

OpenWit is a high-performance, distributed observability data platform designed to ingest, store, and query telemetry data (traces, logs, metrics) at scale. Built in Rust, it provides a robust microservices architecture with specialized node types for different aspects of data processing.
OpenWit uses a microservices architecture with specialized node types that work together to provide a complete observability solution:
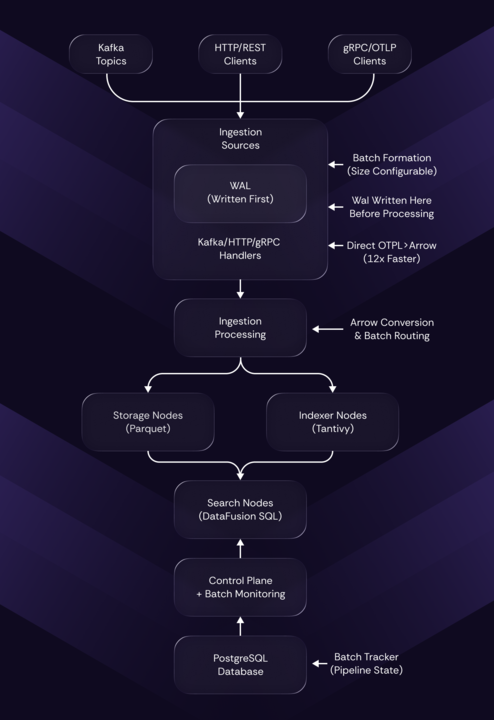
- Manages cluster state and coordinates all nodes
- Tracks batch processing status across the pipeline
- Performs health monitoring and leader election
- Handles service discovery for dynamic node registration
- Receives incoming data from multiple sources
- Health-aware routing to healthy backend nodes
- Round-robin load balancing
- No buffering - pure pass-through proxy
- Data Reception: Kafka consumer groups, gRPC OTLP, HTTP endpoints
- Multi-threaded Buffering: Thread-safe buffers with automatic batch formation
- WAL: Write-ahead logging for crash recovery
- Batch Router: Converts to Arrow format and routes to storage/indexer nodes
- LSM-Tree Architecture: Efficient write-optimized storage
- Parquet Files: Columnar storage with active/stable file pattern
- Client-based Organization: Multi-tenant data isolation
- Tiered Storage: Electric (memory), Hot (SSD), Cold (cloud), Archive tiers
- Full-text Indexing: Tantivy-based text search
- Columnar Indexes: Bitmap indexes and bloom filters
- Index Compaction: Automatic optimization for query performance
- SQL Query Processing: Full SQL support for data queries
- Distributed Execution: DataFusion for local, Ballista for distributed queries
- Smart Routing: Pushes filters to storage nodes for efficiency
- WAL ensures no data loss
- Health monitoring and automatic failover
- Gossip protocol for node discovery
- Control plane tracks and remediates stuck batches
- Multi-threaded processing pipelines
- Zero-copy Arrow format for data transfer
- Efficient batching reduces overhead
- Parallel processing paths (storage + indexing)
- Horizontal scaling of each node type
- Partitioned data processing
- Distributed query execution
- Cloud storage for infinite capacity
- Client/tenant isolation at storage level
- Separate parquet files per client
- Query filtering by client
- Resource limits per tenant (configurable)
-
Kafka Message Arrives:
Topic: v6.qtw.traces.kbuin.0 Payload: OTLP trace data -
Proxy Routes to Ingestion:
- Health check finds healthy ingestion nodes
- Round-robin selection for load balancing
-
Ingestion Processing:
- Write to WAL for durability
- Buffer messages until batch threshold
- Extract client/tenant from topic
- Form batches (50k messages or 10s timeout)
-
Batch Distribution:
- Convert to Arrow RecordBatch format
- Add metadata for routing
- Parallel send to storage and indexer nodes
-
Storage Processing:
- Add to client-specific memtable
- Write to parquet files
- Hourly rotation with cloud upload
- Path:
parquet/{client}/{year}/{month}/{day}/{node_id}/{filename}
-
Query Execution:
- Parse SQL query
- Create distributed query plan
- Execute on relevant nodes
- Merge and return results
- Full operator support
- Horizontal pod autoscaling
- Service mesh integration
- Persistent volume management
- Development and testing
- Pre-configured networking
- Volume mounts for data persistence
- All components in single process
- Ideal for development/testing
- Reduced resource overhead
- Edge deployments
- Single-node installations
- Minimal dependencies
- Prometheus-compatible metrics
- Per-component health endpoints
- Batch processing statistics
- Resource utilization tracking
- Unified YAML configuration
- Hot-reloadable settings
- Environment-specific overrides
- Safe mode for gradual rollouts
- REST API for administration
- CLI tools for operations
- Automated maintenance tasks
- Built-in diagnostics
- Language: Rust (performance and safety)
- Data Format: Apache Arrow (columnar processing)
- Storage Format: Apache Parquet (compressed columnar)
- Query Engine: DataFusion + Ballista
- Indexing: Tantivy (Lucene-like)
- Protocols: gRPC, HTTP/2, Arrow Flight
- Cloud Support: Azure, AWS S3, Google Cloud Storage
- Application Performance Monitoring: Collect and analyze application traces
- Log Aggregation: Centralized logging with full-text search
- Metrics Collection: Time-series data storage and querying
- Distributed Tracing: End-to-end request tracking
- Real-time Analytics: Low-latency data processing and querying
- Rust 1.70+ (for building from source)
- Docker & Docker Compose (for containerized deployment)
- Kubernetes 1.24+ (for production deployment)
# Clone the repository
git clone https://github.com/yourusername/openwit.git
cd openwit
# Build the project
cargo build --release
# Run with sample configuration
./target/release/openwit-cli --config config/openwit-unified-control.yaml# Start all services
docker-compose up -d
# Check service health
docker-compose ps
# View logs
docker-compose logs -f ingestionWe welcome contributions! Please see our Contributing Guide for details on:
- Code style and standards
- Testing requirements
- Pull request process
- Issue reporting
OpenWit is licensed under the Apache License 2.0.
Built with ❤️ by the OpenWit team