This dataset is a heavily obfuscated (due to binning and pseudonym usage for virtually all variables) customer history dataset in which vehicle appraisals and purchases are paired by customer provided by CarMax for their 2023 analytics showcase (this modeling was performed after/independently from the showcase competition and seeks to answer a different question involving predicting used car prices). Despite the obfuscation these are real data and they have a substantial amount of mising data (~1/3 of rows missing at least one variable).
I performed a limited form of iterative multiple imputation of multiple variables by seeding missing values with categoricaly (typically vehicle model) modes/means and then performing a final iterative pass using regression based methods. Based on test/train splits these methods typically have high performance (i.e. R^2 between .7-.9) for each variable.
Next, I optimize two decision tree regressors (one for appraisals one for purchases) by grid search. After exploring the impact of each parameter on the individual decision tree, I use these results to perform grid searches for random forest regressors. In the end, the random forest models prevail by a slight margin.
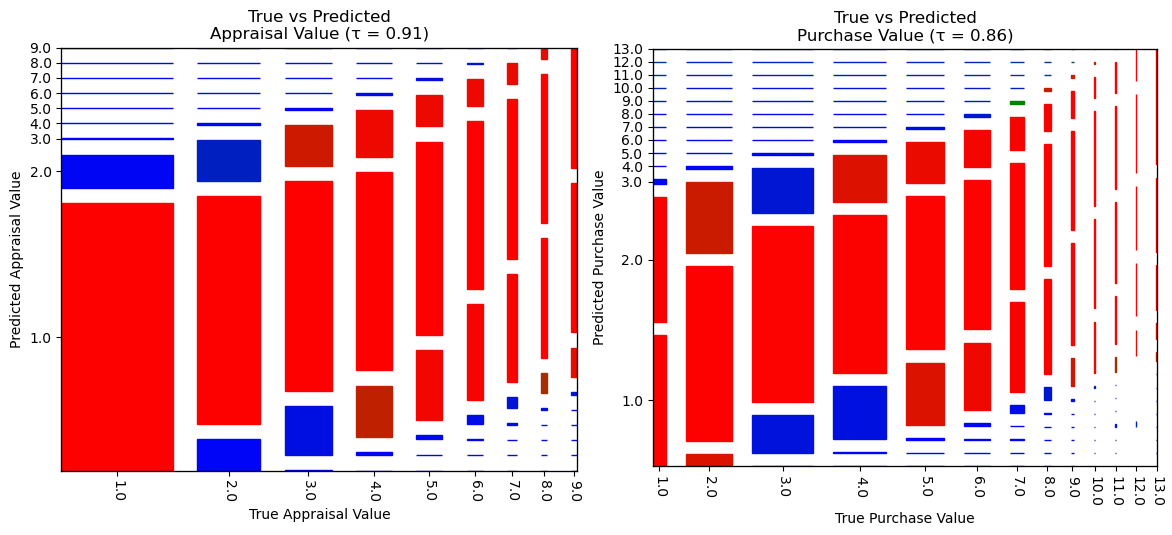
Overall, after rounding (for ordinal outputs) and combing appraisal and purchase records, R^2 is 0.91, with a concordance index of 0.95, meaning the model predicts true car values with a high degree of accuracy (and when it is wrong it usually is in the correct overall direction relative to the average). Perhaps an even better and (in this case stricter) measure of performance, Kendall's Tau (for ordinal correlation) still produces a value of 0.89 with a p-value of approx 0 (beyond floating point precision).
There are 4 parts, Pat 1 is just EDA, Part 2 is imputation, Part 2 is exploring the results of the decision tree grid search (model_optimizer.py generates the outputs, see python model_optimizer.py --help for more info), part 3 is exploring the test performance of the decision tree and random forest models.
Raw and all intermediate data (including fitted models) are available on Google Drive.