


Upgrading from the previous version? Use a Migration Guide.
Nuke provides a simple and efficient way to download and display images in your app. Behind its clear and concise API is an advanced architecture which enables its unique features and offers virtually unlimited possibilities for customization.
Fast LRU memory and disk cache · Smart background decompression · Image processing · Resumable downloads · Intelligent deduplication · Request prioritization · Prefetching · Rate limiting · Progressive JPEG, WebP · Animated images · Alamofire, WebP, Gifu, FLAnimatedImage integrations · Reactive extensions
Nuke is easy to learn and use. Here is an overview of its APIs and features:
- Image View Extensions ‣ Load and Display Image | Placeholders, Transitions, Content Modes |
ImageRequest - Image Processing ‣
Resize|GaussianBlur, Core Image | Custom Processors | Smart Decompression - Image Pipeline ‣ Load Image |
ImageTask| Customize Image Pipeline | Default Pipeline - Caching ‣ LRU Memory Cache | HTTP Disk Cache | Aggressive LRU Disk Cache
- Advanced Features ‣ Preheat Images | Progressive Decoding | Animated Images | WebP | RxNuke
To learn more see a full API Reference, and check out the demo project included in the repository. When you are ready to install, follow the Installation Guide. See Requirements for a list of supported platforms.
To learn about the image pipeline itself, see the dedicated section:
- Image Pipeline ‣ Overview | Data Loading and Caching | Resumable Downloads | Memory Cache | Deduplication | Performance | Extensions
If you'd like to contribute to Nuke see Contributing.
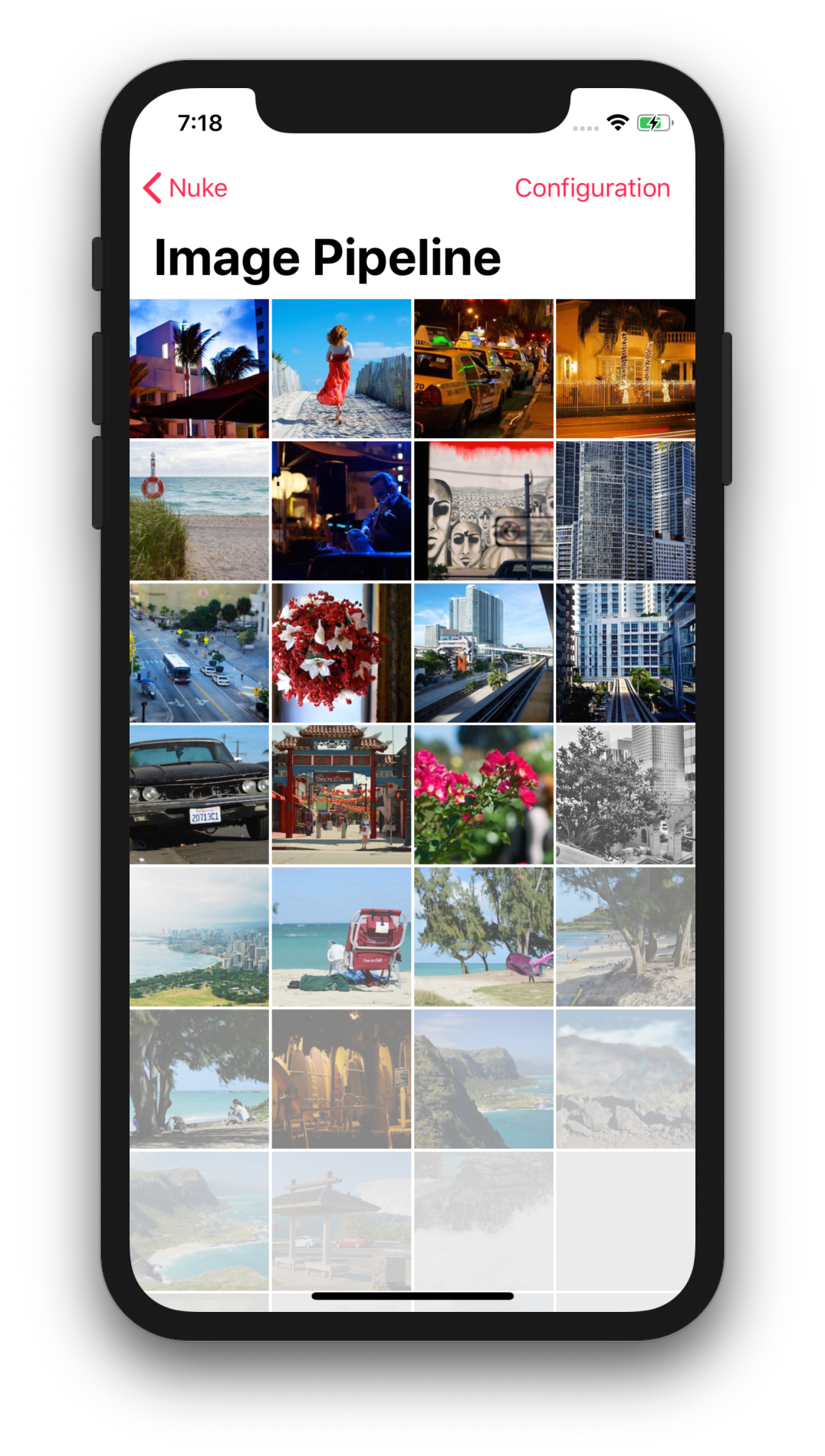
Download and display an image in an image view with a single line of code:
Nuke.loadImage(with: url, into: imageView)Nuke will check if the image exists in the memory cache, and if it does, will instantly display it. If not, the image data will be loaded, decoded, processed, and decompressed in the background.
See Image Pipeline Overview to learn more.
When you request a new image for the existing view, Nuke will prepare it for reuse and cancel any outstanding requests for the view. Mangaging images in lists has never been easier.
func collectionView(_ collectionView: UICollectionView,
cellForItemAt indexPath: IndexPath)
-> UICollectionViewCell {
Nuke.loadImage(with: url, into: cell.imageView)
}The requests also get canceled automatically when the views are deallocated. Call
Nuke.cancelRequest(for: imageView)to cancel the request manually.
Use ImageLoadingOptions to set a placeholder, select one of the built-in transitions, or provide a custom one.
let options = ImageLoadingOptions(
placeholder: UIImage(named: "placeholder"),
transition: .fadeIn(duration: 0.33)
)
Nuke.loadImage(with: url, options: options, into: imageView)You can even customize content modes per image type:
let options = ImageLoadingOptions(
placeholder: UIImage(named: "placeholder"),
failureImage: UIImage(named: "failureImage"),
contentModes: .init(success: .scaleAspectFill, failure: .center, placeholder: .center)
)In case you want all image views to have the same behavior, you can modify
ImageLoadingOptions.shared.
ImageRequest allows you to set image processors, change the request priority and more:
let request = ImageRequest(
url: URL(string: "http://..."),
processors: [ImageProcessor.Resize(size: imageView.bounds.size)],
priority: .high
)Another way to apply processors is by setting the default
processorsonImagePipeline.Configuration. These processors will be applied to all images loaded by the pipeline. If the request has a non-empty array ofprocessors, they are going to be applied instead.
The advanced options available via ImageRequestOptions. For example, you can provide a filteredURL to be used as a key for caching in case the URL contains transient query parameters.
let request = ImageRequest(
url: URL(string: "http://example.com/image.jpeg?token=123")!,
options: ImageRequestOptions(
filteredURL: "http://example.com/image.jpeg"
)
)There are more options available, to see all of them check the inline documentation for
ImageRequestOptions.

Nuke features a powerful and efficient image processing infrastructure with multiple built-in processors including ImageProcessor.Resize, .Circle, .RoundedCorners, .CoreImageFilter, .GaussianBlur.
This and other screenshots are from the demo project included in the repo.
To resize an image, use ImageProcessor.Resize:
ImageRequest(url: url, processors: [
ImageProcessor.Resize(size: imageView.bounds.size)
])By default, the target size is in points. When the image is loaded, Nuke will scale it to fill the target area maintaining the aspect ratio. To crop the image set crop to true.
There are a few other options available, see
ImageProcessor.Resizedocumentation for more info.
ImageProcessor.GaussianBlur blurs the input image. It is powered by the native CoreImage framework. To apply other filters, use ImageProcessor.CoreImageFilter:
ImageProcessor.CoreImageFilter(name: "CISepiaTone")For a complete list of Core Image filters see Core Image Filter Reference.
Custom processors need to conform to ImageProcessing protocol:
public protocol ImageProcessing {
var identifier: String { get }
var hashableIdentifier: AnyHashable { get }
func process(image: Image, context: ImageProcessingContext?) -> Image?
}The process method is self-explanatory. identifier: String is used by disk caches, and hashableIdentifier: AnyHashable is used by memory caches for which string manipulations would be too slow.
For one-off operations, use ImageProcessor.Anonymous to create a processor with a closure.
When you instantiate UIImage with Data, the data can be in a compressed format like JPEG. UIImage does not eagerly decompress this data until you display it. This leads to performance issues like scroll view stuttering. To avoid these it, Nuke automatically decompresses the data in the background. Decompression only runs if needed, it won't run for already processed images.
See Image and Graphics Best Practices to learn more about image decoding and downsampling.
At the core of Nuke is the ImagePipeline class. Use the pipeline directly to load images without displaying them:
let task = ImagePipeline.shared.loadImage(
with: url,
progress: { _, completed, total in
print("progress updated")
},
completion: { result: Result<ImageResponse, ImagePipeline.Error> in
print("task completed")
}
)To download the data without doing any expensive decoding or processing, use
loadData(with:progress:completion:).
When you start the request, the pipeline returns an ImageTask object, which can be used for cancelation and more.
task.cancel()
task.priority = .highIf you want to build a system that fits your specific needs, you won't be disappointed. There are a lot of things to tweak. You can set custom data loaders and caches, configure image encoders and decoders, change the number of concurrent operations for each individual stage, disable and enable features like deduplication and rate limiting, and more.
To learn more see the inline documentation for
ImagePipeline.Configurationand Image Pipeline Overview.
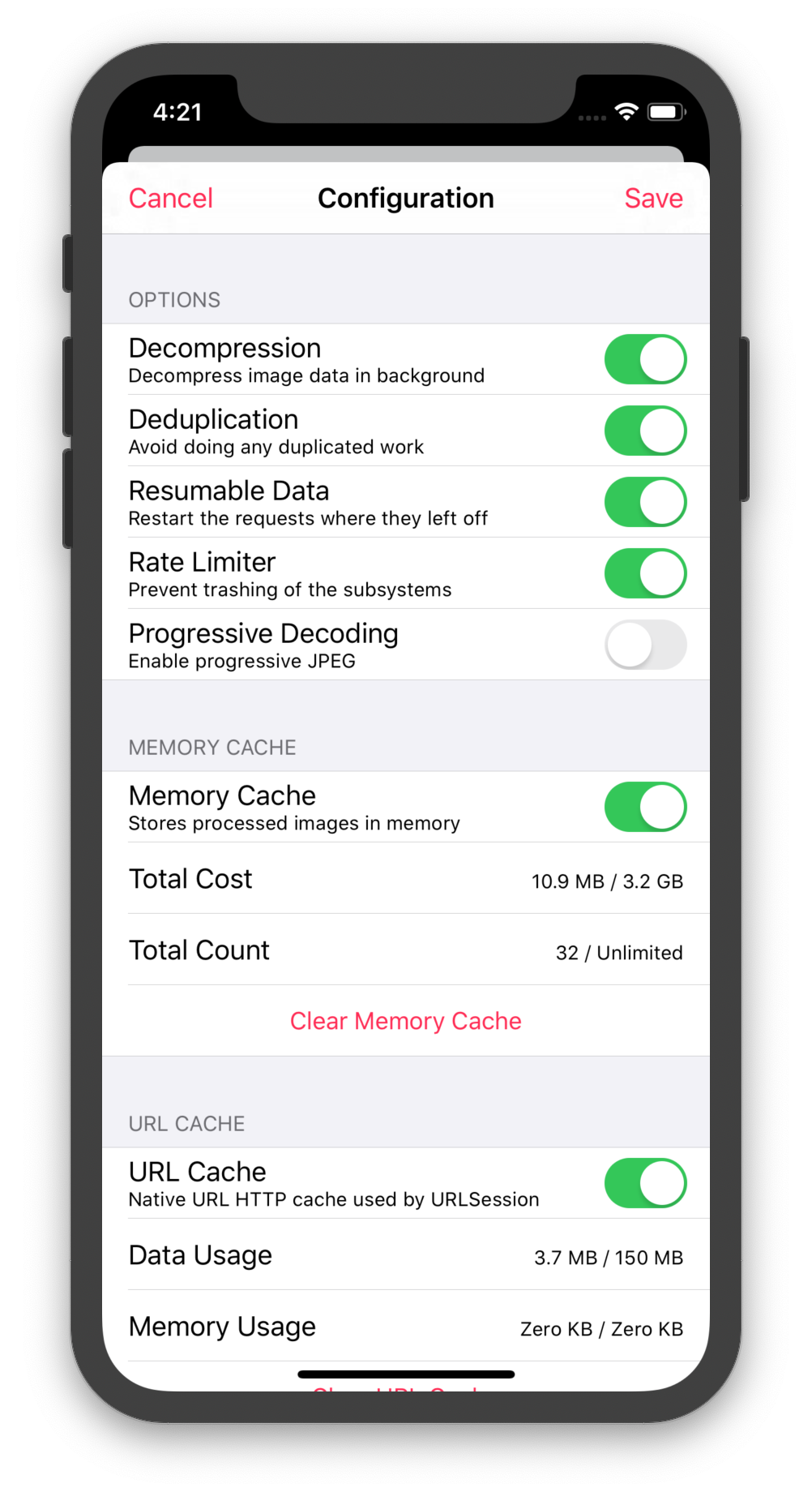
Here are the protocols which can be used for customization:
DataLoading– Download (or return cached) image dataDataCaching– Store image data on diskImageDecoding– Convert data into imagesImageEncoding- Convert images into dataImageProcessing– Apply image transformationsImageCaching– Store images into a memory cache
The entire configuration is described by the ImagePipeline.Configuration struct. To create a pipeline with a custom configuration either call the ImagePipeline(configuration:) initializer or use the convenience one:
let pipeline = ImagePipeline {
$0.dataLoader = ...
$0.dataLoadingQueue = ...
$0.imageCache = ...
...
}And then set the new pipeline as default:
ImagePipeline.shared = pipelineThe default image pipeline is initialized with the following dependencies:
// Shared image cache with a size limit of ~20% of available RAM.
imageCache = ImageCache.shared
// Data loader with a default `URLSessionConfiguration` and a custom `URLCache`
// with memory capacity 0, and disk capacity 150 MB.
dataLoader = DataLoader()
// Custom aggressive disk cache is disabled by default.
dataCache = nil
// By default uses the decoder from the global registry and the default encoder.
makeImageDecoder = { context in ImageDecoderRegistry.shared.decoder(for: context) }
makeImageEncoder = { _ in ImageEncoder() }Each operation in the pipeline runs on a dedicated queue:
dataLoadingQueue.maxConcurrentOperationCount = 6
dataCachingQueue.maxConcurrentOperationCount = 2
imageDecodingQueue.maxConcurrentOperationCount = 1
imageEncodingQueue.maxConcurrentOperationCount = 1
imageProcessingQueue.maxConcurrentOperationCount = 2
imageDecompressingQueue.maxConcurrentOperationCount = 2There is a list of pipeline settings which you can tweak:
// Automatically decompress images in the background by default.
isDecompressionEnabled = true
// Configure which images to store in the custom disk cache.
isDataCachingForOriginalImageDataEnabled = true
isDataCachingForProcessedImagesEnabled = false
// Avoid doing any duplicated work when loading or processing images.
isDeduplicationEnabled = true
// Rate limit the requests to prevent trashing of the subsystems.
isRateLimiterEnabled = true
// Progressive decoding is an opt-in feature because it is resource intensive.
isProgressiveDecodingEnabled = false
// If the data task is terminated (either because of a failure or a
// cancellation) and the image was partially loaded, the next load will
// resume where it was left off.
isResumableDataEnabled = trueAnd also a few global options shared between all pipelines:
ImagePipeline.Configuration.isAnimatedImageDataEnabled = false
// Enable to start using `os_signpost` to monitor the pipeline
// performance using Instruments.
ImagePipeline.Configuration.isSignpostLoggingEnabled = falseNuke's default ImagePipeline has two cache layers.
First, there is a memory cache for storing processed images which are ready for display.
// Configure cache
ImageCache.shared.costLimit = 1024 * 1024 * 100 // 100 MB
ImageCache.shared.countLimit = 100
ImageCache.shared.ttl = 120 // Invalidate image after 120 sec
// Read and write images
let request = ImageRequest(url: url)
ImageCache.shared[request] = image
let image = ImageCache.shared[request]
// Clear cache
ImageCache.shared.removeAll()ImageCache uses the LRU algorithm – least recently used entries are removed first during the sweep.
Unprocessed image data is stored with URLCache.
// Configure cache
DataLoader.sharedUrlCache.diskCapacity = 100
DataLoader.sharedUrlCache.memoryCapacity = 0
// Read and write responses
let request = ImageRequest(url: url)
let _ = DataLoader.sharedUrlCache.cachedResponse(for: request.urlRequest)
DataLoader.sharedUrlCache.removeCachedResponse(for: request.urlRequest)
// Clear cache
DataLoader.sharedUrlCache.removeAllCachedResponses()If HTTP caching is not your cup of tea, you can try using a custom LRU disk cache for fast and reliable aggressive data caching (ignores HTTP cache control). You can enable it using the pipeline configuration.
ImagePipeline {
$0.dataCache = try! DataCache(name: "com.myapp.datacache")
// Also consider disabling the native HTTP cache, see `DataLoader`.
}By default, the pipeline stores only the original image data. To store the processed images enable isDataCachingForProcessedImagesEnabled and also consider disabling isDataCachingForOriginalImageDataEnabled. Every intermediate processed image will be stored in cache. So in the following scenario, there are going to be two entries in the disk cache (three if original image cache is also enabled):
let request = ImageRequest(url: url, processors: [
ImageProcessor.Resize(size: imageView.bounds.size),
ImageProcessor.CoreImageFilter(name: "CISepiaTone")
])To avoid storing unwanted images, compose the processors, ImageProcessor.Composition is an easy way to do it.
Prefetching images in advance can dramatically improve your app's user experience.
let preheater = ImagePreheater()
preheater.startPreheating(with: urls)
// Cancels all of the preheating tasks created for the given requests.
preheater.stopPreheating(with: urls)Keep in mind that prefetching takes up users' data and puts extra pressure on CPU and memory. To reduce the CPU and memory usage, you have an option to choose only the disk cache as a prefetching destination:
// The preheater with `.diskCache` destination will skip image data decoding
// entirely to reduce CPU and memory usage. It will still load the image data
// and store it in disk caches to be used later.
let preheater = ImagePreheater(destination: .diskCache)On iOS, you can use prefetching APIs in combination with
ImagePreheaterto automate the process.
To enable progressive image decoding set isProgressiveDecodingEnabled configuration option to true.

let pipeline = ImagePipeline {
$0.isProgressiveDecodingEnabled = true
}And that's it, the pipeline will automatically do the right thing and deliver the progressive scans via progress closure as they arrive:
let imageView = UIImageView()
let task = ImagePipeline.shared.loadImage(
with: url,
progress: { response, _, _ in
if let response = response {
imageView.image = response?.image
}
},
completion: { result in
// Display the final image
}
)Nuke extends UIImage with an animatedImageData property. To enable it, set ImagePipeline.Configuration.isAnimatedImageDataEnabled to true. If you do, the pipeline will start attaching the original image data to the animated images.
There is no built-in way to render those images, but there are two extensions available: FLAnimatedImage and Gifu which are both fast and efficient.
GIFis not the most efficient format for transferring and displaying animated images. The current best practice is to use short videos instead of GIFs (e.g.MP4,WebM). There is a PoC available in the demo project which uses Nuke to load, cache and display anMP4video.
WebP support is provided by Nuke WebP Plugin built by Ryo Kosuge. Please follow the instructions from the repo.
RxNuke adds RxSwift extensions for Nuke and enables common use cases: Going from low to high resolution | Loading the first available image | Showing stale image while validating it | Load multiple images, display all at once | Auto retry on failures | And more
To get a taste of what you can do with this extension, take a look at how easy it is to load the low resolution image first and then switch to high resolution:
let pipeline = ImagePipeline.shared
Observable.concat(pipeline.loadImage(with: lowResUrl).orEmpty,
pipeline.loadImage(with: highResUtl).orEmpty)
.subscribe(onNext: { imageView.image = $0 })
.disposed(by: disposeBag)This section describes in detail what happens when you perform a call like Nuke.loadImage(with: url, into: view).
As a visual aid, use this Block Diagram.
{kind=link}
First, Nuke synchronously checks if the image is stored in the memory cache. If the image is not in memory, Nuke calls pipeline.loadImage(with: request).
The pipeline first checks if the image or image data exists in any of its caches. It checks if the processed image exists in the memory cache, then if the processed image data exists in the custom data cache (disabled by default), then if the data cache contains the original image data. Only if there is no cached data, the pipeline will start loading the data. When the data is loaded the pipeline decodes it, applies the processors, and decompresses the image in the background.
A DataLoader class uses URLSession to load image data. The data is cached on disk using URLCache, which by default is initialized with memory capacity of 0 MB (only stores processed images in memory) and disk capacity of 150 MB.
See Image Caching Guide to learn more about HTTP cache.
The URLSession class natively supports the following URL schemes: data, file, ftp, http, and https.
Most developers either implement their own networking layer or use a third-party framework. Nuke supports both of these workflows. You can integrate your custom networking layer by implementing DataLoading protocol.
See Third Party Libraries guide to learn more. See also Alamofire Plugin.
If the data task is terminated (either because of a failure or a cancelation) and the image was partially loaded, the next load will resume where it was left off. Resumable downloads require the server to support HTTP Range Requests. Nuke supports both validators (ETag and Last-Modified). The resumable downloads are enabled by default.
The processed images are stored in a fast in-memory cache (ImageCache). It uses LRU (least recently used) replacement algorithm and has a limit of ~20% of available RAM. ImageCache automatically evicts images on memory warnings and removes a portion of its contents when the application enters background mode.
The pipeline avoids doing any duplicated work when loading images. For example, let's take these two requests:
let url = URL(string: "http://example.com/image")
pipeline.loadImage(with: ImageRequest(url: url, processors: [
ImageProcessor.Resize(size: CGSize(width: 44, height: 44)),
ImageProcessor.GaussianBlur(radius: 8)
]))
pipeline.loadImage(with: ImageRequest(url: url, processors: [
ImageProcessor.Resize(size: CGSize(width: 44, height: 44))
]))Nuke will load the data only once, resize the image once and blur it also only once. There is no duplicated work done. The work only gets cancelled when all the registered requests are, and the priority is based on the highest priority of the registered requests.
Deduplication can be disabled using
isDeduplicationEnabledconfiguration option.
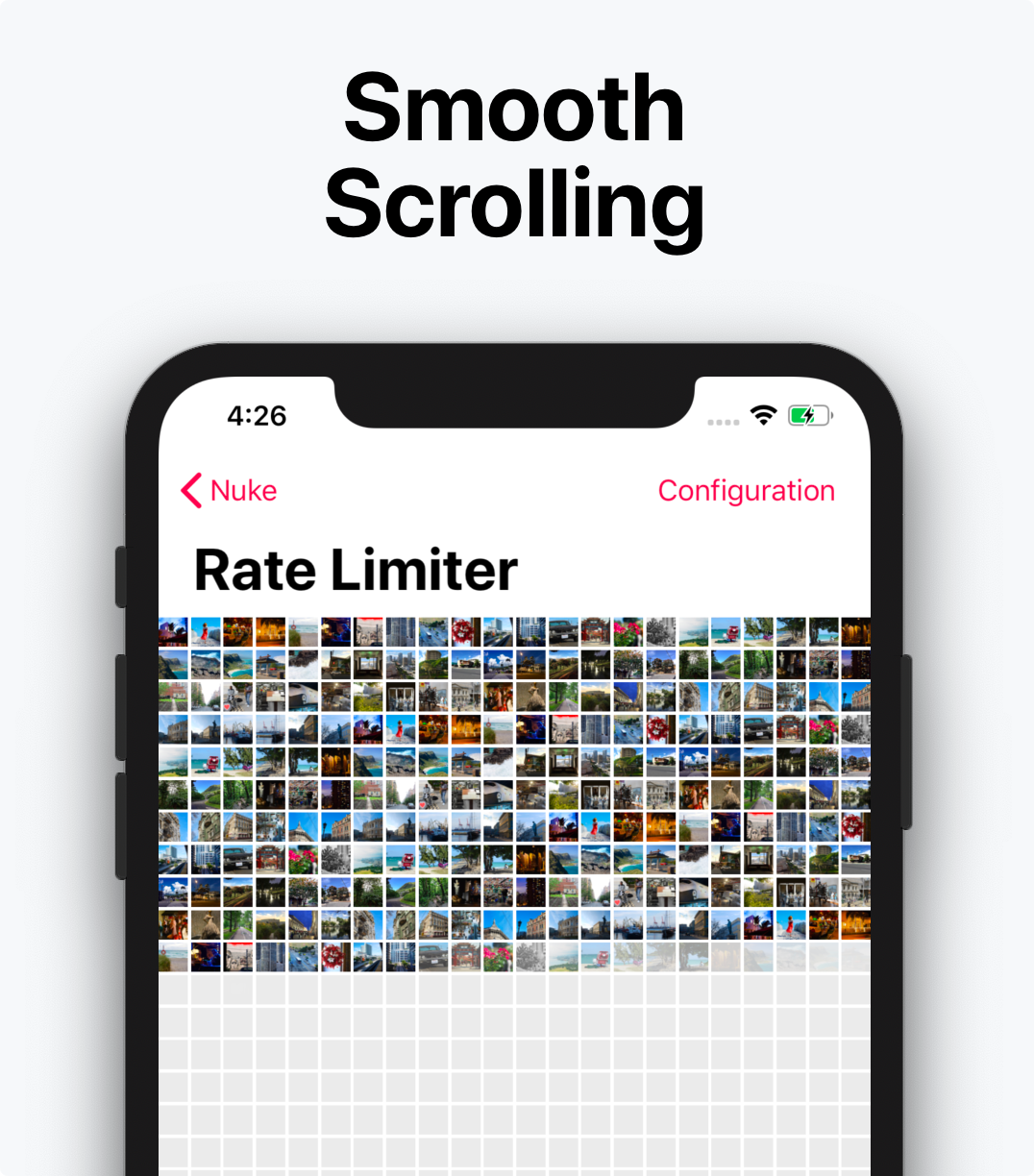
Nuke is tuned to do as little work on the main thread as possible. It uses multiple optimization techniques to achieve that: reducing the number of allocations, reducing dynamic dispatch, CoW, etc.
Nuke is fully asynchronous and performs well under stress. ImagePipeline schedules its operations on dedicated queues. Each queue limits the number of concurrent tasks, respects the request priorities, and cancels the work as soon as possible. Under the extreme load, ImagePipeline will also rate limit the requests to prevent saturation of the underlying systems.
If you want to see how the system behaves, how long each operation takes, and how many are performed in parallel, enable the isSignpostLoggingEnabled option and use the os_signpost Instrument. For more information see Apple Documentation: Logging and WWDC 2018: Measuring Performance Using Logging.
There is a variety of extensions available for Nuke:
| Name | Description |
|---|---|
| RxNuke | RxSwift extensions for Nuke with examples of common use cases solved by Rx |
| Alamofire | Replace networking layer with Alamofire and combine the power of both frameworks |
| WebP | [Community] WebP support, built by Ryo Kosuge |
| Gifu | Use Gifu to load and display animated GIFs |
| FLAnimatedImage | Use FLAnimatedImage to load and display animated GIFs |
Nuke's roadmap is managed in Trello and is publically available. If you'd like to contribute, please feel free to create a PR.
| Nuke | Swift | Xcode | Platforms |
|---|---|---|---|
| Nuke 8 | Swift 5.0 | Xcode 10.2 | iOS 10.0 / watchOS 3.0 / macOS 10.12 / tvOS 10.0 |
| Nuke 7.6 – 7.6.3 | Swift 4.2 – 5.0 | Xcode 10.1 – 10.2 | iOS 10.0 / watchOS 3.0 / macOS 10.12 / tvOS 10.0 |
| Nuke 7.2 – 7.5.2 | Swift 4.0 – 4.2 | Xcode 9.2 – 10.1 | iOS 9.0 / watchOS 2.0 / macOS 10.10 / tvOS 9.0 |
Nuke is available under the MIT license. See the LICENSE file for more info.