Sistem rekomendasi movie merupakan sistem yang merekomendasikan movie kepada penonton atau pengguna lainnya, rekomendasi ini contohnya diterapkan pada situs seperti netflix, iqiyi, dan wetv. Sistem rekomendasi yang saya buat ini didasarkan dengan peferensi kesukaan pengguna pada masa lalu, serta rating dari movie tersebut.
Sistem rekomendasi telah menjadi lazim dalam beberapa tahun terakhir karena mereka menangani masalah kelebihan informasi dengan menyarankan pengguna produk yang paling relevan dari sejumlah besar data. Untuk produk media, rekomendasi film kolaboratif online berupaya membantu pengguna mengakses film pilihan mereka dengan menangkap tetangga yang persis sama di antara pengguna atau film dari peringkat umum historis mereka. Namun, karena data yang jarang, pemilihan tetangga menjadi lebih sulit dengan meningkatnya film dan pengguna dengan cepat.
referensi dari proyek overview yang saya buat dapat dilihat dari tautan berikut : Journal of Visual Languages & Computing
Bagaimana cara merekomendasikan movie yang disukai pengguna lain dapat direkomendasikan kepada pengguna lainnya juga ?
Dapat membuat sistem rekomendasi yang akurat berdasarkan ratings dan aktivitas pengguna pada masa lalu.
Solusi yang saya buat yaitu dengan menggunakan 2 algoritma Machine Learning sistem rekomendasi,yaitu :
- Content Based Filtering adalah algoritma yang merekomendasikan item serupa dengan apa yang disukai pengguna, berdasarkan tindakan mereka sebelumnya atau umpan balik eksplisit.
- Collaborative Filtering. adalah algoritma yang bergantung pada pendapat komunitas pengguna. Dia tidak memerlukan atribut untuk setiap itemnya.
Algoritma Content Based Filtering digunakan untuk merekemondesikan movie berdasarkan aktivitas pengguna pada masa lalu, sedangkan algoritma Collabarative Filltering digunakan untuk merekomendasikan movie berdasarkan ratings yang paling tinggi.
Data atau dataset yang digunakan pada proyek machine learning ini adalah data Movie Recommendation Data yang didapat dari situs kaggle. Link dataset dapat dilihat dari tautan berikut movie-recommendation-data
Variabel-variabel pada movie-recommendation-data adalah sebagai berikut :
- links : merupakan daftar link movie tersebut.
- movies : merupakan daftar movie yang tersedia.
- ratings : merupakan daftar penilaian yang diberikan pengguna terhadap movie.
- tags : merupakan daftar kata kunci dari movie tersebut.
tahapan yang dilakukan mengenai data adalah dengan melakukan exploratory data analysis, yaitu dengan melihat-lihat hubungan antar variabel bersarkan id. Serta menggabungkan seluruh variabel movie_all berdasarkan movieId dan variabel user_all berdasarkan userId
Data preparation yang digunakan oleh saya yaitu :
- Mengatasi missing value : menyeleksi data apakah data tersebut ada yang kosong atau tidak, jika ada data kosong maka saya akan.menghapusnya
- Membagi data menjadi data training dan validasi : untuk membagi data untuk dilatih dan validasi.
- Menggabungkan variabel : untuk menggabungkan beberapa variabel berdasarkan id yang sifatnya unik (berbeda dari yang lain).
- Mengurutan data : untuk mengurutkan data berdasarkan movieId secara asceding.
- Mengatasi duplikasi data : untuk mengatasi data yang nilai atau isinya sama.
- Konversi data menjadi iist : untuk mengubah data menjadi list
- Membuat dictionary : Untuk membuat dictionary dari data yang ada.
- Menggunakan TfidfVectorizer : untuk melakukan pembobotan.
- melakukan preprocessing : untuk menghilangkan permasalahan-permasalahan yang dapat mengganggu hasil daripada proses data
- mapping data : untuk memetakan data
-
Proses modeling yang saya lakukan pada data ini adalah dengan membuat algoritma machine learning, yaitu content based filtering dan collabrative filtering. untuk algoritma content based filtering saya buat dengan apa yang disukai pengguna pada masa lalu, sedangkan untuk content based filtering, saya buat dengan memanfaatkan tingkat rating dari movie tersebut.
-
Berikut adalah hasil dari kedua algoritma tersebut :
-
hasil dari content based filtering
berikut adalah movie yang disukai pengguna dimasa lalu :

dari hasil di atas dapat dilihat bahwa pengguna menyukai movie yang berjudul jumanji (1995) yang bergenre Adventure, Children, Fantasy. maka hasil top 5 rekomendasi berdasarkan algoritma conten based filtering adalah sebagai berikut :
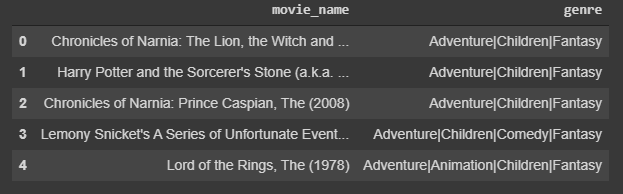
dari hasil di atas dapat dilihat bahwa movie yang bergenre antar Adventuyre, Children, dan Fantasy menjadi yang direkomendasikan oleh sistem. Hal ini didasarkan pada kesukaan penonton atau pengguna pada masa lalu. -
hasil dari collaborative content filtering
berikut adalah movie berdasarkan rating yang ada :
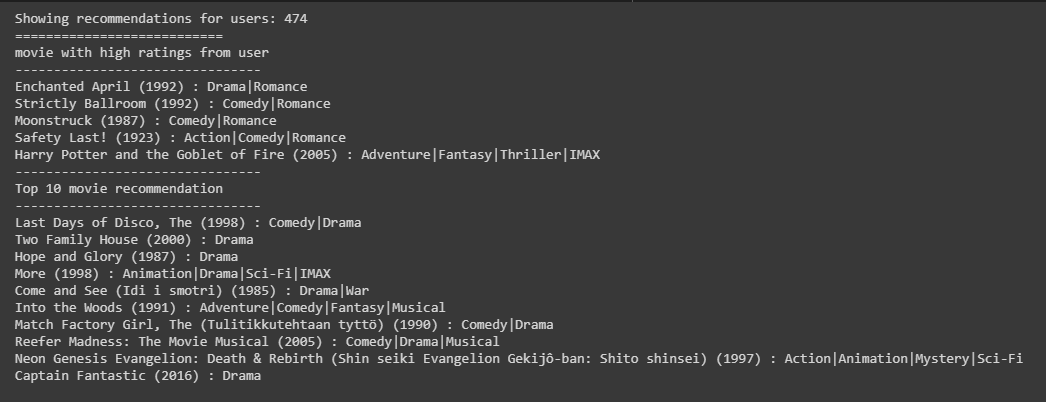
dari hasi di atas movie yang bergenre comedy menjadi movie yang paling tinggi ratingsnya. Kemudian top 10 movie yang direkomendasikan sistem adalah movie dengan genre comedy dan drama.
- hasil Evaluasi untuk Content Based Filtering
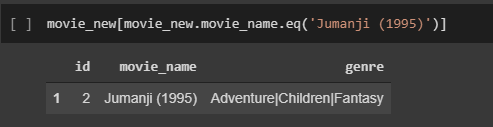
Disini saya merekomendasikan film Jumanji (1995)
hasil dari Top-N 5 dari film atau movie yang saya rekomendasikan adalah sebagai berikut :
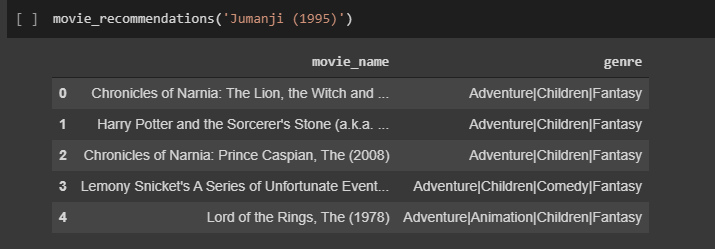
Dari hasil rekomendasi di atas, diketahui bahwa Jumanji (1995) termasuk ke dalam genre Adventure|Children|Fantasy. Dari 5 item yang direkomendasikan, 3 item memiliki genre Adventure|Children|Fantasy (similar). Artinya, precision sistem kita sebesar 3/5 atau 60%.
Teknik Evaluasi di atas adalah dengan menggunakan precission, rumus dari teknik ini adalah :
.png)
- hasil Evaluasi untuk Collaborative Filtering
Evaluasi metrik yang digunakan untuk mengukur kinerja model adalah metrik RMSE (Root Mean Squared Error).
-
RMSE adalah metode pengukuran dengan mengukur perbedaan nilai dari prediksi sebuah model sebagai estimasi atas nilai yang diobservasi. Root Mean Square Error adalah hasil dari akar kuadrat Mean Square Error. Keakuratan metode estimasi kesalahan pengukuran ditandai dengan adanya nilai RMSE yang kecil. Metode estimasi yang mempunyai Root Mean Square Error (RMSE) lebih kecil dikatakan lebih akurat daripada metode estimasi yang mempunyai Root Mean Square Error (RMSE) lebih besar
-
Kelebihan dan kekurang matriks ini adalah :
kelebihan : menghukum kesalahan besar lebih sehingga bisa lebih tepat dalam beberapa kasus.
Kekurangan : memberikan bobot yang relatif tinggi untuk kesalahan besar. Ini berarti RMSE harus lebih berguna ketika kesalahan besar sangat tidak diinginkan -
formula dari matriks RMSE adalah sebagai berikut
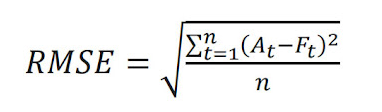
keterangan :
At : Nilai Aktual.
ft = Nilai hasil peramalan.
N = banyaknya dataset
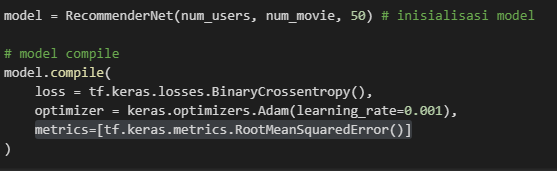
cara menerapkan metrik tersebut adalah dengan menambahkan 'metrics=[tf.keras.metrics.RootMeanSquaredError()]' pada model.compile sehingga menjadi seperti berikut :
hasil dari model evaluasi visualisasi matriks adalah sebagai berikut :
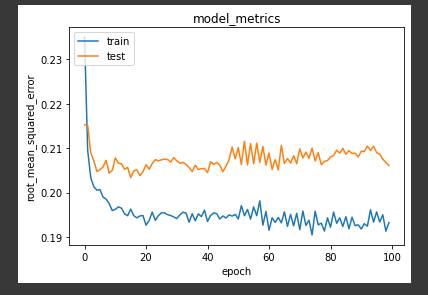
dari visualisasi proses training model di atas cukup smooth dan model konvergen pada epochs sekitar 100. Dari proses ini, saya memperoleh nilai error akhir sebesar sekitar 0.19 dan error pada data validasi sebesar 0.20.
---Ini adalah bagian akhir laporan---