June 2023
tl;dr: A massive multitask multimodal LLM that can perform 604 multi-embodiment tasks as language modeling.
Gato is a generalist model with a single neural network with the same set of weights to perform a massive number of tasks. It can output text, joint torques, button presses and other tokens. --> This is maybe what is used by Tesla's TeslaBot which maps images to joint angles.
Gato significantly scales up behavior cloning (BC) with data, compute and model parameters. BC can also be framed as a sequence modeling problem with natural language as a common grounding across otherwise incompatible embodiments.. It is NOT trained with offline or online RL. Gato reduces the need for handcrafting policy models with appropriate inductive biases for each domain.
LLM training is always open-loop, and inference is always close-loop.
The tricks in tokenization and details in Appendix B and Appendix C are super useful and is perhaps the greatest contribution of this paper.
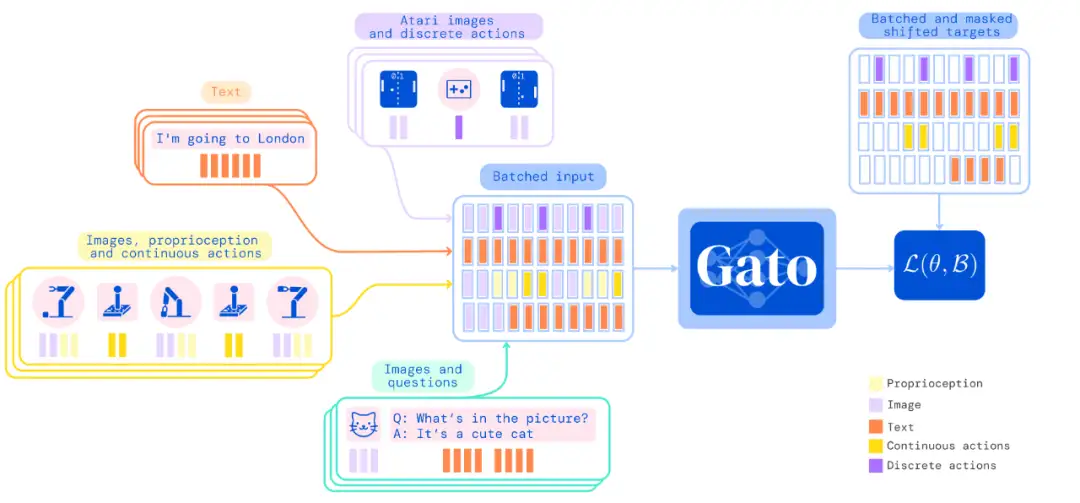
- Model IO
- Input: text, image, proprioception (joint torque, etc), actions
- Output: text, actions
- Summary: a wide range of discrete and continuous observations and actions
- Architecture
- Parmeterized embedding function, transforming tokens to token embedding
- Sequence model putputs a distribution over the next discrete token
- 1.2B parameter decoder-only transformer
- Input construction: Tokenization, sequence construction, embedding
- Training
- data from different tasks and modalities is serialized into a seq of tokens, batched and processed by a LLM.
- This is similar to the "data mixing" approach where each batch is multi-task in pix2seq v2.
- Tokenization
- There are infinite ways to transform data into tokens, including directly using the raw underlying byte stream. --> Not necessarily DL model friendly though. Essentially this is to say, anything you can serialize and store on a computer as a file, you can tokenize it and construct a sequence. This is actually the idea of Bytes Are All You Need: Transformers Operating Directly On File Bytes from Apple.
- Text: with SentencePiece which implements BPE (byte pair encoding), with a vocab size of 32000
- Image: 16x16 patches
- Discrete values: e.g. button presses, are flattened into seq of integers, within the range of [0, 1024]
- Continuous values: float numbers are mu-law encoded encoded to [-1, 1] then discretized to 1024 bins. --> See a simplified quantization scheme in DORN. This mu-law scaling is also used in WaveNet by DeepMind.
- Sequence ordering
- text token: same as raw input text
- image patch tokens in raster order
- tensor: row-major order
- nested structure: lexicographical order by key
- agent timestamp as observation tokens, followed by a
septoken, then action token - agent episodes as time-steps in time order
- Embedding
- Tokens belonging to text, continuous or discrete values are embedded via a lookup table into a learned vector embedding space. --> One integer is lifted to n-D space.
- Image tokens: resNet based, token per 16x16 patch, with within-image postion encoding.
- Prompt conditioning: sequences near the end of the episode is sampled with favor, as a form of goal conditioning.
- Data for RL tasks (simulated control tasks)
- for RL tasks, the data is obtained from SOTA or near-SOTA pre-trained RL agents
- Better to use filtered set of episodes with more returns (更专业的老司机)
- Batch x seq = 512 x 1024.
- Sampling with diff temperature at inference time will generate
- Proprioception: sensor measurements from robotics.
- Mask is used so that loss is only applied to outputs, text and actions.
- The paper also evaluated the generalization capability of Gato. One major takeaway is that the large model need significantly smaller number of fine-tuning to reach expert. The larger the model, the easier to transfer and the higher the ceiling. --> Like human.
- Golpher (language), Chichilla (language), Flamingo (language, vision), Gato (language, vision, action)
- Interview with Oriol Vinyas by Lex
- Offline RL algorithm baseline: Critic Regularized Regression NeurIPS 2020
- Some interesting background from neural science.
“Single-brain”-style models have interesting connections to neuroscience. Mountcastle (1978) famously stated that “the processing function of neocortical modules is qualitatively similar in all neocortical regions. Put shortly, there is nothing intrinsically motor about the motor cortex, nor sensory about the sensory cortex”. Mountcastle found that columns of neurons in the cortex behave similarly whether associated with vision, hearing or motor control. This has motivated arguments that we may only need one algorithm or model to build intelligence (Hawkins & Blakeslee, 2004).
Sensory substitution provides another argument for a single model (Bach-y Rita & Kercel, 2003). For example, it is possible to build tactile visual aids for blind people as follows. The signal captured by a camera can be sent via an electrode array on the tongue to the brain. The visual cortex learns to process and interpret these tactile signals, endowing the person with some form of “vision”. Suggesting that, no matter the type of input signal, the same network can process it to useful effect.