statusupdate 032014
Michael Haberler, 03/2014
It’s been a while since I have given the last update on my work. Also, I am a bit late in my plan. So it’s time to report where I am.
What has taken me longer than I thought? Late last fall, there were some initial results on replacing NML within task, and that worked just fine - no surprises. However it turned out that progressing down this lane would have meant to continue the initial style I had adopted in this task application example - namely literally replacing NML by equivalent protobuf messages, and replacing NML transport operations by zeroMQ equivalents. While that is possible, this route results in a rather low-level replacement of one vehicle by the other; moreover it does not make good use of the advanced communication patterns available in zeroMQ. Therefore I stood back from this initial attempt, and reconsidered how one would redesign the interaction with those means in hand. As a consequence, I’ve turned to laying out the communication patterns between realtime and non-realtime more clearly, and the result were the protocol specificiaton documents (HAL Remote Components, and Status Tracking Protocol) which I posted a while ago. Those enable interaction with HAL at the pin and signal level with HAL groups and HAL remote components; for instance, that is already the basis for making gladevcp operate remotely. I also did an initial implementation of these protocols in Python to verify functionality; I did show a video of gladevcp operating remotely over the HALrcomp protocol a while ago: https://www.youtube.com/watch?v=vBynH_5KyPQ . The HAL side of these protocols is now redone in C++, and pretty much ready for use; I call it 'haltalk' - more below.
In the discussion below, it helps to face the fact that the realtime part of LinuxCNC, and the rest, interact via two fundamentally different patterns. Those are:
-
pattern 1: instantaneous interaction with HAL scalars (pins+signals). This interaction is on the level of individual scalars; it is immediate in execution, and interactions are independent of each other.
-
pattern 2: queued interaction based on command/response messages. Those are not scalars but records of several values (e.g. line to X/Y/Z, arc to X/Y/Z etc). Queued commands are executed in sequence, and the generator of commands may be well ahead of the consumer (e.g. motion).
Examples for (1) in the existing code are some HAL library functions, like supported by halpr_find_pin_by_name(), halpr_find_signal_by_name() and so forth, but also the 'sets' and 'setp' commands in halcmd. The HAL Remote Component and STatus tracking protocols provide a public API for that, one that will work remotely and locally just alike.
It is important to note that pattern (2) has no public API in LinuxCNC; instead there is a single queued command channel between task and the motion component. It is undocumented, and not for the faint of heart in both reading and modification. A direct consequence of this fact is the situation that all queued command interaction has to go via this channel, and that has resulted in the undesirable complexity of both motion and its driving side. There is also no means to address more than one component of this style, like by a name (on the HAL pattern (1) one always has HAL names at hand to address a particular pin or signal; there is no equivalent for queued interaction, like 'send a command to component X', now 'send a command to component Y'. The current scheme has no 'X' or 'Y'. Besides having no API, that non-existent API also is not remote-capable ;).
Another side effect of the current 'there can only be one' approach with the motion component is what I call the 'composition problem': HAL’s success rests on the ability to decompose a task into primitive components, and wire them together with linking pins. There is no such capability at the queued command interaction level: we have a single component which has to do it all, and be supremely clever about it: motion control, trajectory planning, homing, various modes and so forth. There is just no way to farm out a single task - like for instance the homing process - into a specialized, and replaceable component.
So (1) has a working solution, but (2) was unaddressed. The solution I came up with is outlined here: https://github.com/mhaberler/messagebus/wiki/Message-Bus-Overview - I call it messagebus. The key differences over the current non-API are:
-
An arbitrary number of realtime components, as well as non-realtime 'actors' (they need not even be HAL components) may take part in the messaging game.
-
Actors are identified by a name (a string). This name enables one to address a message to a component, i.e. route the command to a particular target, and route back a response to the originator.
-
While at it, this also solves the composition problem: not only can an arbitrary number of actors be talked to from the driving layer (e.g. task and interpreter, or UI); actors may also rely on each other to provide functionality based on division of labor, and specialisaton. The idea here is to replicate the idea of HAL composition of components at the queued command execution level.
Here too I did an initial Python proof-of-concept, and redid eventually in C++ for performance reasons. This works as expected but is not as mature as haltalk; in particular two items are missing; for the first, I am awaiting a key contribution from another co-djihadi. The second workitem is to add credit-based flow control to messagebus; it is clear how this will work, it just needs doing: http://hintjens.com/blog:15 .
Besides linking command-oriented userland and RT-components, Messagebus provides a natural place to plug in actors which may not even reside within the realtime scope, but still interact with hardware. An example could be a farmed-out part of the motion controller, much like Yishin and others have done with their products. However, so far there was no 'standard place' to plug in a remote message based component; there now is. It is conceivable to use this API as a means to split off segment execution from motion into a remote piece of hardware, in effect removing substantial RT requirements from the host side. Note that interaction can still be end-to-end all the way down to Arduinos and PIC peripherals: there is a protobuf implementation geared for embedded low-memory environments which hooks into the rest of Messagbus without discernible difference: https://code.google.com/p/nanopb/ ; this is now part of the codebase, since it is used for protobuf handling both in RT, and can be reused for such applications.
The author of nanopb, Petteri Aimonen, was very supportive and adopted the changes I needed to integrate with LinuxCNC, among them build support and work to enable nanopb use in kernel modules. Nanopb is a very well supported package, and it is already used in commercial products, like a Garmin workout watch.
Both patterns now have an API which rests on the same foundation - a zeroMQ transport, and message formats defined via Google protobuf. Note that for both vehicles there’s a wide range of language bindings available, and it is perfectly doable to talk both API’s via Python only and no special C/C++ modules required (as was needed for NML which has no automatic language binding capability).
I will give interaction examples in due course; but any of them will be in the low-dozen-of-lines range of effort for basic interaction, i.e. comprehensible by mortals, and usable without C/C++ skills. No more NML rocket science.
If one wants to read up and get ready for what is coming, I would recommend:
-
work through the Google protobuf tutorial (Python; maybe C++) and get the gist how this tool works: https://developers.google.com/protocol-buffers/docs/tutorials
-
get the hang how zeroMQ works - the 'zeroMQ Guide' is very complete (and long) http://zguide.zeromq.org/page:all
Re zeroMQ - keep in mind the only sockets, and interaction patterns which will be used at the API level are ROUTER/DEALER and XPUB/XSUB.
One key aspect of the architecture overhaul is: the notion of periodic polling for value changes is history. Both interaction patterns (HAL and queued commands) support event-based interaction, and integration into event loops like Gtk, zeroMQ, QT, libev etc. The way this is achieved is to relegate all polling for values into the haltalk and messagebus servers; every interaction outside of RT is mesage based and hence supports non-busy wait. I expect this not only to reduce load generated by UI’s, but also to increase performance, because it is not necessary any more to choose a tradeoff between polling interval (overhead) and responsiveness.
A historic note: it would have been rather easy to make NML capable of this event-driven behavior - the mechanism to do so is available in Linux for a long time (eventfd). But I do not find it worth anymore to reanimate a piece of software which I consider dead.
Status reports should contain grandiose diagrams, and this one is no exception. So here goes.. it’s a lot of boxes and arrows, so a bit of walkthrough is on order:
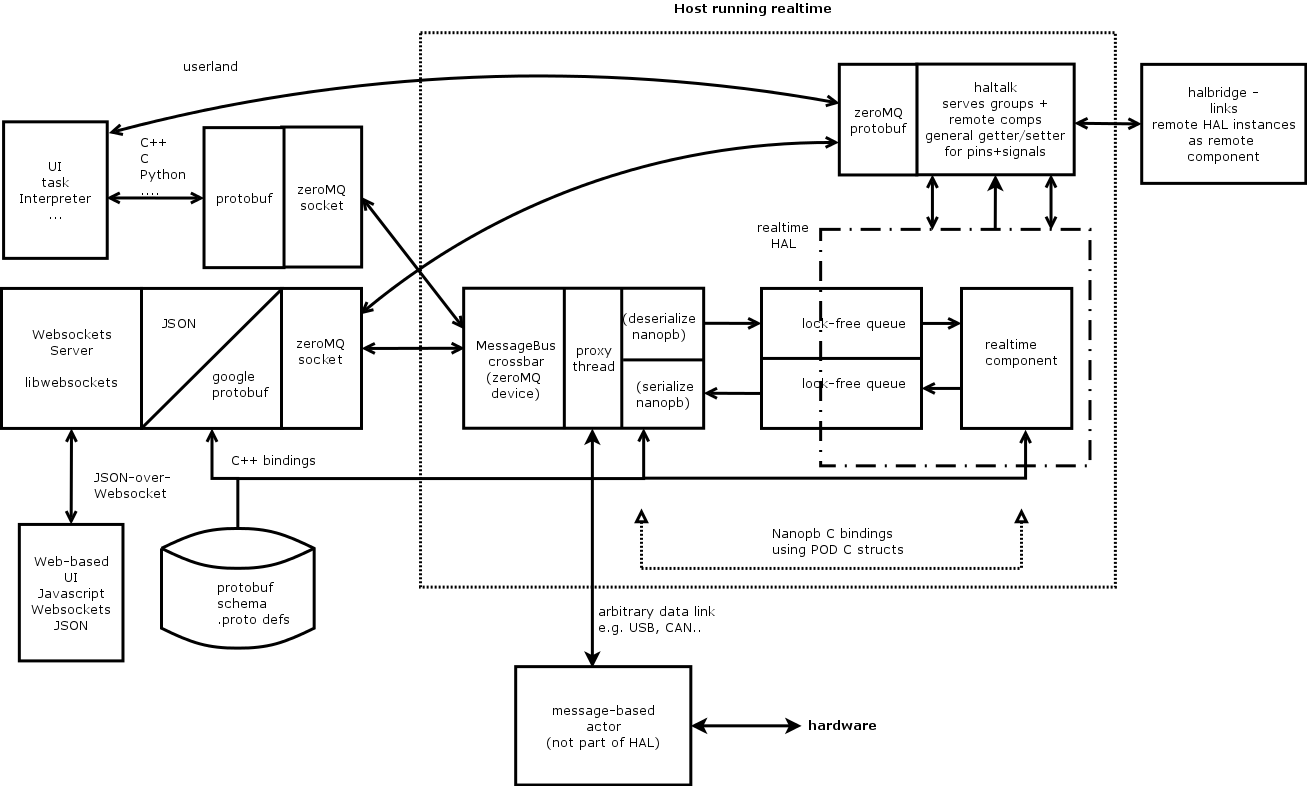
The two interaction API’s mentioned above are provided by two server processes, messagebus and haltalk. Messagebus handles queued command/response interaction; haltalk handles getting/setting of HAL pins+signals, reporting of changes in HAL groups, and interaction with remote components. Haltalk is also the natural place where bridging between remote HAL instances via a shared remote component happens (the latter is not implemented yet but poses no conceptual difficulties; all HAL library and messaging support is in place).
Each RT component which hooks into messagbus is served by a userland proxy thread which 'plays the zeroMQ game' towards the messagebus server, and talks to the RT component via two ringbuffers - one towards, one from RT.
The flow of a command/reply sequence from say task therefore would be: task injects a command message, including destination component name, into messagebus over a zeroMQ socket connection. Messagebus dispatches this command to the right proxy thread, which in turn shoves this down the ringbuffer towards the RT component. On the next thread invocation the component will detect a command being present in the ringbuffer, and act accordingly; eventually a reply message is passed from the component to the proxy thread through the second ringbuffer. The proxy thread picks it up, and injects it towards messagebus; the latter assures the originator (task) receives that reply (for details see the Messagebus document).
A non-HAL message-based actor like a farmed-out segment executor would hook into messagebus with a similar proxy thread; however, commands/replies would flow over a data link instead of ringbuffers, for instance USB, CAN, TCP.. whatever transports messages reliably from A to B. Messagebus is the place to 'plug in' command/response based actors regardless where they live.
The design follows the end-to-end principle: participants like RT comps or userland processes should generate, and understand messages (which are always in protobuf-encoded format); any intermediaries (messagebus, proxy) should not involve in transcoding or modifying any message but rather provide a transparent message pipe end-to-end. To support this, RT components understand, and can generate protobuf encoded messages, using the nanopb library already mentioned; nanopb has minimal environmental prerequisites and executes just fine in a userland RT or kernel module context.
There is one possible situation where a deviation from this end-to-end principle may be useful, and that is the case for high-frequencey, very large or very complex messages. In this (rare case) it would be possible to move the protobuf serialisation/deserialisation job to the proxy process; the latter runs in a userprocess context and hence is not timing-sensitive. I do not foresee this to be likely with any of the candidate components, but the ringbuffer message format flowing between an RT component and a proxy thread will support per-message indicators if a message is still in protobuf format, or already has been deserialized into a C struct; or the serialisation process still needs to be done on the way out from RT. Through the help of these flags that step can be moved between RT and proxy by configuration flags as needed.
The protobuf binding generator for nanopb can be told made to create fixed-size C structs corresponding to a particular protobuf message, which minimizes processing load in the RT thread.
The HAL library has been extended to support new named objects used here. Those are:
-
groups - named collections of signals as a unit of change detection and reporting
-
remote components - see the HALRcomp description
-
named ringbuffers. Those live outside components, and enable components to pass messages between them.
-
some generalized iterators to loop over collections of HAL objects.
What is a bit different in approach: HAL - at least in the case of groups and rcomps - is primarily used as a driving data structure for userland processes; the HAL library per se does nothing on itself with either. Corresponding extensions to halcmd permit describing groups and rcomps in halcmd, and server components later attach to HAL and retrieve these descriptions to provide a service.
One new programming paradigm I have used extensively, and also retrofitted into hal_lib.c is scoped locks. The reason is: with scoped locks it is practically impossible to 'forget to unlock a mutex' at every possible code exit. That alone has removed 95 calls to rtapi_mutex_give() in hal_lib.c.
Here is an example - first the support function in hal_lib.c
void halpr_autorelease_mutex(void *variable)
{
if (hal_data != NULL)
rtapi_mutex_give(&(hal_data->mutex));
else
// programming error
rtapi_print_msg(RTAPI_MSG_ERR,
"HAL:%d BUG: halpr_autorelease_mutex called before hal_data inited\n",
rtapi_instance);
}
Usage example:
{
hal_oldname_t *oldname __attribute__((cleanup(halpr_autorelease_mutex)));
/* get mutex before accessing shared data */
rtapi_mutex_get(&(hal_data->mutex));
...
}
Any way one exits from the scope where 'oldname' is visible, the mutex will be unlocked automatically; much harder to get wrong than covering all possible exits manually.
I view log messages as a form of data like any other; while logs should go to say a logfile, or a log server like syslogd, log messages should still be available for using code - without digging around in external files. The LinuxCNC NML support does include an error channel which was intended to provide this, but its design is rather poor with respect to the using side: any using code receiving a log/error message consumes that particular message, which means no other using component has a chance to see that message. That pattern is simply not very useful; the proper abstraction is a publish/subscribe pattern where each user receives and identical message stream regardless of what other using code sees.
Therefore, while logmessages are collected in rtapi_msgd, they are again made available over a zeroMQ publish socket by msgd, which provides exactly what is needed. Also, msgd will act as a reflector for such log messages - for instance UI, interpreter, task error messages will be sent to msgd over a zeroMQ socket, and both logged from there (yes! a single log mechanism at last), as well as made available to other using code via the publish socket.
This log hub function is not implemented yet but rather simple to add.
Web-based UI’s typically work via Javascript, and the natural form of data encoding is JSON. As a transport method, the Websockets protocol is the method of choice.
Past work towards web-based UI’s have taken the approach of supporting a JSON I/O capability be transcoding NML and HAL objects to/from JSON manually. Both Emcweb and Rockhopper follow this approach. But I view this as a violation of the end-to-end principle, with dire consequences: there is a lot of special-purpose code to provide this transcoding, and it is a serious limitation with respect to flexibility - to add another attribute, or command/response interaction, more C/C++ code is needed.
I follow a different - transparent proxying approach - based upon Pavels work of automatically transforming protobuf messages to and from JSON. This relies on the 'reflection' support in protobuf - basically protobuf is introspection-capable and provides the means to this transformation automatically: any valid protobuf message has a unique JSON representation, and a JSON object can be transformed automatically into a isomorphic protobuf message provided it is correct with respect to the message description.
In effect this means any protobuf message defined in a .proto file can be made available as/can be parsed from a JSON object, without any special purpose code.
What is left is how to push these JSON objects over websocket streams. To provide this function, I have added a simple websockets proxy based on libwebsockets; this takes care of the mapping of websockets streams towards any zeroMQ socket, as well as the transformation between JSON and protobuf messages. An initial implementation is complete and works as expected.
I’ve done some work with the author of libwebockets primarily to ease integration with the zeroMQ event loop.
Consider for a moment a future setup: this could well involve three 'hosts', maybe more: a realtime controller, an host running task and interpreter, a GUI - say on an Android tablet, and maybe more things hanging off realtime like Yishin’s controller. Each of those provide services, connect and talk to each other. While it is certainly possible to use the traditional inifile style of configuration, the distributed nature of such a setup makes management a bit unwieldy; in particular as soon as specifying IP addresses comes in, which may be rough going if dynamic IP address allocation - say with DHCP - is in use.
To simplify this task, I’ve added a simple UDP-based service discovery vehicle: each party in the game which exports a service listens on a UDP port for requests; a party desiring service - say for a particular linuxCNC instance - broadcasts a request, and collects response; those responses contain the zeroMQ URI’s to glue everything together. Not much different than DHCP - just at a higher level, and very effective in reducing configuration effort.
This exists as a library in C++ and Python, and is already part of rtapi_msgd, rtapi_app, messagebus and haltalk. No surprises to report.
An issue which I tend to address eventually is to deal with configuration and persistent values across LinuxCNC invocations in a coherent way. This will eventually replace the local per-host inifile scheme required now, and there might well be a single ini file which is made accessible to all parties over zeroMQ sockets. While at it, it makes sense to address the issue of tunable and persistent parameters.
The way I am thinking about this can be depicted like so:
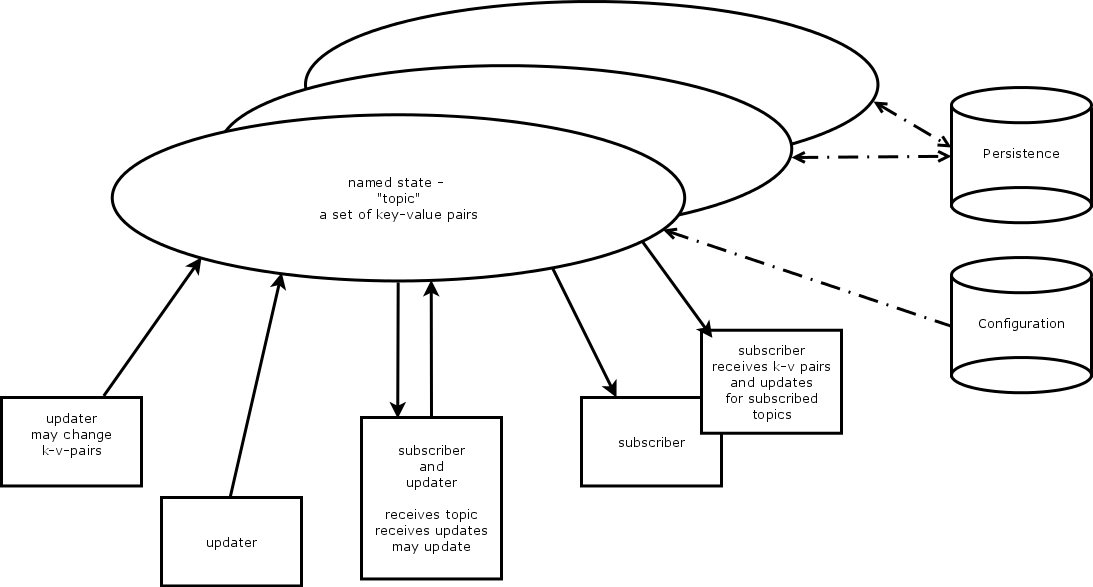
The idea is to provide a selective replication of state (you might think of this as sections with key-value pairs in an ini file). A using party would subscribe to 'its' section, and receive the pertinent set of key-value pairs - on whatever host that party happens to reside.
Parties may not only be read-only consumers, but also updaters of state: if a party chooses to modify a value, then that change is made available immediately through a zeroMQ update.
This state replication engine is also the natural place to provide persistent storage, like for instance interpreter parameters or machine positions which are expected to survive a shutdown/restart sequence. One option is to hook redis in here; note it does not matter which host this replications service, and redis would run.
This scheme would cover all of configuration, live tuning of parameters, and persistent storage through a single API, and get rid of the need for replicated config files, as well as current ad-hoc mechanisms for persistent state storage.
Right now, startup and shutdown of the RT environment is very flavor specific and somewhat intricate - this involves either inserting kernel modules, or starting the rtapi_app process; and the rtapi_msgd logging process. Also, the userland interface into RT - for instance to load a component, or start a thread - is flavor-specific too: it involves either talking to rtapi_app (userland flavors) or inserting a kernel module. And that difference is exported to halcmd 1:1.
Furthermore, the startup process involves a series of checks on the enviroment, and check of results before taking the next step as some startup phases are frought with race conditions. Some of these checks are rather awkward to do in a shell script.
This complexitiy is engraved in the scripts/realtime script, and it is not pretty. It is also prone to failure, and sensitive to platform differences.
My goal is to simplify and unifiy this RT startup/shutdown sequence like so:
-
rtapi_app will handle both userland and kernel threads startup and shutdown
-
rtapi_app gets a remote command interface for using code like halcmd, to insert/remove components, start/stop threads etc
-
the (minor) functionality provided by rtapi_msgd will be folded into rtapi_app as a thread.
-
startup and shutdown of the RT environment will involve only starting and stopping this RT demon, and nothing else
This step is mostly complete, except for folding msgd into rtapi_app. While I was at it, I also added a unform thread creation API which works for both kernel and userland threads, and will obviate the need for the threads component altogether.
You will notice the infrastructure plumbing part is fairly progressed; however I have not started upon actually modifying task and other using code to actually use it. The order I intend to work on this is:
-
complete messagebus, and add flow control
-
redo the gladevcp Python code to work with the protocol version as spoken by haltalk
-
actually start on rewriting task to use the new infrastructure.
The first two are straightforward and will result in say gladevcp applications usable remotely. That is already a useful step, and might warrant an intermediate snapshot release.
However, the third step is major. Again here is a question of "do you continue with the code as it stands, or do you restructure it first and then do the plumbing?".
I’ve decided to go a route which might be a bit controversial: before I retrofit the new plumbing into task I will restructure task as follows:
-
the interpreter will be spun out as either a separate thread or a separate process altogether; in either case zeroMQ API’S will be at the front and back side of the interpreter.
-
task will stop operating the interpreter explicitly, rather only tell it to run a command or file, or abort, and other than that only observe its status.
The justification for this step is: first, the control structure between task and interpreter is completely upside down as it stands - instead the interpreter telling task where it is, task gets to guess where it could be or not be, and call upon the interpreter for the next step. This control structure inversion has been a neverending source of MDI bugs, and has resulted in a disgusting patchwork in task which I consider beyond repair.
A side effect of this restructuring is a new API: the interpreter will be able to talk to say a UI during a run, i.e. without abort/restart/run from line, and say interact for parameters.
Another side effect is: it will become much easier to have more than one interpreter available, and that opens the route to MDI-while paused.
I do expect this restructuring step to take at least a month, maybe two, but the long-term upside warrants this step in my view. I hope to be able to provide a 'gladevcp remote only' snapshot in a much shorter timeframe; it is more about documenting the external build requisites than polishing activities.
Haltalk is where all the HAL pin and signal polling happens for change detection and reporting; this is the key step in replacing the NML EMC_STATUS structure. Now, reporting all of the HAL pins and signals may be quite a sizeable task; my back-of-the-envelope calculation suggests monitoring at least 500 pins/sigals should be possible without fear of a performance impact.
To check where we are, I did a setup with all of the halui pins (175 in my example) and had those monitored by haltalk. The ps output below shows resource consumption of this example over 10 seconds. Note that haltalk here consumes about as much cycles as halui, and 25% of the hal_manualtoolchange component. In other words, CPU and memory usage is completely negligable - this will easily scale beyond 1000 pins and even then not even having reached the order of the CPU usage of the RT environment or axis. So we are on safe ground with respect to haltalk performance (messagebus uses even less resources):
Swap: 1113084 total, 226488 used, 886596 free, 378808 cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 11432 mah 20 0 159m 56m 26m R 29.1 3.7 0:25.59 axis 11387 root 20 0 68952 65m 10m S 22.0 4.3 0:29.78 rtapi:0 2462 root 20 0 282m 57m 6572 R 21.2 3.8 132:30.27 Xorg 11431 mah 20 0 44296 14m 11m S 3.1 0.9 0:04.10 milltask 11417 mah 20 0 45956 18m 11m S 2.0 1.2 0:03.18 hal_manualtoolc 11472 mah 20 0 45668 11m 4356 S 1.4 0.7 0:00.97 python 11398 mah 20 0 5052 2024 1800 S 1.1 0.1 0:01.34 halui 11467 mah 20 0 35044 3916 3548 S 1.1 0.3 0:01.01 haltalk <------------ 28168 mah 20 0 30108 13m 5036 S 1.1 0.9 7:03.08 wish
(irrelevant processes deleted)