📢 YOUR SUPPORT IS GREATLY APPRECIATED / PATREON.COM/DONPABLONOW / BTC 3HVNOVVMLHVEWQLSCCQX9DUA26P5PRCTNQ / ETH 0X3D288C7A673501294C9289C6FC42480A2EA61417 🙏
⛔️ ARCHIVE PENDING: This endeavour is likely to fail owing to a lack of support. If you find this project interesting, please support it by smashing the "star" button. If the project receives at some interest work on the project will continue.
This project providers users the ability to do paraphrase generation for sentences through a clean and simple API. A demo can be seen here: pair-a-phrase
The paraphraser was developed under the Insight Data Science Artificial Intelligence program.
The underlying model is a bidirectional LSTM encoder and LSTM decoder with attention trained using Tensorflow. Downloadable link here: paraphrase model
- python 3.5
- Tensorflow 1.4.1
- spacy
Download the model checkpoint from the link above and run:
python inference.py --checkpoint=<checkpoint_path/model-171856>
The dataset used to train this model is an aggregation of many different public datasets. To name a few:
- para-nmt-5m
- Quora question pair
- SNLI
- Semeval
- And more!
I have not included the aggregated dataset as part of this repo. If you're curious and would like to know more, contact me. Pretrained embeddings come from John Wieting's para-nmt-50m project.
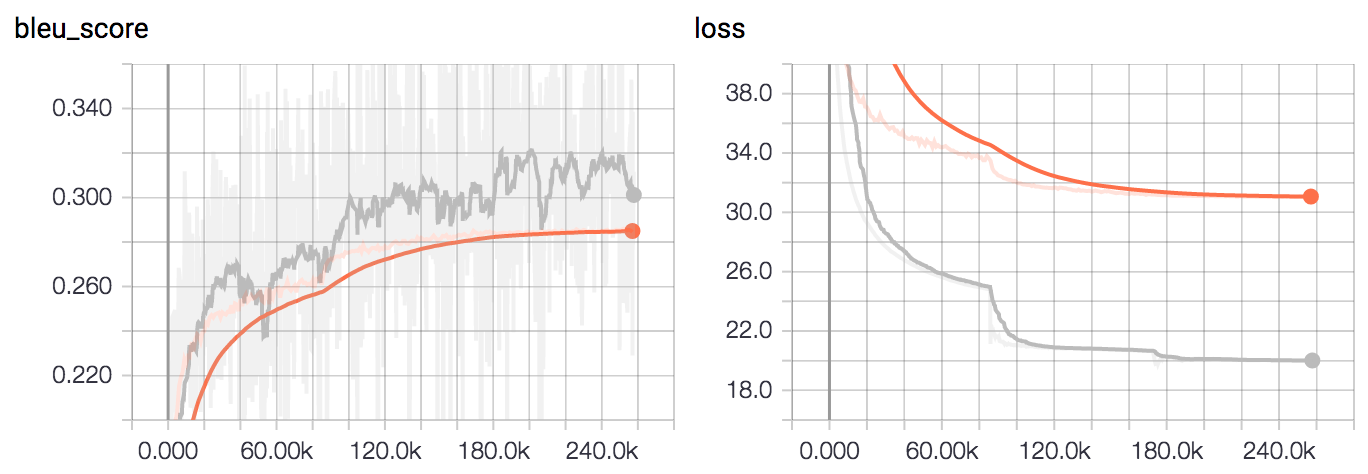
Training was done for 2 epochs on a Nvidia GTX 1080 and evaluted on the BLEU score. The Tensorboard training curves can be seen below. The grey curve is train and the orange curve is dev.
- pip installable package
- Explore deeper number of layers
- Recurrent layer dropout
- Greater dataset augmentation
- Try residual layer
- Model compression
- Byte pair encoding for out of set vocabulary
@inproceedings { wieting-17-millions,
author = {John Wieting and Kevin Gimpel},
title = {Pushing the Limits of Paraphrastic Sentence Embeddings with Millions of Machine Translations},
booktitle = {arXiv preprint arXiv:1711.05732}, year = {2017}
}
@inproceedings { wieting-17-backtrans,
author = {John Wieting, Jonathan Mallinson, and Kevin Gimpel},
title = {Learning Paraphrastic Sentence Embeddings from Back-Translated Bitext},
booktitle = {Proceedings of Empirical Methods in Natural Language Processing},
year = {2017}
}