).sheet1
# 最後に投稿した画像のリストを読み込み
imgs_url_latest = ws.acell('C6').value.split() # URLリスト(過去)、シートのC6セルにURLがあるため取得
logger.info(f'過去の画像:{imgs_url_latest}\n')
imgs_cv2u_latest = [] # cv2u用リスト(過去)
for e in imgs_url_latest:
imgs_cv2u_latest.append(str(cv2u.urlread(e))) # 画像の枚数分画像データをimgs_cv2u_latestへ追加
# $GITHUB_OUTPUTに追加
before = ','.join(imgs_url_latest)
subprocess.run([f'echo BEFORE={before} >> $GITHUB_OUTPUT'], shell=True)
# 比較
if len(imgs_url_now) == len(imgs_url_latest): # 画像の枚数が同じ場合
if bool(set(imgs_cv2u_now) == set(imgs_cv2u_latest)) == True: # 画像データが同じ場合
finish('画像が一致した為、終了')
else:
logger.info('画像が一致しないので続行')
else:
logger.info('画像の枚数が異なるので続行')# 画像URLを使って画像をダウンロード
imgs_path = [] # ダウンロードする画像のパスを格納するリスト
for i in imgs_url_now:
with urllib.request.urlopen(i) as web_file:
time.sleep(5)
data = web_file.read()
img = str(imgs_url_now.index(i) + 1) + '.png' # 画像の名前を1.png,2.png,...とする
imgs_path.append(img)
with open(img, mode='wb') as local_file:
local_file.write(data)
# GoogleSpreadSheetsに画像URLを書き込み
ws.update_acell('C6', ' \n'.join(imgs_url_now))
ws.update_acell('C3', 'https://github.com/m1daily/Schedule_Bot/actions/runs/' + str(os.environ['RUN_ID']))
logger.info('画像DL完了、セル上書き完了\n')# tweepyの設定(認証情報を設定、APIインスタンスの作成)
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth, wait_on_rate_limit=True)
# ツイート
media_ids = []
for image in imgs_path:
img = api.media_upload(image) # 投稿できるように調整
media_ids.append(img.media_id)
api.update_status(status='時間割が更新されました!', media_ids=media_ids)
logger.info('・Twitter: ツイート完了')
# LINEへ通知
line_dict = {'公式グループ' : notify_group, '27組' : notify_27, '13組' : notify_13}
print('\n[LINE]')
for key, value in line_dict.items():
for i, image in enumerate(imgs_path, 1):
logger.info(f'{key}-{i}枚目: {line_notify(value, image)}')
# DiscordのWebhookを通して通知
payload2 = {'payload_json' : {'content' : '@everyone\n時間割が更新されました。'}}
embed = []
# 画像の枚数分"embed"の値追加
for i in imgs_url_now:
if imgs_url_now.index(i) == 0:
img_embed = {'color' : 10931421, 'url' : 'https://www.google.com/', 'image' : {'url' : i}}
else:
img_embed = {'url' : 'https://www.google.com/', 'image' : {'url' : i}}
embed.append(img_embed)
payload2['payload_json']['embeds'] = embed
payload2['payload_json'] = json.dumps(payload2['payload_json'], ensure_ascii=False)
res = requests.post(webhook_url, data=payload2)
print('Discord_Webhook: ' + str(res.status_code))
finish('投稿完了')- 環境変数
- リポジトリ内にあるファイル全てに使える変数
- Schedule.ymlでsecretを環境変数に入れている
- API
- 「Application Programming Interface」の略
- 自身の機能の一部をほかのプログラムで利用できるように公開する関数や手続きの集まり
- 簡潔に言うと、他サービスの機能連携
- TwitterAPIを導入するとPythonからツイートすることができたり、GoogleDriveAPIを導入するとPythonからファイルのアップロードができたりする